Original Link: https://www.anandtech.com/show/14873/reaching-for-turbo-aligning-perception-with-amds-frequency-metrics-
Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
by Dr. Ian Cutress on September 17, 2019 10:00 AM EST
For those that keep a close eye on consumer hardware, AMD recently has been involved in a minor uproar with some of its most vocal advocates about the newest Ryzen 3000 processors. Some users are reporting turbo frequencies much lower than advertised, and a number of conflicting AMD partner posts have generated a good deal of confusion. AMD has since posted an update identifying an issue and offering a fix, but part of all of this comes down to what turbo means and how AMD processors differ from Intel. We’ve been living on Intel’s definitions of perceived standards for over a decade, so it’s a hard nut to crack if everyone assumes there can be no deviation from what we’re used to. In this article, we’re diving at those perceived norms, to shed some light on how these processors work.
A Bit of Context
Since the launch of Zen 2 and the Ryzen 3000 series, depending on which media outlet you talk to, there has been a peak turbo issue with the new hardware. This turbo frequency issue has been permeating in the ecosystem since Zen 2 was launched, with popular outlets like Gamers Nexus noting that on certain chips, the advertised turbo frequency was only achieved under extreme cooling conditions. For other outlets, being within 50 MHz of the peak turbo frequency has been considered chip-to-chip variation, or a function of early beta firmware. A wide array of people put varying amounts of weight behind this, from conspiracy to not being bothered about it at all.
However, given recent articles by some press, as well as some excellent write-ups by Paul Alcorn over at Tom’s Hardware*, we saw that the assumed public definitions of processor performance actually differs from Intel to AMD. What we used as the default standard definitions, which are based on Intel’s definitions, are not the same under AMD, which is confusing everyone. No one likes a change to the status quo, and even with articles out there offering a great breakdown of what's going on, a lot of the general enthusiast base is still trying to catch up to all of the changes.
This confusion – and the turbo frequency discussion in general – were then brought to the fore of news in the beginning of September 2019. AMD, in a two week span, had several things happen essentially all at once.
- Popular YouTuber der8aur performed a public poll of frequency reporting that had AMD in a very bad light, with some users over 200 MHz down on turbo frequency,
- The company settled for $12.1m in a lawsuit about marketing Bulldozer CPUs,
- Intel made some seriously scathing remarks about AMD performance at a trade show,
- AMD’s Enterprise marketing being comically unaware of how its materials would be interpreted.
Combined with all of the drama that the computing industry can be known for – and the desire for an immediate explanation, even before the full facts were in – made for a historically bad week for AMD. Of course, we’ve reported on some of these issues, such as the lawsuit because they are interesting factoids to share. Others we ignored, such as (4) for a failure to see anything other than an honest mistake given how we know the individuals behind the issues, or the fact that we didn’t report on (3) because it just wasn’t worth drawing attention to it.
What has driven the discussion about peak turbo has come to head because of (1). Der8auer’s public poll, taken from a variety of users with different chips, different motherboards, different cooling solutions, different BIOS versions, still showed a real-world use case of fewer than 6% of 3900X users were able to achieve AMD’s advertised turbo frequency. Any way you slice it, without context, that number sounds bad.
Meanwhile, in between this data coming out and AMD’s eventual response, a couple of contextual discrepancies happened between AMD’s partner employees and experts in the field via forum posts. This greatly exacerbated the issue, particularly among the vocal members of the community. We’ll go into detail on those later.
AMD’s response, on September 10th, was a new version of its firmware, called AGESA 1003-ABBA. This was released along with blog post that detailed that a minor firmware issue was showing 25-50 MHz drop in turbo frequency was now fixed.
Naturally, that doesn’t help users who are down 300 MHz, but it does come down to how much the user understands how AMD’s hardware works. This article is designed to shed some light on the timeline here, as well as how to understand a few nuances of AMD's turbo tech, which are different to what the public has come to understand from Intel’s use of specific terms over the last decade.
*Paul’s articles on this topic are well worth a read:
Ryzen 3000, Not All Cores Are Created Equal
Investigating Intel’s Claims About Ryzen Reliability
Testing the Ryzen 3000 Boost BIOS Fix

This Article
In this article we will cover:
- Intel’s Definition of Turbo
- AMD’s Definition of Turbo
- Why AMD is Binning Differently to Intel, relating to Turbo and OC
- A Timeline of AMD’s Ryzen 3000 Turbo Reporting
- How to Even Detect Turbo Frequencies
- AMD's Fix
Defining Turbo, Intel Style
Since 2008, mainstream multi-core x86 processors have come to the market with this notion of ‘turbo’. Turbo allows the processor, where plausible and depending on the design rules, to increase its frequency beyond the number listed on the box. There are tradeoffs, such as Turbo may only work for a limited number of cores, or increased power consumption / decreased efficiency, but ultimately the original goal of Turbo is to offer increased throughput within specifications, and only for limited time periods. With Turbo, users could extract more performance within the physical limits of the silicon as sold.
In the beginning, Turbo was basic. When an operating system requested peak performance from a processor, it would increase the frequency and voltage along a curve within the processor power, current, and thermal limits, or until it hit some other limitation, such as a predefined Turbo frequency look-up table. As Turbo has become more sophisticated, other elements of the design come into play: sustained power, peak power, core count, loaded core count, instruction set, and a system designer’s ability to allow for increased power draw. One laudable goal here was to allow component manufacturers the ability to differentiate their product with better power delivery and tweaked firmwares to give higher performance.
For the last 10 years, we have lived with Intel’s definition of Turbo (or Turbo Boost 2.0, technically) as the defacto understanding of what Turbo is meant to mean. Under this scheme, a processor has a sustained power level, and peak power level, a power budget, and assuming budget is available, the processor will go to a Turbo frequency based on what instructions are being run and how many cores are active. That Turbo frequency is governed by a Turbo table.
The Turbo We All Understand: Intel Turbo
So, for example. I have a hypothetical processor that has a sustained power level (PL1) of 100W. The peak power level (PL2) is 150W*. The budget for this turbo (Tau) is 20 seconds, or the equivalent of 1000 joules of energy (20*(150-100)), which is replenished at a rate of 50 joules per second. This quad core CPU has a base frequency of 3.0 GHz, but offers a single core turbo of 4.0 GHz, and 2-core to 4-core of 3.5 GHz.
So tabulated, our hypothetical processor gets these values:
| Sustained Power Level | PL1 / TDP | 100 W |
| Peak Power Level | PL2 | 150 W |
| Turbo Window* | Tau | 20 s |
| Total Power Budget* | (150-100) * 20 | 1000 J |
| *Turbo Window (and Total Power Budget) is typically defined for a given workload complexity, where 100% is a total power virus. Normally this value is around 95% | ||
*Intel provides ‘suggested’ PL2 values and ‘suggested’ Tau values to motherboard manufacturers. But ultimately these can be changed by the manufacturers – Intel allows their partners to adjust these values without breaking warranty. Intel believes that its manufacturing partners can differentiate their systems with power delivery and other features to allow a fully configurable value of PL2 and Tau. Intel sometimes works with its partners to find the best values. But the take away message about PL2 and Tau is that they are system dependent. You can read more about this in our interview with Intel’s Guy Therien.
Now please note that a workload, even a single thread workload, can be ‘light’ or it can be ‘heavy’. If I created a piece of software that was a never ending while(true) loop with no operations, then the workload would be ‘light’ on the core and not stressing all the parts of the core. A heavy workload might involve trigonometric functions, or some level of instruction-level parallelism that causes more of the core to run at the same time. A ‘heavy’ workload therefore draws more power, even though it is still contained with a single thread.
If I run a light workload that requires a single thread, it will start the processor at 4.0 GHz. If the power of that single thread is below 100W, then I will use none of my budget, as it is refilled immediately. If I then switch to a heavy workload, and the core now consumes 110W, then my 1000 joules of turbo budget would decrease by 10 joules every second. In effect, I would get 100 seconds of turbo on this workload, and when the budget is depleted, the sustained power level (PL1) would kick in and reduce the frequency to ensure that the consumption on the chip stayed at 100W. My budget of energy for turbo would not increase, because the 100 joules/second that is being added is immediately taken away by the heavy workload. This frequency may not be the 3.0 GHz base frequency – it depends on the voltage/power characteristics of the individual chip. That 3.0 GHz base value is the value that Intel guarantees on its hardware – so every one of this hypothetical processor will be a minimum of 3.0 GHz at 100W on a sustained workload.
To clarify, Intel does not guarantee any turbo speed that is part of the specification sheet.
Now with a multithreaded workload, the same thing occurs, but you are more likely to hit both the peak power level (PL2) of 150W, and the 1000 joules of budget will disappear in the 20 seconds listed in the firmware. If the chip, with a 4-core heavy workload, hits the 150W value, the frequency will be decreased to maintain 150W – so as a result we may end up with less than the ‘3.5 GHz’ four-core turbo that was listed on the box, despite being in turbo.
So when a workload is what we call ‘bursty’, with periods of heavy and light work, the turbo budget may be refilled quicker than it is used in light workloads, allowing for more turbo when the workload gets heavy again. This makes it important when benchmarking software one after another – the first run will always have the full turbo budget, but if subsequent runs do not allow the budget to refill, it may get less turbo.
As stated, that turbo power level (PL2) and power budget time (Tau) are configurable by the motherboard manufacturer. We see that on enterprise motherboards, companies often stick to Intel’s recommended settings, but with consumer overclocking motherboards, the turbo power might be 2x-5x higher, and the power budget time might be essentially infinite, allowing for turbo to remain. The manufacturer can do this if they can guarantee that the power delivery to the processor, and the thermal solution, are suitable.
(It should be noted that Intel actually uses a weighted algorithm for its budget calculations, rather than the simplistic view I’ve given here. That means that the data from 2 seconds ago is weighted more than the data from 10 seconds ago when determining how much power budget is left. However, when the power budget time is essentially infinite, as how most consumer motherboards are set today, it doesn’t particularly matter either way given that the CPUs will turbo all the time.)
Ultimately, Intel uses what are called ‘Turbo Tables’ to govern the peak frequency for any given number of cores that are loaded. These tables assume that the processor is under the PL2 value, and there is turbo budget available. For example, here are Intel’s turbo tables for Intel’s 8th Generation Coffee Lake desktop CPUs.
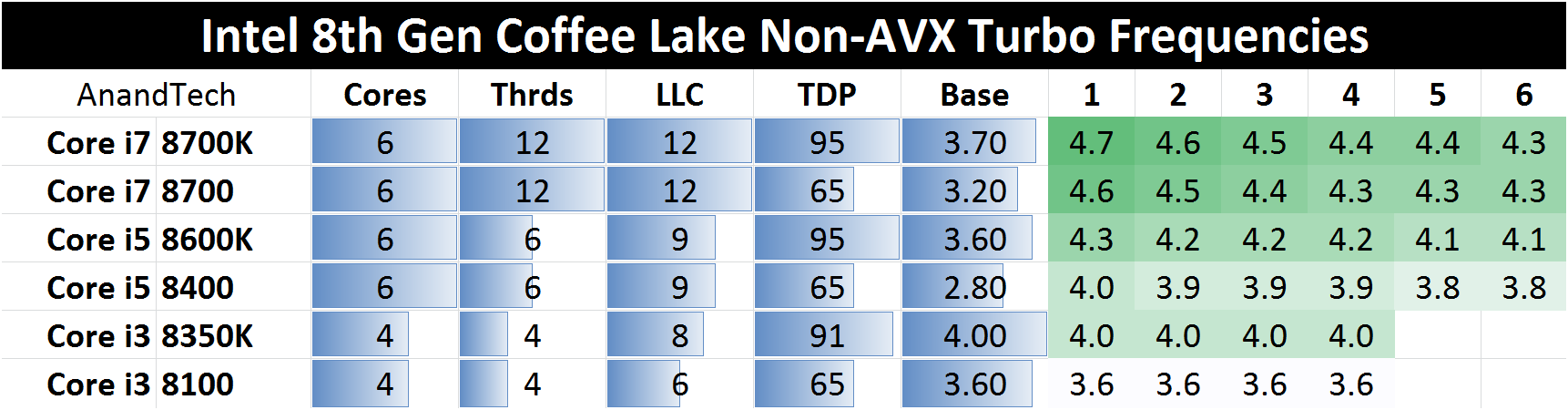
So Intel provides the sustained power level (PL1, or TDP), the Base frequency (3.70 GHz for the Core i7-8700K), and a range of turbo frequencies based on the core loading, assuming the motherboard manufacturer set PL2 isn’t hit and power budget is available.
The Effect of Intel’s Turbo Regime, and Intel’s Binning
At the time, Intel did a good job in conveying its turbo strategy to the press. It helped that staying on quad-core processors for several generations meant that the actual turbo power consumption of these quad-core chips was actually lower than sustained power value, and so we had a false sense of security that turbo could go on forever. With the benefit of hindsight, the nuances relating to turbo power limits and power budgets were obfuscated, and people ultimately didn’t care on the desktop – all the turbo for all the time was an easy concept to understand.
One other key metric that perhaps went under the radar is how Intel was able to apply its turbo frequencies to the CPU.
For any given CPU, any core within that design could hit the top turbo. It allowed for threads to be loaded onto whatever core was necessary, without the need to micromanage the best thread positioning for the best performance. If Intel stated that the single core turbo frequency was 4.6 GHz, then any core could go up to 4.6 GHz, even if each individual core could go beyond that.
For example, here’s a theoretical six-core Core i5-9600K, with a 3.7 GHz base frequency, and a 4.6 GHz turbo frequency. The higher numbers represent theoretical maximums of each core at the turbo voltage.
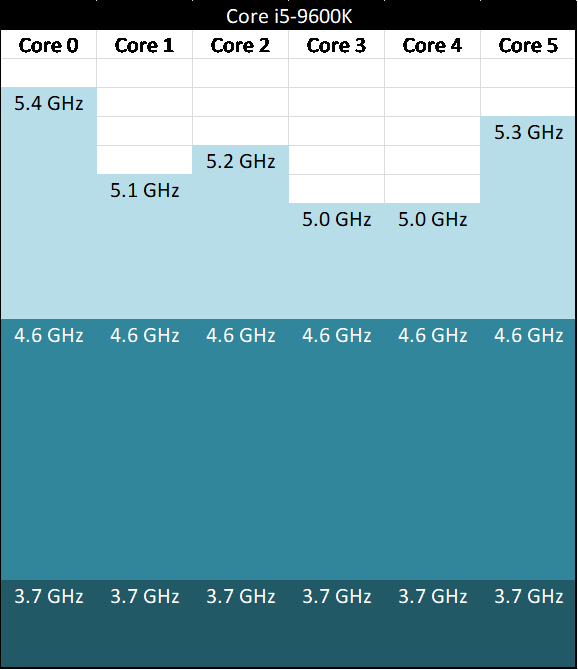
This is actually a strategy related to how Intel segments its CPUs after manufacturing, a process called binning. If a processor has the right power/thermal characteristics to reach a given frequency in a given power, then it could be labelled as the most appropriate CPU for retail and sold as such. Because Intel aimed for a homogeneous monolithic design, every core in the design was tested such that it performed equally (or almost equally) with every other core. Invariably some cores will perform better than others, if tweaked to the limits, but under Intel’s regime, it helped Intel to spread the workloads around as to not create thermal hotspots on the processor, and also level out any wear and tear that might be caused over the lifetime of the product. It also meant that in a hypervisor, every virtual machine could experience the same peak frequencies, regardless of the cores they used.
With binning, Intel (or any other company), is selecting a set of voltages and frequencies for a processor to which it is guaranteed. From the manufacturing, Intel (or others) can see the predicted lifespan of a given processor for a range of frequencies and voltages, and the ones that hit the right mark (based on internal requirements) means that a silicon chip ends up as a certain CPU. For example, if a piece of silicon does hit 9900K voltages and frequencies, but the lifespan rating of that piece of silicon is only two years, Intel might knock it down to a 9700K, which gives a predicted lifespan of fifteen years. It’s that sort of thing that determines how high a chip can perform. Obviously chips that can achieve high targets can also be reclassified as slower parts based on inventory levels or demand.
This is how the general public, the enthusiasts, and even the journalists and reviewers covering the market, have viewed Turbo for a long time. It’s a well-known part of the desktop space and to a large extent is easy to understand. If someone said ‘Turbo’ frequency, everyone was agreed on the same basic principles and no explanation was needed. We all assumed that when Turbo was mentioned, this is what they meant, and this is what it would mean for eternity.
Now insert AMD, March 2017, with its new Zen core microarchitecture. Everyone assumed Turbo would work in exactly the same way. It does not.
AMD’s Turbo
With AMD introducing Turbo after Intel, as has often been the case in their history, they've had to live in Intel's world. And this has repercussions for the company.
By the time AMD introduced their first Turbo-enabled processors, everyone in the desktop space ‘knew’ what Turbo meant, because we had gotten used to how Intel did things. For everyone, saying ‘Turbo’ meant only one thing: Intel’s definition of Turbo, which we subconsciously took as the default, and that’s all that mattered. Every time an Intel processor family is released, we ask for the Turbo tables, and life is good and easy.
Enter AMD, and Zen. Despite AMD making it clear that Turbo doesn’t work the same way, the message wasn’t pushed home. AMD had a lot of things to talk about with the new Zen core, and Turbo, while important, wasn’t as important as the core performance messaging. Certain parts of how the increased performance were understood, however the finer points were missed, with users (and press) assuming an Intel like arrangement, especially given that the Zen core layout kind of looks like an Intel core layout if you squint.
What needed to be pushed home was the sense of a finer grained control, and how the Ryzen chips respond and use this control.
When users look at an AMD processor, the company promotes three numbers: a base frequency, a turbo frequency, and the thermal design power (TDP). Sometimes an all-core turbo is provided. These processors do not have any form of turbo tables, and AMD states that the design is not engineered to decrease in frequency (and thus performance) when it detects instructions that could cause hot spots.
It should be made clear at this point that Zen (Ryzen 1000, Ryzen 2000) and Zen2 (Ryzen 3000) act very differently when it comes to turbo.
Turbo in Zen
At a base level, AMD’s Zen turbo was just a step function implementation, with two cores getting the higher turbo speed. However, most cores shipped with features that allowed the CPU to get higher-than-turbo frequencies depending on its power delivery and current delivery limitations.
You may remember this graph from the Ryzen 7 1800X launch:
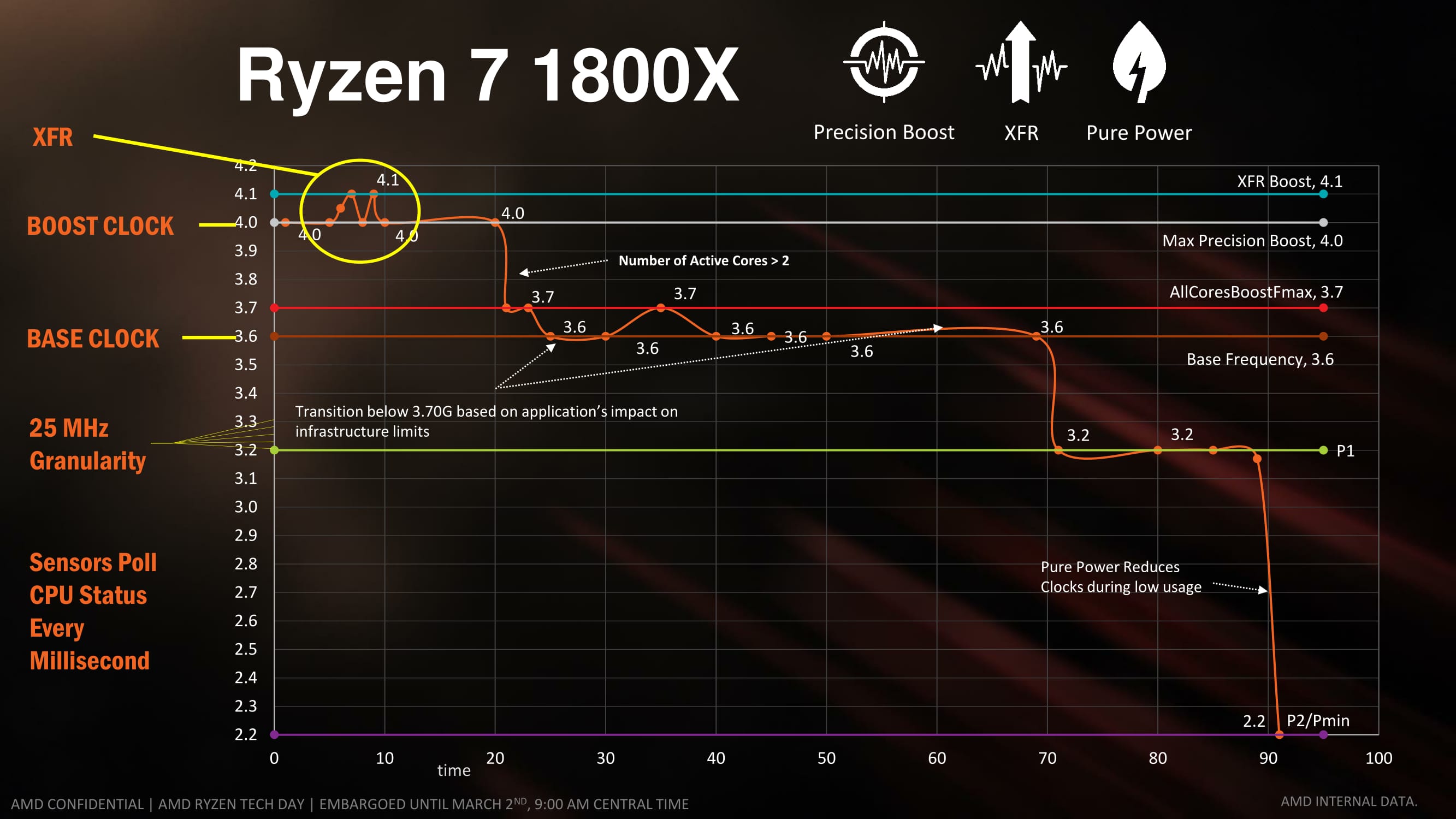
For Zen processors, AMD enabled a 0.25x multiplier increment, which allows the CPU to jump up in 25 MHz steps, rather than 100 MHz. This bit was easy to understand: it meant more flexibility in what the frequency could be at any given time. AMD also announced XFR, or ‘eXtreme Frequency Range’, which meant that with sufficient cooling and power headroom, the CPU could perform better than the rated turbo frequency in the box. Users that had access to a better cooling solution, or had lower ambient temperatures, would expect to see better frequencies, and better performance.
So the Ryzen 7 1800X was a CPU with a 3.6 GHz base frequency and a 4.0 GHz turbo frequency, which it achieves when 2 or fewer cores are active. If possible, the CPU will use the (now depreciated in later models) eXtended Frequency Range feature to go beyond 4.1 GHz if the conditions are correct (thermals, power, current). When more than two cores are active, the CPU drops down to its all-core boost, 3.7 GHz, and may transition down to 3.6 GHz depending on the conditions (thermals, power, current).
Turbo in Zen+, then Zen2
AMD dropped XFR from its marketing materials, tying it all under Precision Boost. Ultimately the boost function of the processor relied on three new metrics, alongside the regular thermal and total power consumption guidelines:
PPT: Socket Power Capacity
TDC: Sustained VRM Capacity
EDC: Peak/Transient VRM Capacity
In order to get the highest turbo frequencies, users would have to score big on all three metrics, as well as cooling, to stop one being a bottleneck. The end result promised by AMD was an aggressive voltage/frequency curve that would ride the limit of the hardware, right up to the TDP listed on the box.
This means we saw a much tighter turbo boost algorithm compared to Zen. Both Zen+ and Zen2 then moved to this boost algorithm that was designed to offer a lot more frequency opportunities in mixed workloads. This was known as Precision Boost 2.
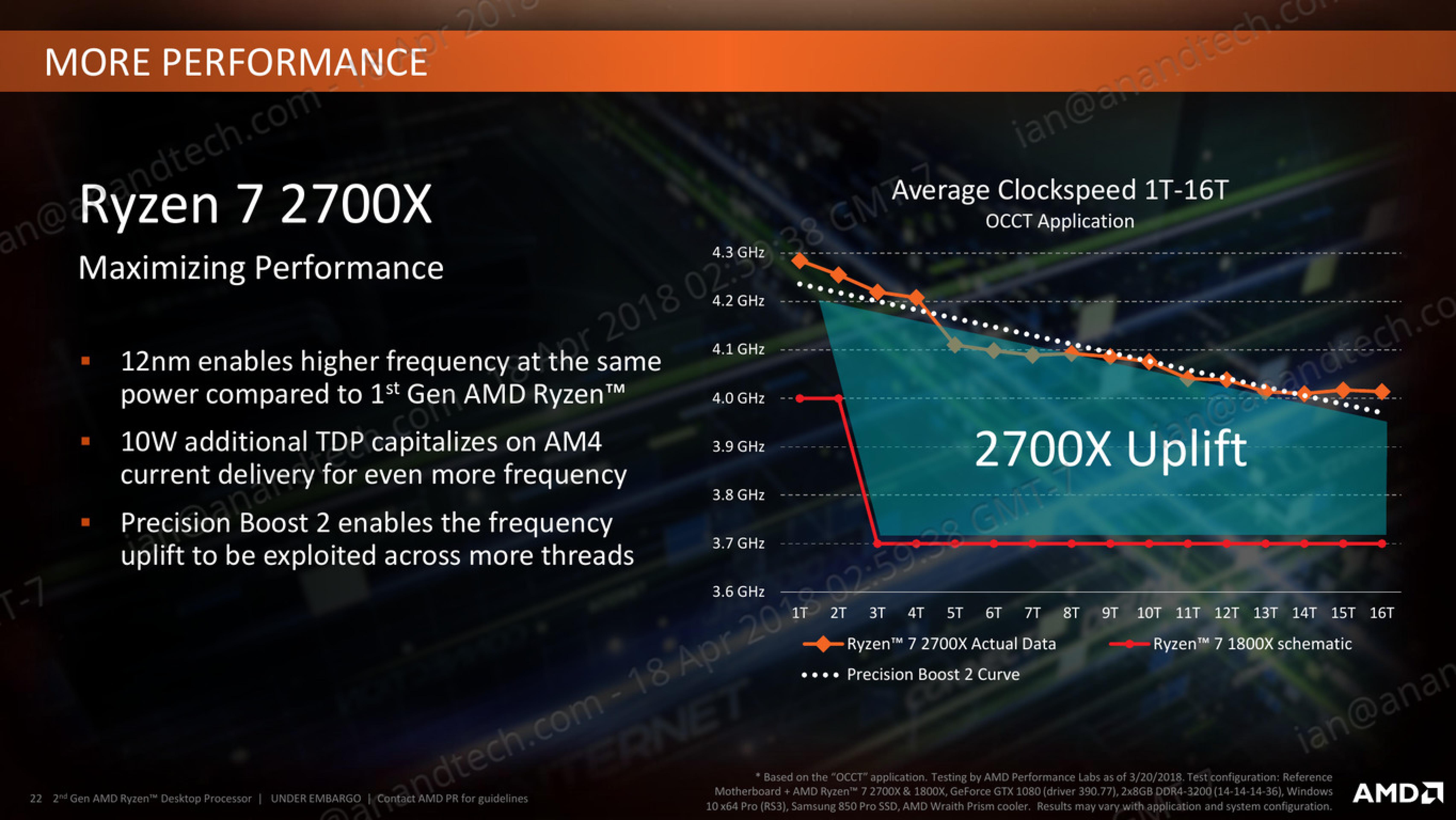
In this algorithm, we saw more than a simple step function beyond two threads, and depending on the specific chip performance as well as the environment the chip was in, the non-linear curve would react to the conditions and the workload to match hit the total power consumption of the chip as listed. The benefit of this was more performance in mixed workloads, in exchange for a tighter power consumption and frequency algorithm.
Move forward to Zen2, and one of the biggest differences for Zen2 is how the CPUs are binned. Since Zen, AMD’s own Ryzen Master software had been listing ‘best cores’ for each chip – for every Ryzen CPU, it would tell the user which cores had performed best based on internal testing, and were predicted to have this best voltage frequency curve. AMD took this a step further, and with the new 7nm process, in order to get the best frequencies out of every chip, it would perform binning per core, and only one core was required to reach the rated turbo speed.

So for example, here is a six-core Ryzen 5 3600X, with a base frequency of 3.8 GHz and a turbo frequency of 4.4 GHz. By binning tightly to the silicon maximums (for a given voltage), AMD was able to extract more performance on specific cores. If AMD had followed Intel’s binning strategy relating to turbo here, we would see a chip that would only be 4.2 GHz or 4.1 GHz maximum turbo – by going close to the chip limits for the given voltage, AMD is arguably offering more turbo functionality and ultimately more immediate performance.
There is one thing to note here though, which was the point of Paul’s article. In order to achieve maximum performance in a given workload, AMD had to adjust the Windows CPPC scheduler in order to assign a workload to the best core. By identifying the best cores on a chip, it meant that when a single threaded workload needed the best speed, it could be assigned to the best core (in our theoretical chip above that would be Core 2).
Note that with an Intel binning strategy, as the binning does not go to the per-core limits but rather relies on per-chip limits, it doesn’t matter what core the work is assigned to: this is the benefit of a homogeneous turbo binning design, and ultimately makes the scheduler algorithm in the operating system very simple. With AMD’s solution, that single best core is frequency scheduled that work, and as such the software stack in place needs to know the operation of the CPU and how to assign work to that specific core.
Does this make any difference to the casual user? No. For anyone just getting on with their daily activities, it makes absolutely zero difference. While the platform exposes the best cores, you need to be able to use tools to see it, and unless you uninstall the driver stack or micromanage where threads are allocated, you can’t really modify it. For casual users, and for gamers, it makes no difference to their workflow.
This binning strategy however does affect casual overclockers looking to get more frequency – based on AMD’s binning, there isn’t much headroom. All-core overclocks don’t really work in this scenario, because the chip is so close to the voltage/frequency curve already. This is why we’re not seeing great all-core overclocks on most Ryzen 3000 series CPUs. In order to get the best overall system overclocks this time around, users are going to have to play with each core one-by-one, which makes the whole process time consuming.
A small note about Precision Boost Overdrive (PBO) here. AMD introduced PBO in Zen and Zen+, and given the binning strategy on those chips, along with the mature 14/12nm process, users with the right thermal environment and right motherboards could extract another 100-200 MHz from the chip without doing much more than flicking a switch in the Ryzen Master software. Because of the new binning strategy – and despite what some of AMD's poorly executed marketing material has been saying – PBO hasn't been having the same effect, and users are seeing little-to-no benefit. This isn’t because PBO is failing, it’s because the CPU out of the box is already near its peak limits, and AMD’s metrics from manufacturing state that the CPU has a lifespan that AMD is happy with despite being near silicon limits. It ends up being a win-win, although people wanting more performance from overclocking aren’t going to get it – because they already have some of the best performance that piece of silicon has to offer.
The other point of assigning workloads to a specific core does revolve around lifespan. Typically over time, silicon is prone to electromigration, where electrons over time will slowly adjust the position of the silicon atoms inside the chip. Adjusting atom positioning typically leads to higher resistance paths, requiring more voltage over time to drive the same frequency, but which also leads to more electromigration. It’s a vicious cycle.
With electromigration, there are two solutions. One is to set the frequency and voltage of the processor low enough that over the expected age of the CPU it won’t ever become an issue, as it happens at such a slow rate – alternatively set the voltage high enough that it won’t become an issue over the lifetime. The second solution is to monitor the effect of electromigration as the core is used over months and years, then adjust the voltage upwards to compensate. This requires a greater level of detection and management inside the CPU, and is arguably a more difficult problem.
What AMD does in Ryzen 3000 is the second solution. The first solution results in lower-than-ideal performance, and so the second solution allows AMD to ride the voltage/frequency limits of a given core. The upshot of this is that AMD also knows (through TSMC’s reporting) how long each chip or each core is expected to last, and the results in their eyes are very positive, even with a single core getting the majority of the traffic. For users that are worried about this, the question is, do you trust AMD?
Also, to point out, Intel could use this method of binning by core. There’s nothing stopping them. It all depends on how comfortable the company is with its manufacturing process aligning with the expected longevity. To a certain extent, Intel already kind of does this with its Turbo Boost Max 3.0 processors, given that they specify specific cores to go beyond the Turbo Boost 2.0 frequency – and these cores get all the priority programs to run at a higher frequency and would experience the same electromigration worries that users might have by running the priority core more often. There difference between the two companies is that AMD has essentially applied this idea chip-wide and through its product stack, while Intel has not, potentially leaving out-of-the-box performance on the table.
A Short Detour on Mobile CPUs
For our readers that focus purely on the desktop space, I want to dive a bit into what happens with mobile SoCs and how turbo comes into effect there.
Most Arm based SoCs use a mechanism called EAS (Energy-Aware Scheduling) to manage how it implements both turbo but also which cores are active within a mobile CPU. A mobile CPU has one other aspect to deal with: not all cores are the same. A mobile CPU has both low power/low performance cores, and high power/high performance cores. Ideally the cores should have a crossover point where it makes sense to move the workload onto the big cores and spend more power to get them done faster. A workload in this instance will often start on the smaller low performance cores until it hits a utilization threshold and then be moved onto a large core, should one be available.
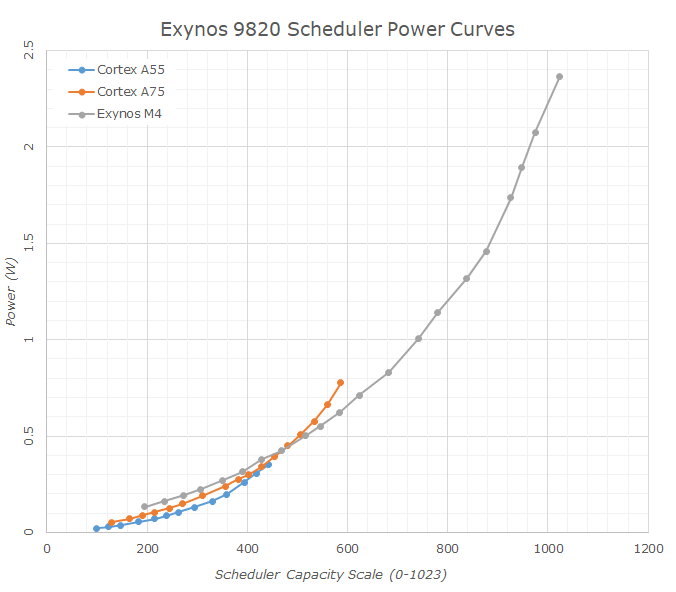
For example, here's Samsung's Exynos 9820, which has three types of cores: A55, A75, and M4. Each core is configured to a different performance/power window, with some overlap.
Peak Turbo on these CPUs is defined in the same way as Intel does on its desktop processors, but without the Turbo tables. Both the small CPUs and the big CPUs will have defined idle and maximum frequencies, but they will conform to a chip-to-chip defined voltage/frequency curve with points along that curve. When the utilization of a big core is high, the system will react and offer it the highest voltage/frequency up that curve as is possible. This means that the strongest workloads get the strongest frequency.
However, in Energy Aware Scheduling, because the devices that these chips go into are small and often have thermal limitations, the power can be limited by battery or thermals. There is no point for the chip to stay at maximum frequency only to burn in the hand. So the system will apply an Energy Aware algorithm, combined with the thermal probes inside the device, to ensure that the turbo and workload tend towards a peak skin temperature of the device (assuming a consistent, heavy workload). This power is balanced across the CPU, the GPU, and any additional accelerators within the system, and the proportion of that balance can be configured by the device manufacturer to respond to what proportion of CPU/GPU/NPU instructions are being fed to the chip.
As a result, when we see a mobile processor that advertises ‘2.96 GHz’, it will likely hit that frequency but the design of the device (and the binning of the chip) will determine how long before thermal limits kick in.
Do Manufacturers Guarantee Turbo Frequencies?
The question: ‘do manufacturers guarantee turbo frequencies?’ seems like it has an obvious answer to a lot of people. I performed a poll on my private twitter, and the voting results (700+) were astonishing.
Testing my audience's knowledge. Is the CPU Turbo Frequency on a desktop processor guaranteed by the manufacturer? Yes or No? [POLL]
— Dr. Ian Cutress (@IanCutress) September 12, 2019
31% of people said yes, 69% of people said no.
The correct answer is No, Turbo is never guaranteed.
To clarify, we need to define guarantee:
"A formal assurance that certain conditions will be fulfilled - if pertaining to a product, then that product will be repaired or replaced if not the specified quality."
This means that under a guarantee, the manufacturer would be prepared to repair or replace the product if it did not meet that guarantee. By that definition, Turbo is in no way under the guarantee from the manufacturer and does not fall under warranty.
Both AMD and Intel guarantee four things with their hardware: core counts, base frequency, peak power consumption at that base frequency (in essence, the TDP, even though strictly speaking TDP isn’t a measure of power consumption, but it is approximate), and the length of time those other items are guaranteed to work (usually three years in most locales). If you buy a 6 core CPU and only four cores work, you can get it replaced. If that six core CPU does not hit the base frequency under standard operations (standard is defined be Intel and AMD here, usually with a stock cooler, new paste, a clean chassis with active airflow of a minimum rate, and a given ambient temperature), then you can get it replaced.
Turbo, in this instance, is aspirational. We typically talk about things like ‘a 4.4 GHz Turbo frequency’, when technically we should be stating ‘up to 4.4 GHz Turbo frequency’. The ‘up to’ part is just as important as the rest, and the press (me included) is guilty of not mentioning the fact more often. Both Intel and AMD state that their processors under normal conditions should hit the turbo frequency, and both companies actively promote frequency enhancing tools such as aggressive power modes or better turbo profiles, but in no way is any of this actually guaranteed.
Yes, it does kind of suck (that’s the technical term). Both companies market their turbo frequencies loudly, proudly, and sometimes erroneously. Saying something is the ‘first X GHz’ processor only really means something if you can actually get into a position where that frequency is guaranteed. Unscrupulous retailers even put the turbo frequency as the highlight in their marketing material. Trying to explain to the casual user that this turbo frequency, this value that’s plastered everywhere, isn’t actually covered by the warranty, isn’t a good way to encourage them to get a processor.
AMD’s Turbo Issue (Abridged)
So why all this talk about how each company does its Turbo functionality, as well as its binning strategy? I prepped this story with the differences because a lot of our user base still thinks in terms of Intel’s way of doing things. Now that AMD is in the game and carving its own path, it’s important to understand AMD’s strategy in the context of the products coming out.
With that in mind, let’s cover AMD’s recent news.
Ever since the launch of Zen 2 and the Ryzen 3000 series CPUs, AMD has done its usual of advertising core counts, base frequency, TDP, and turbo frequencies. What has occurred since initial launch day reviews and through the public availability has been that groups of enthusiast users, looking to get the most out of their new shiny hardware, have reported that their processors are not hitting the turbo frequencies.
If a processor had a guaranteed 4.4 GHz turbo frequency, users were complaining that their peak turbo frequencies observed were 25-100 MHz less, or in some cases more than 100 MHz down on what was advertised. This kind of drop in frequency was being roughly reported through the ecosystem, but no-one particularly acted on it until these past few weeks, around the same time that AMD had several other news stories going on.
Multiple outlets, such as Hardware Unboxed, noted that the frequencies they were seeing significantly depended on the motherboard used. Hardware Unboxed tested 14 different AMD AM4 motherboards (some X570, others not X570) with a Ryzen 7 3800X, expecting a peak turbo frequency during Cinebench R20 of 4.5 GHz. Only one motherboard was consistent across most CPUs, while a few others were hit and miss.
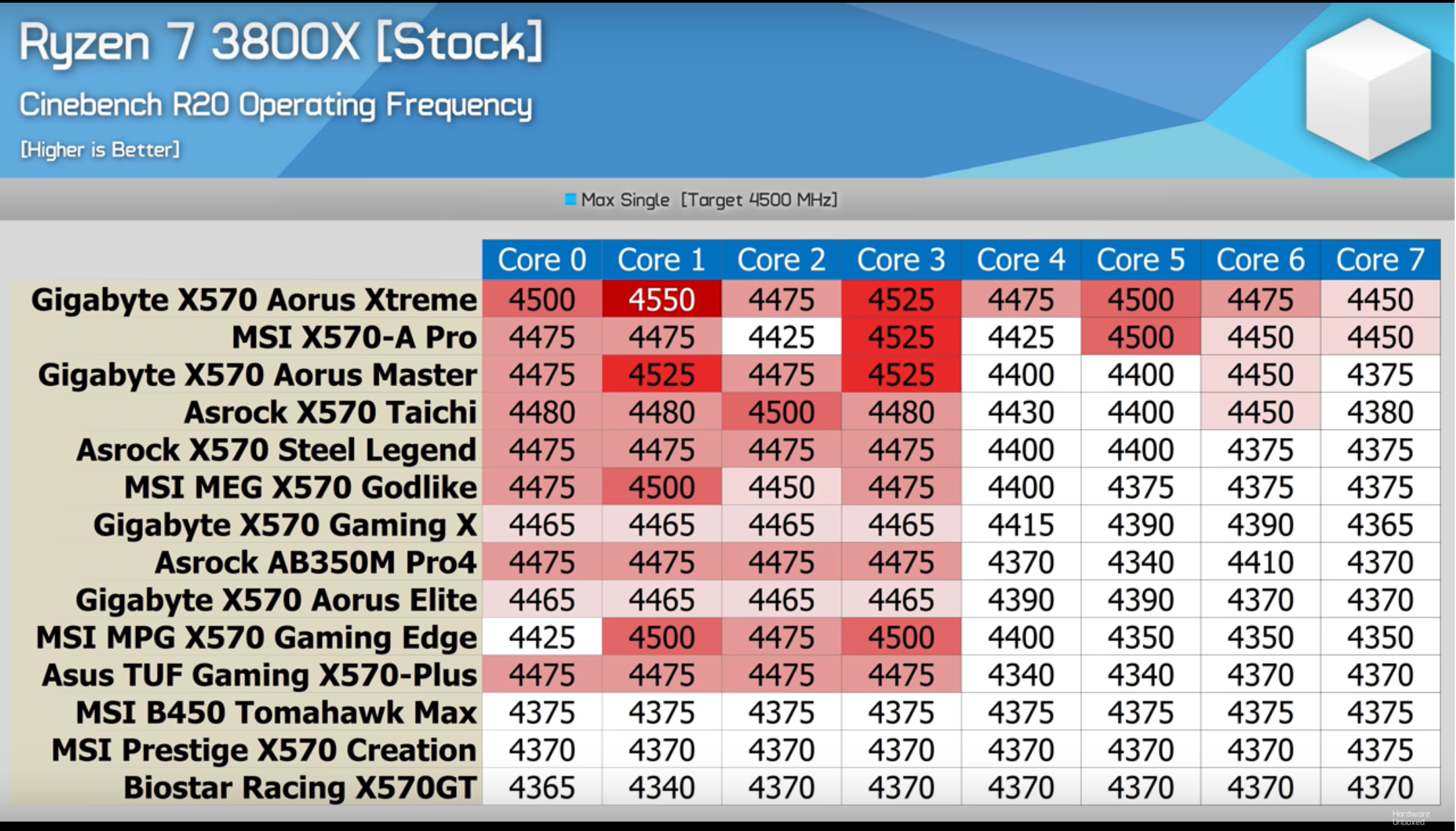
This obviously plays into some reasoning that the turbo is motherboard dependent, all else being equal. It should be noted that there’s no guarantee that all these motherboards, despite being on the latest BIOSes, actually had AMD’s latest firmware versions in place.
Another outlet, Gamers Nexus, also observed that they could guarantee a CPU would hit its rated turbo speeds when the system was under some form of cold, either chilled water or a sub-zero cooling environment. This ultimately would lead some believe that this relates to a thermal capacity issue within the motherboard, CPU, or power delivery.
The Stilt, a popular user commonly associated with AMD’s hardware and its foibles, posted on 8/12 that AMD had reduced its peak temperature value for the Ryzen 3000 CPUs, and had introduced a middle temperature value to help guide the turbo. These values would be part of the SMU, or System Management Unit, that helps control turbo functionality.

Peter Tan, aka Shamino, a world renowned (retired) overclocker and senior engineer for ASUS’ motherboard division, acknowledged the issue in a forum post on 8/22 with his own take on the matter. He stated that AMD’s initial outlay with its turbo boost behavior was ultimately too aggressive, and in order to ensure longevity of the chip, the boost behavior was in line with what AMD needed to achieve that longevity.
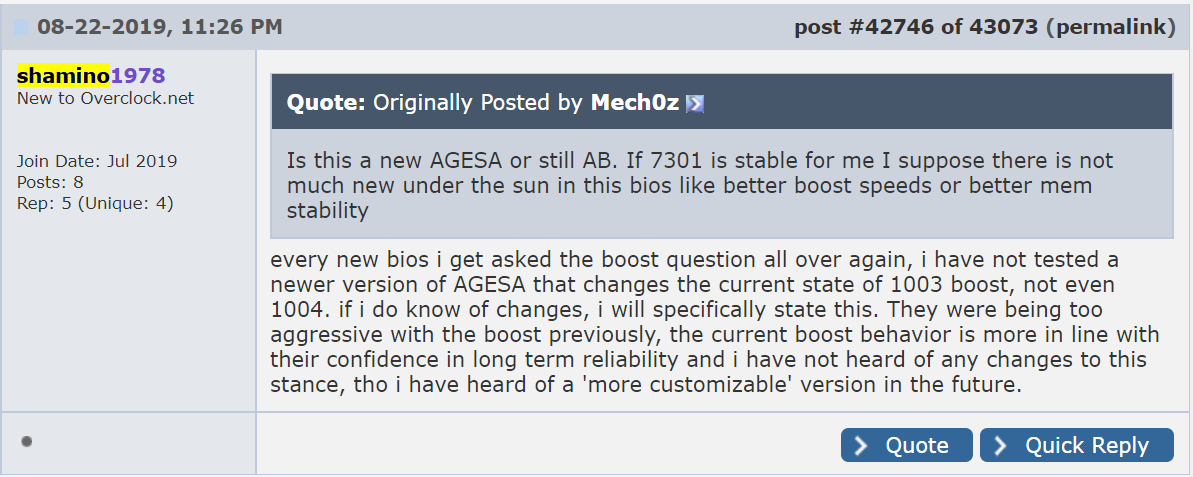
It should be stated here that Shamino is speaking here in his personal capacity.
For those not engrained in the minutae of forum life, the biggest arrow to this issue came from Roman Hartung, or Der8auer, through his YouTube channel. He enlisted the help of his audience to tabulate what frequencies users were getting.
In the survey, the following details were requested:
- CPU
- Motherboard
- AGESA version/BIOS version
- PBO disabled
- Air cooling
Now obviously when it was announced that this survey was going to happen, Roman and AMD discussed behind the scenes the pros and cons about this survey. As you might expect, AMD had some reservations that this survey was in any way going to be fair – it’s about as unscientific as you can get. Naturally Roman argued that these would be real world results with users machines, rather than in-lab results, and AMD should be guaranteeing users on their home machines with specific frequency values. AMD also pointed out that with this sort of survey, you have an inherent selection bias: users who feel negatively impacted by any issue (through AMD’s fault or the users own) are more likely to respond than those that were happy with the performance. Roman agreed that this would be a concern, but still highlighted the fact that users shouldn’t be having these issues in the first place. AMD also mentioned that the Windows version couldn’t be controlled, to which Roman argued that if turbo is only valid for a certain Windows version, then it’s not fair to promote it, however did concede that the best performance was the latest version of Windows 10, and users on Windows 7 will have to accept some level of reduced performance.
Roman and AMD did at least agree on a testing scenario in order to standardize the reporting. Based on AMD’s recommendations, Roman requested from his audience that they use CineBench R15 as a single threaded load, and HWiNFO as the reporting tool, set to a 500 millisecond (0.5 second) polling interval, with the peak frequency from the CPU listed.
The survey ended up with ~3300 valid submissions, which Roman checked one-by-one to make sure all the data was present, screenshots showed the right values, and removed any data points that didn’t pass the testing conditions (such as PBO enabled). The results are explained in Roman’s video and the video is well worth a look. I’ve summarized the data for each CPU here.
| Der8auer's Ryzen Turbo Survey Results | |||||
| AnandTech | 3600 | 3600X | 3700X | 3800X | 3900X |
| Rated Turbo MHz of CPU | 4200 | 4400 | 4400 | 4500 | 4600 |
| Average Survey MHz | 4158 | 4320 | 4345 | 4450 | 4475 |
| Mode Survey MHz* | 4200 | 4350 | 4375 | 4475 | 4525 |
| Total Results Submitted | 568 | 190 | 1087 | 159 | 722 |
| # Results Minus Outliers | 542 | 180 | 1036 | 150 | 685 |
| Results >= Rated Turbo | 210 | 17 | 153 | 39 | 38 |
| % Results >= Rated Turbo | 50% | 9% | 15% | 26% | 6% |
| *Mode = most frequent result | |||||
I have corrected a couple of Roman’s calculations based on the video data, but they were minor changes.
For each CPU, we have the listed turbo frequency, the average turbo frequency from the survey, and the modal CPU frequency (i.e. the most frequently reported frequency). Beyond this, the number of users that reported a frequency equal to the turbo frequency or higher is listed as a percentage.
On the positive, the modal reported CPU frequency for almost all chips (except the 3900X) is relatively close, showing that most users are within 25-50 MHz of the advertised peak turbo frequency. The downside is that the actual number of users achieving the rated turbo is quite low. Aside from the Ryzen 5 3600, which is 50%, all the other CPUs struggle to see rated turbo speeds on the box.
As you might imagine, this data caused quite a stir in the community, and a number of vocal users who had invested hard earned money into their systems were agonizingly frustrated that they were not seeing the numbers that the box promised.
Before covering AMD’s response, I want to discuss frequency monitoring tools, turbo times, and the inherent issues with the Observer Effect. There’s also the issue of how long does turbo need to be active for it to count (or even register in software).
Detecting Turbo: Microseconds vs. Milliseconds
One of the biggest issues with obtaining frequency data is the actual process of monitoring. While there are some basic OS commands to obtain the frequency, it isn’t just as simple as reading a number.
How To Read A Frequency
As an outlay, we have to differentiate between the frequency of a processor vs. the frequency of a core. On modern PC processors, each core can act independently of each other in terms of frequency and voltage, and so each core can report different numbers. In order to read the value for each core, that core has to be targeted using an affinity mask that binds the reading to a particular core. If a simple ‘what’s the frequency’ request goes out to a processor without an affinity mask, it will return the value of the core to which that thread ends up being assigned. Typically this is the fastest core, but if there is already work being performed on a chip, that thread might end up on an idle core. If a request to find out ‘what is the current frequency of the processor’ is made, users could end up with a number of values: the frequency on a specific core, the frequency of the fastest core, or an average frequency of all the cores. To add more confusion to the matter, if the load on a core is taken into account, depending on the way the request is made, a core running at ‘50%’ load at peak frequency might end up returning a value of half frequency.
There are a multitude of programs that report frequency. Several of the most popular include:
- CPU-Z
- HWiNFO
- Intel XTU
- Intel Power Gadget
- Ryzen Master
- AIDA64
Some of these use similar methods to access frequency values, others have more intricate methods, and then the reporting and logging of each frequency value can have different effects on the system being tested.
I asked one of the main developers of these monitoring tools how they detect the frequency of a core. They gave me a brief overview – it’s not as simple as it turns out.
- Know the BCLK (~100 MHz) precisely. Normally this is done my measuring the APIC clock, but on modern systems that use internal clock references (Win 10 1803+) this causes additional interrupt bandwidth, and so often this value is polled rarely and cached.
- Detect the CPU Core multiplier by reading a single Model Specific Register based on the CPU. This has to be done in kernel mode, so there is additional overhead switching from user mode to kernel mode and back.
- This has to be repeated for each core by using an affinity mask, using a standard Win32 API call of SetCurrentThreadAffinityMask. As this is an API call, there is again additional overhead.
So the frequency of a single core here is measured by the base clock / BCLK and multiplying it by the Core Multiplier as defined in the registers for that core, all through an affinity mask. Typically BCLK is the same across all cores, but even that has some drift and fluctuations over time, so it will depend on how frequently you request that data.
Another alternative method is to apply a simple load – a known array of consistent instructions and to measure the number of cycles / length of time it takes to compute that small array. This method might be considered more accurate by some, but it still requires the appropriate affinity mask to be put in place, and actually puts in additional load to the system, which could cause erroneous readings.
How Quick Can Turbo Occur
Modern processors typically Turbo anywhere from 4 GHz to 5 GHz, or four to five billion cycles a second. That means each cycle at 5 GHz is equal to 0.2 nanoseconds, or 0.2 x 10-9 seconds. These processors don’t stay at that frequency – they adjust the frequency up or down based on the load requests, which helps manage power and heat. How quickly a processor can respond to these requests for a higher frequency has become a battleground in recent years.
How a processor manages its frequency all comes down to how it interacts with the operating system. In a pre-Skylake world, a processor would have a number of pre-defined ACPI power states, relating to performance (P), Device (D), and processor (C), based on if the processor was on, in sleep, or needed high frequency. P-states relied on a voltage-frequency scaling, and the OS could control P0 to P1 to P2 and beyond, with P1 being the guaranteed base frequency and any higher P number being OS controlled. The OS could request P0, which enabled the processor to enter boost mode. All of this would go through a set of OS drivers relating to power and frequency control; this came to be known as SpeedStep for Intel, and Cool’n’Quiet for AMD.
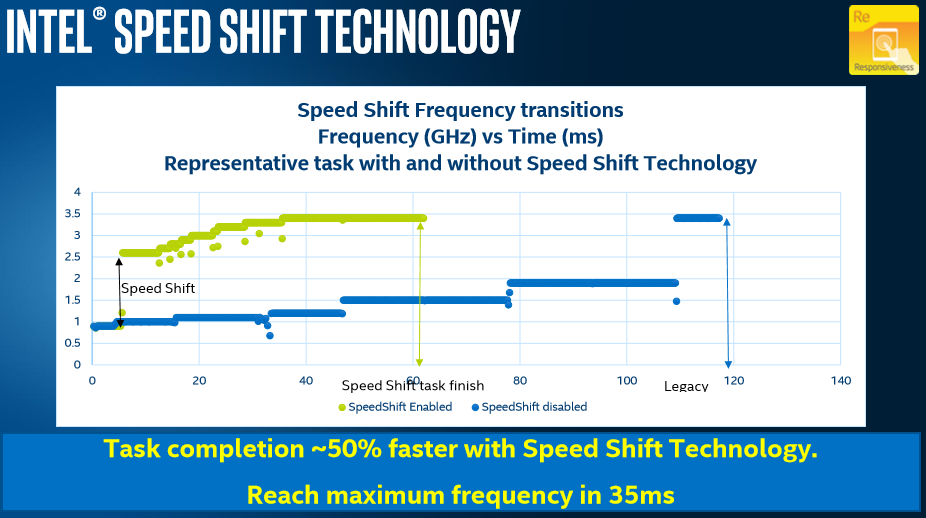
As defined in the ACPI specifications, with the introduction of UEFI control came CPPC, or Collaborative Processor Performance Control. Requiring CPU and OS support, with Skylake we saw Intel and Microsoft introduced a new ‘Speed Shift’ feature that put the control of the frequency modes of the processor back in the hands of the processor – the CPU could directly respond to the instruction density coming into the core and modify the frequency directly without additional commands. The end result of CPPC, and Speed Shift for Intel, was a much faster frequency response mechanism.
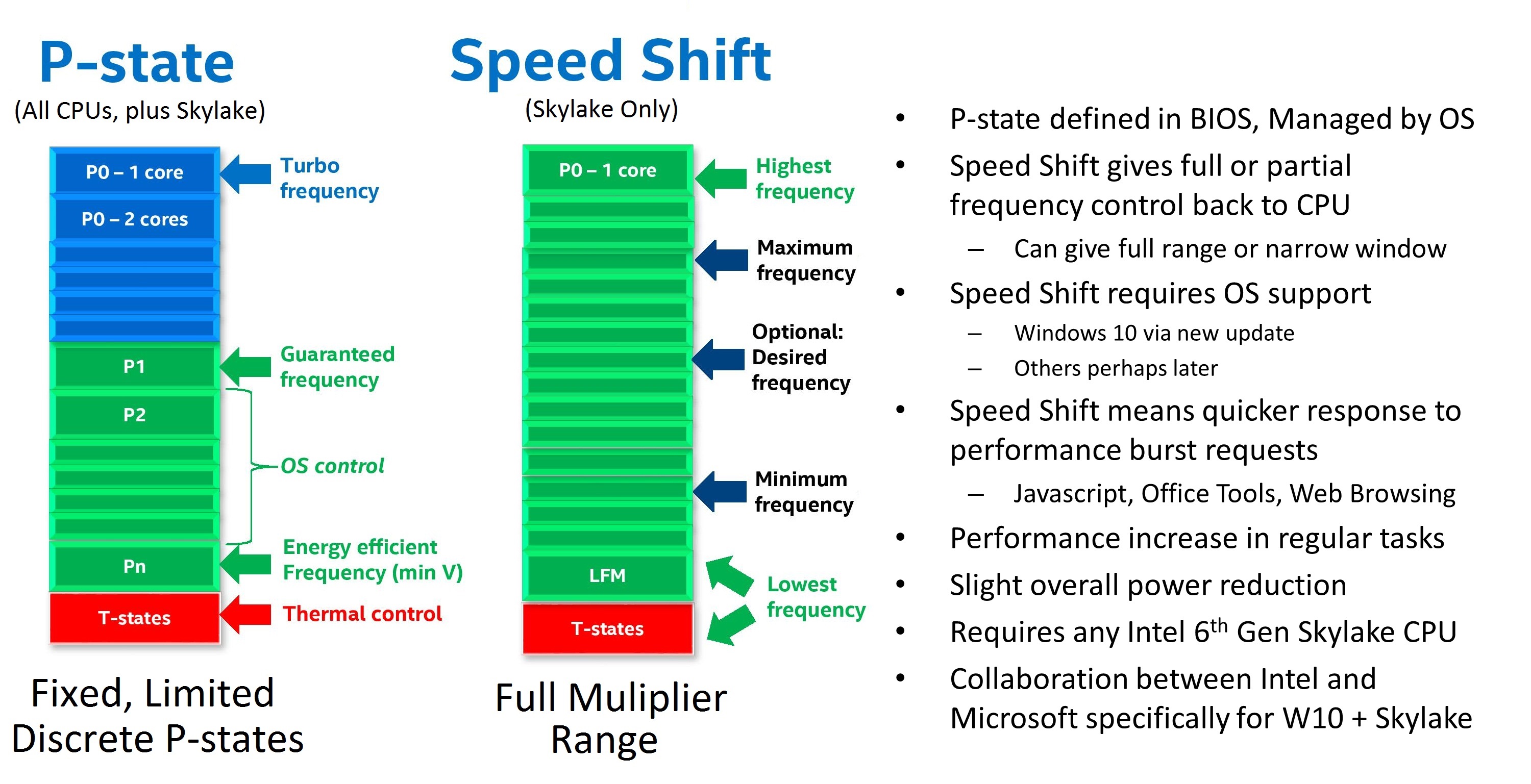
With Speed Shift in Skylake, on Windows, Intel was promoting that before Speed Shift they were changing frequency anywhere up to 100 milliseconds (0.1 s) after the request was made. With Speed Shift, that had come down to the 35 millisecond mark, around a 50-66% improvement. With subsequent updates to the Skylake architecture and the driver stack, Intel states that this has improved further.
Users can detect to see if CPPC is enabled on their Intel system very easily. By going to the Event Viewer, selecting Window Logs -> System, and then going to a time stamp where the machine was last rebooted, we can see ACPI CPPC listed under the Kernel-Processor-Power source.
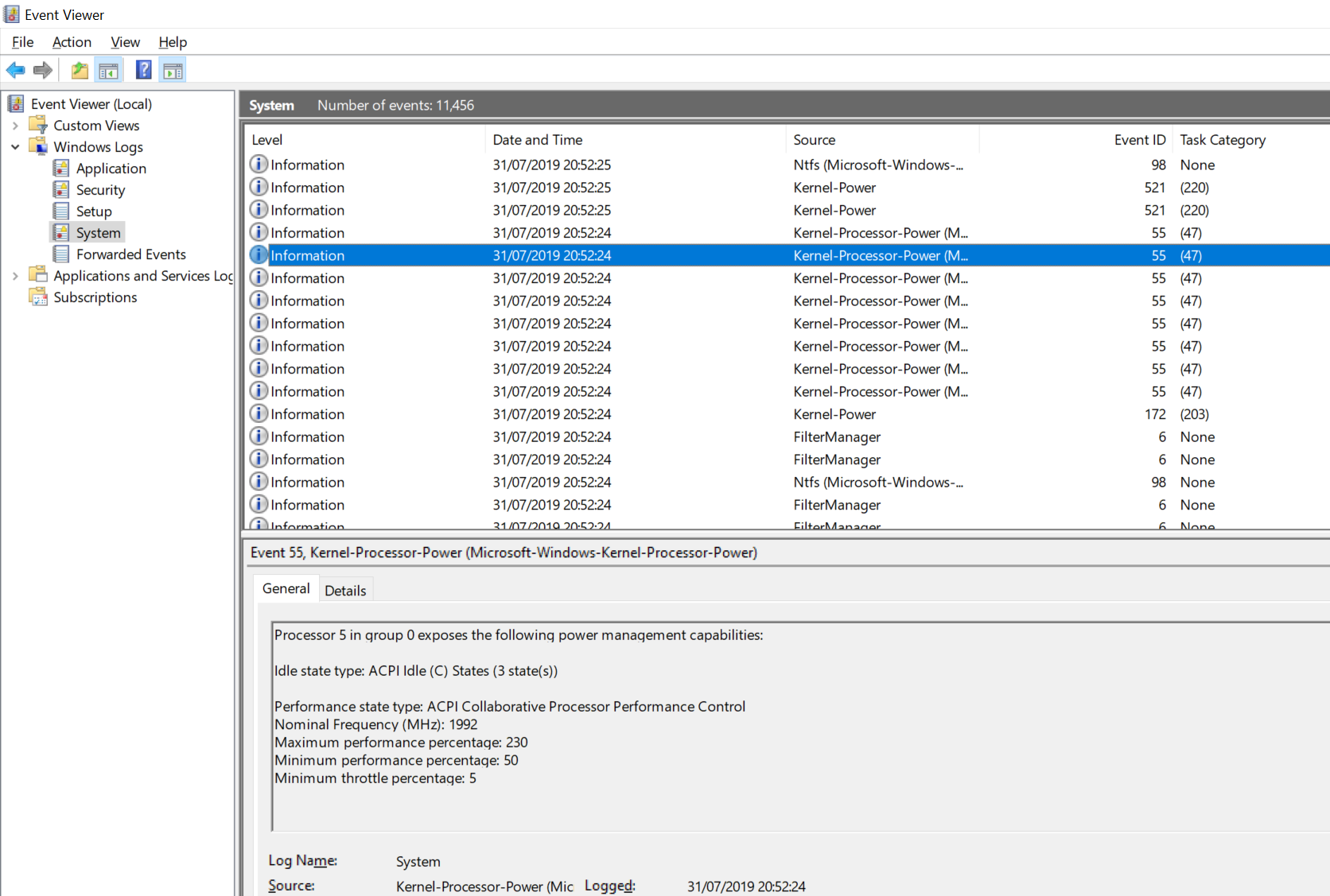
For my Core i7-8565U Whiskey Lake CPU, it shows that APCI CPPC is enabled, and that my CPU Core 5 is running at 2.0 GHz base with a 230% peak turbo, or 4.6 GHz, which relates to the single-core turbo frequency of my processor.
For AMD, with Zen 2, the company announced the use of CPPC2 in collaboration with Microsoft. This is CPPC but with a few extra additional tweaks to the driver stack for when an AMD processor is detected.

Here AMD is claiming that they can change frequency, when using the Windows 10 May 2019 update or newer, on the scale of 1-2 ms, compared to 30 ms with the standard CPPC interface. This comes down to how AMD has implemented its ‘CPPC2’ model, with a series of shim drivers in place to help speed the process along. If we go back to how we can detect that CPPC mode similar to Intel, we see a subtle difference:
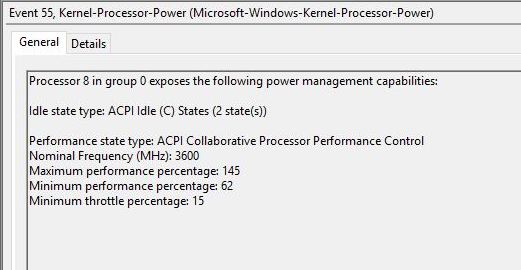
Ryzen 7 3700X
Notice here it doesn’t say CPPC2, just CPPC. What does display is the 3600 MHz base frequency of our 3700X, and a maximum performance percentage of 145%, which would make the peak turbo of this processor somewhere near 5220 MHz. Clearly that isn’t the peak turbo of this CPU (which would be 4400 MHz), which means that AMD is using this artificially high value combined with its CPPC driver updates to help drive a faster frequency response time.
The Observer Effect
Depending on the software being used, and the way it calculates the current frequency of any given core/processor, we could end up artificially loading the system, because as explained above it is not as simple as just reading a number – extra calculations have to be made or API calls have to be driven. The more frequently the user tries to detect the frequency, the more artificial load is generated on the core, and at some point the system will detect this as requiring a different frequency, making the readings change.
This is called the observer effect. And it is quite easy to see it in action.
For any tool that allows the user to change the polling frequency, as the user changes that frequency from once per second to ten times per second, then 100 times per second, or 1000 times per second, even on a completely idle system, some spikes will be drawn – more if the results are being logged to memory or a data file.
Therein lies the crutch of frequency reporting. Ultimately we need the polling frequency to be quick enough to capture all the different frequency changes, but we don’t want it interfering with the measurement. Combined with CPPC, this can make detecting certain peak frequencies particularly annoying.
Let’s go back to our time scales for instructions and frequency changes. At 4 GHz, we can break down the following:
| Time Scales at 4 GHz | ||
| AnandTech | Time | Unit |
| One Cycle | 0.00000000025 |
s |
| Simple Loop (1000 cycles) | 0.0000025 |
s |
| CPPC Frequency Change (AMD) | 0.002 |
s |
| Frequency Polling | 0.1 |
s |
Note that a frequency change is the equivalent to losing around 800,000 cycles at 4 GHz, so the CPU has to gauge to what point the frequency change is worth it based on the instructions flowing into the core.
But what this does tell is one of the inherent flaws in frequency monitoring – if a CPU can change frequency as quickly as every 1-2 ms, but we can only poll at around 50-100 ms, then we can miss some turbo values. If a processor quickly fires up to a peak turbo, processes a few instructions, and then drops down almost immediately due to power/frequency requirements not being met for the incoming instruction stream, it won’t ever be seen by the frequency polling software. If the requirements are met of course, then we do see the turbo frequency – the value we end up seeing is the one that the system feels is more long-term suitable.
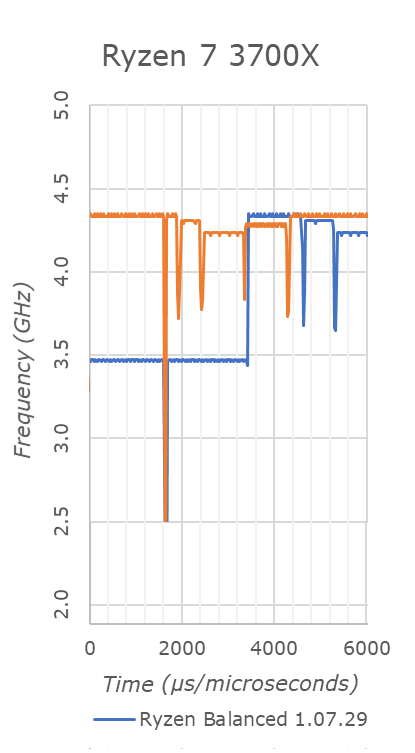
With an attempt at sub-1ms polling time, we can see this in effect. The blue line shows the Ryzen processor in a balanced power configuration, and at around 3.6 milliseconds the 3700X jumps up to 4350-4400 MHz, bouncing around between the two. But by 4.6 milliseconds, we have already jumped down to 4.3 GHz, then at 5.2 milliseconds we are at 4.2 GHz.
We were able to obtain this data using Windows Subsystem for Linux, using an add-dependency chain from which we derive the frequency based on the throughput. There is no observer effect here because it is the workload – not something that can be done when an external workload is used. It gives us a resolution of around 40 microseconds, and relies on the scheduler automatically assigning the thread to the best core.
But simply put, unless a user is polling this quick, the user will not see the momentary peaks in turbo frequency if they are on the boundary of supporting it. The downside of this is that polling this quick puts an artificial load on the system, and means any concurrent running benchmark will be inadequate.
(For users wondering what that orange line is, that would be the processor in ‘performance mode’, which gives a higher tolerance for turbo.)
It all leads to a question – if a core hits a turbo frequency but you are unable to detect it, does that count?
Ultimately, by opting for a more aggressive binning strategy so close to silicon limits, AMD has reached a point where, depending on the workload and the environment, a desktop CPU might only sustain a top Turbo bins momentarily. Like Turbo itself, this is not a bad thing, as it extracts more performance from their processors that would otherwise be left on the table by lower clockspeeds. But compared to Intel’s processors and what we’re used to, these highest bins require more platform management to ensure that the processor is indeed reaching its full potential.
AMD Found An Issue, for +25-50 MHz
Of course, with Roman’s dataset hitting the internet with its results, a number of outlets reported on it and a lot of people were in a spin. It wasn’t long for AMD to have a response, issued in the form of a blog post. I’m going to take bits and pieces here from what is relevant, starting with the acknowledgement that a flaw was indeed found:
As we noted in this blog, we also resolved an issue in our BIOS that was reducing maximum boost frequency by 25-50MHz depending on workload. We expect our motherboard partners to make this update available as a patch in two to three weeks. Following the installation of the latest BIOS update, a consumer running a bursty, single threaded application on a PC with the latest software updates and adequate voltage and thermal headroom should see the maximum boost frequency of their processor.
AMD acknowledged that they had found a bug in their firmware that was reducing the maximum boost frequency of their CPUs by 25-50 MHz. If we take Roman’s data survey, adding 50 MHz to every value would push all the averages and modal values for each CPU above the turbo frequency. It wouldn’t necessarily help the users who were reporting 200-300 MHz lower frequencies, to which AMD had an answer there:
Achieving this maximum boost frequency, and the duration of time the processor sits at this maximum boost frequency, will vary from PC to PC based on many factors such as having adequate voltage and current headroom, the ambient temperature, installing the most up-to-date software and BIOS, and especially the application of thermal paste and the effectiveness of the system/processor cooling solution.
As we stated at the AMD Turbo section of this piece, the way that AMD implements its turbo is different, and it does monitor things like power delivery, voltage and current headroom, and will adjust the voltage/frequency based on the platform in use. AMD is reiterating this, as I expected they would have to.
AMD in the blog post mentioned how it had changed its firmware (1003AB) in August for system stability reasons, categorically denying that it was for CPU longevity reasons, saying that the latest firmware (1003ABBA) improves performance and does not affect longevity either.
The way AMD distributes its firmware is through AGESA (AMD Generic Encapsulated Software Architecture). The AGESA is essentially a base set of firmware and library files that gets distributed to motherboard vendors who then apply their own UEFI interfaces on top. The AGESA can also include updates for other parts of the system, such as the System Management Unit, that have their own firmware related to their operation. This can make updating things a bit annoying – motherboard vendors have been known to mix and match different firmware versions, because ultimately at the end of the day the user ends up with ‘BIOS F9’ or something similar.
AMD’s latest AGESA at the time of writing is 1003ABBA, which is going through motherboard vendors right now. MSI and GIGABYTE have already launched beta BIOS updates with the new AGESA, and should be pushing it through to stable versions shortly, as should be ASUS and ASRock.
Some media outlets have already tested this new firmware, and in almost all circumstances, are seeing a 25-50 MHz uplift in the way that the frequency was being reported. See the Tom’s Hardware article as a reference, but in general, reports are showing a 0.5-2.0% increase in performance in single thread turbo limited tests.
I Have a Ryzen 3000 CPU, Does It Affect Me?
The short answer is that if you are not overclocking, then yes. When your particular motherboard has a BIOS update for 1003ABBA, then it is advised to update. Note that updating a BIOS typically means that all BIOS settings are lost, so keep a track in case the DRAM needs XMP enabled or similar.
Users that are keeping their nose to the grindstone on the latest AMD BIOS developments should know the procedure.
The Future of Turbo
It would be at this point that I might make commentary that single thread frequency does not always equal performance. As part of the research for this article, I learned that some users believe that the turbo frequency listed on the box believe it is the all-core turbo frequency, which just goes to show that turbo still isn’t well understood in name alone. But as modern workloads move to multi-threaded environments with background processes, the amount of time spent in single-thread turbo is being reduced. Ultimately we’re ending up with a threading balance between background processes and immediate latency sensitive requirements.
At the end of the day, AMD identifying a 25-50 MHz deficit and fixing it is a good thing. The number of people for whom this is a critical boundary that enables a new workflow though, is zero. For all the media reports that drummed up AMD not hitting published turbo speeds as a big thing, most of those reporters ended up by contrast being very subdued with AMD’s fix. 2% on the single core turbo frequency hasn’t really changed anyone in this instance, despite all the fuss that was made.
I wrote this piece just to lay some cards on the table. The way AMD is approaching the concept of Turbo is very different to what most people are used to. The way AMD is binning its CPUs on a per-core basis is very different to what we’re used to. With all that in mind, peak turbo frequencies are not covered by warranty and are not guaranteed, despite the marketing material that goes into them. Users who find that a problem are encouraged to vote with their wallet in this instance.
Moving forward, I’m going to ask our motherboard editor, Gavin, to start tracking peak frequencies with our WSL tool. Because we’re defining the workload, our results might end up different to what users are seeing with their reporting tools while running CineBench or any other workload, but it can offer the purest result we can think of.
Ultimately the recommendations we made in our launch day Ryzen review still stand. If anything, if we had experienced some frequency loss, some extra MHz on the ST tests would push the parts slightly up the graph. Over time we will be retesting with the latest BIOS updates.






