Original Link: https://www.anandtech.com/show/15785/the-intel-comet-lake-review-skylake-we-go-again
The Intel Comet Lake Core i9-10900K, i7-10700K, i5-10600K CPU Review: Skylake We Go Again
by Dr. Ian Cutress on May 20, 2020 9:00 AM EST- Posted in
- CPUs
- Intel
- Skylake
- 14nm
- Z490
- 10th Gen Core
- Comet Lake

The first thing that comes to mind with Intel’s newest line of 10th Generation desktop processors is one of ‘14nm Skylake, again?’. It is hard not to ignore the elephant in the room – these new processors are minor iterative updates on Intel’s 2015 processor line, moving up from four cores to ten cores and some extra frequency, some extra security measures, a modestly updated iGPU, but by and large it is still the same architecture. At a time when Intel has some strong competition, Comet Lake is the holding pattern until Intel can bring its newer architectures to the desktop market, but can it be competitive?
Three weeks ago, Intel announced the Comet Lake 10th Generation Core processor family line for desktops. From Celeron and Pentium all the way up to Core i9 there were 32 new processor models, representing a sizeable offering to the market. The key elements to this range of processors was the introduction of 10 cores for the Core i9 parts at the high-end – an increase of two cores over the last generation – and the introduction of Intel’s Thermal Velocity Boost for Core i9 that enables +100 MHz in the cooler thermal environments.

The best processor from the range, the Core i9-10900K, promises 5.3 GHz peak turbo in optimal conditions for two preferred cores, or 4.9 GHz for all-core situations. Everything from Core i9, Core i7, Core i5, Core i3, and the Pentium Gold processors have hyperthreading, making the processor stack easier to understand for this generation. Compared to the previous generation, there are a lot of similar processor matchups, and except for the top 10-core parts, the offerings should move down one price bracket this time around.
Intel has changed the socket for this generation, moving to an LGA1200 platform. This also means there are new motherboards, the Intel 400 series family, including the Z490 chipset which has 44+ entrants ranging from $150 all the way up to $1200. We have a very thorough analysis of every motherboard in our Z490 motherboard overview.
The Processor Stack
As mentioned, there are 32 processors for the new Comet Lake 10th Generation Core family. The Core i9/i7/i5/i3 parts will broadly fall into four categories:
- K = Overclockable with Integrated Graphics, 125 W TDP
- KF = Overclockable but no Integrated Graphics, 125 W TDP
- F = No Integrated Graphics, 65 W
- T = Low Power with Integrated Graphics, 35 W
- No Suffix = Regular CPU with Integrated Graphics, 65 W
Intel uses these divisions based on both customer demand but also its ability to separate the best quality silicon from its manufacturing. Silicon that can enable low-power operation becomes T processors, while silicon that can push the highest frequencies at reasonable voltages becomes the K silicon. Some silicon might not be up to par with the integrated graphics, and so these become F processors, and are generally cheaper than the non-F versions to the tune of $11-$25.
Here is how these new processors stack-up.
| Intel 10th Gen Comet Lake Core i9 and Core i7 |
||||||||||
| AnandTech | Cores | Base Freq |
TB2 2C |
TB2 nT |
TB3 2C |
TVB 2C |
TVB nT |
TDP (W) |
IGP | Price 1ku |
| Core i9 | ||||||||||
| i9-10900K | 10C/20T | 3.7 | 5.1 | 4.8 | 5.2 | 5.3 | 4.9 | 125 | 630 | $488 |
| i9-10900KF | 10C/20T | 3.7 | 5.1 | 4.8 | 5.2 | 5.3 | 4.9 | 125 | - | $472 |
| i9-10900 | 10C/20T | 2.8 | 5.0 | 4.5 | 5.1 | 5.2 | 4.6 | 65 | 630 | $439 |
| i9-10900F | 10C/20T | 2.8 | 5.0 | 4.5 | 5.1 | 5.2 | 4.6 | 65 | - | $422 |
| i9-10900T | 10C/20T | 1.9 | 4.5 | 3.7 | 4.6 | - | - | 35 | 630 | $439 |
| Core i7 | ||||||||||
| i7-10700K | 8C/16T | 3.8 | 5.0 | 4.7 | 5.1 | - | - | 125 | 630 | $374 |
| i7-10700KF | 8C/16T | 3.8 | 5.0 | 4.7 | 5.1 | - | - | 125 | - | $349 |
| i7-10700 | 8C/16T | 2.9 | 4.7 | 4.6 | 4.8 | - | - | 65 | 630 | $323 |
| i7-10700F | 8C/16T | 2.9 | 4.7 | 4.6 | 4.8 | - | - | 65 | - | $298 |
| i7-10700T | 8C/16T | 2.0 | 4.4 | 3.7 | 4.5 | - | - | 35 | 630 | $325 |
| Core i5 | ||||||||||
| i5-10600K | 6/12 | 4.1 | 4.8 | 4.5 | - | - | - | 125 | 630 | $262 |
| i5-10600KF | 6/12 | 4.1 | 4.8 | 4.5 | - | - | - | 125 | - | $237 |
| i5-10600 | 6/12 | 3.3 | 4.8 | 4.4 | - | - | - | 65 | 630 | $213 |
| i5-10600T | 6/12 | 2.4 | 4.0 | 3.7 | - | - | - | 35 | 630 | $213 |
| i5-10500 | 6/12 | 3.1 | 4.5 | 4.2 | - | - | - | 65 | 630 | $192 |
| i5-10500T | 6/12 | 2.3 | 3.8 | 3.5 | - | - | - | 35 | 630 | $192 |
| i5-10400 | 6/12 | 2.9 | 4.3 | 4.0 | - | - | - | 65 | 630 | $182 |
| i5-10400F | 6/12 | 2.9 | 4.3 | 4.0 | - | - | - | 65 | - | $157 |
| i5-10400T | 6/12 | 2.0 | 3.6 | 3.2 | - | - | - | 35 | 630 | $182 |
| Core i3 | ||||||||||
| i3-10320 | 4/8 | 3.8 | 4.6 | 4.4 | - | - | - | 65 | 630 | $154 |
| i3-10300 | 4/8 | 3.7 | 4.4 | 4.2 | - | - | - | 65 | 630 | $143 |
| i3-10300T | 4/8 | 3.0 | 3.9 | 3.6 | - | - | - | 35 | 630 | $143 |
| i3-10100 | 4/8 | 3.6 | 4.3 | 4.1 | - | - | - | 65 | 630 | $122 |
| i3-10100T | 4/8 | 3.0 | 3.8 | 3.5 | - | - | - | 35 | 630 | $122 |
| Pentium Gold | ||||||||||
| G6600 | 2/4 | 4.2 | - | - | - | - | - | 58 | 630 | $86 |
| G6500 | 2/4 | 4.1 | - | - | - | - | - | 58 | 630 | $75 |
| G6500T | 2/4 | 3.5 | - | - | - | - | - | 35 | 630 | $75 |
| G6400 | 2/4 | 4.0 | - | - | - | - | - | 58 | 610 | $64 |
| G6400T | 2/4 | 3.4 | - | - | - | - | - | 35 | 610 | $64 |
| Celeron | ||||||||||
| G5920 | 2/2 | 3.5 | - | - | - | - | - | 58 | 610 | $52 |
| G5900 | 2/2 | 3.4 | - | - | - | - | - | 58 | 610 | $42 |
| G5900T | 2/2 | 3.2 | - | - | - | - | - | 35 | 610 | $42 |
The Core i9 and Core i7 processors will support DDR4-2933, while everything else supports DDR4-2666. These processors are all PCIe 3.0, with sixteen lanes from the CPU available for add-in cards and direct connected storage. Intel likes to point out that they offer another 24 PCIe 3.0 lanes on the chipset, however the uplink to the processor is still a DMI/PCIe 3.0 x4 link.
As far as we understand, Intel will be coming to market first with the K processors, and the other processors should be a quick follow-on. That being said, a large number of Intel’s Core 9th Gen processor line have been difficult to obtain at retail as the company sees record demand for its server processors. As those command a higher operating margin, Intel would rather spend its manufacturing resources making those server processors instead, leading to shortages of the consumer mainline CPUs. Even as a primary reviewing technology media organization focusing on companies like Intel, Intel has not proactively sampled the media with many of the 9th Generation parts - perhaps the lack of availability is one of those reasons. It will be interesting to see how many of the Intel 10th Gen processors are made available to both reviewers and the public alike.
For this review, we were able to obtain the 10-core Core i9-10900K, the 8-core Core i7-10700K, and the 6-core Core i5-10600K.
Getting Complicated with Turbo
In the charts above, we have multiple different levels of ‘turbo’ for every processor. Intel loves to talk turbo in the sense of offering performance, however it can get complicated about which levels of turbo apply at any given time. Turbo Boost 2, Turbo Boost Max 3.0, and Thermal Velocity Boost without context make very little sense to anyone not necessarily au fait with the world of computer processors. To break it down:
- Base Frequency: Minimum guaranteed frequency at any time
- Turbo Boost 2.0: A potential upper limit frequency that all cores can achieve at any time
- Turbo Boost Max 3.0: Also known as Favored Core, this is a peak frequency that two select cores can achieve at any time
- Thermal Velocity Boost: A new upper limit mode frequency where all cores can gain +100 MHz if the processor temperature is below a given limit, including favored cores in TBM3 mode
- Favored Core: Up to two cores per processor are selected as the cores that provide the best voltage-to-frequency-to-power response, making them the best candidates for additional turbo frequency
With these definitions in mind, we can go through each of the different turbo modes into some level of specificity:
- Base Frequency: The guaranteed frequency when not at thermal limits
- Turbo: A frequency noted when below turbo power limits and turbo power time
- All-Core Turbo: The frequency the processor should run when all cores are loaded during the specified turbo time and limits
- Turbo Boost 2.0: The frequency every core can reach when run with a full load in isolation during turbo time
- Turbo Boost Max 3.0: The frequency a favored core can reach when run with a full load in isolation during turbo time
- Thermal Velocity Boost: The +100 MHz boost given to a core when run with a full load and is below the specified temperature (70ºC for Comet Lake) during turbo time
- Intel TVB All-Core: The frequency the processor should run when all cores are loaded during the specified turbo time and limits and is below the specified temperature (70ºC for Comet Lake) during turbo time
Even when speaking with a number of my industry peers, the way this has all been described makes it very complex and difficult to explain to each other sometimes, let alone non-technical users. It can be quite complex to explain to a friend why they are not seeing the maximum turbo frequency on the box for their system due to specified thermal windows that are not being achieved, or why the turbo might not last as long.
For the case of the Core i9 parts, Intel’s Thermal Velocity Boost (TVB) limits for the i9-10900K are 5.3 GHz single core, 4.9 GHz all-core, and after the turbo budget is used, the CPU will operate somewhere above the base clock of 3.7 GHz. If the processor is above 70ºC, then TVB is disabled, and users will get 5.2 GHz on two favored cores (or 5.1 GHz for other cores), leading to 4.8 GHz all-core, until the turbo budget is used and then back to somewhere above the base clock of 3.7 GHz.
With all these qualifiers, it gets very complicated to understand exactly what frequency you might get from a processor. In order to get every last MHz out of the silicon, these additional qualifiers mean that users will have to pay more attention to the thermal demands of the system, airflow, but also the motherboard.
As explained in many of our other articles, motherboard manufacturers have the option to disregard Intel’s turbo limit recommendations completely. This cannot be overstated enough – at least one of my colleagues had issues with a motherboard implementing a different turbo profile than Intel’s suggested recommendations. This is because with an appropriately built motherboard, a manufacturer might enforce an all-core 5.1-5.3 GHz scenario with the i9-10900K, regardless of the temperature, for an unlimited time – if the user can cool it sufficiently. Intel states that the Core i9-10900K has a peak turbo power around 250 W, however motherboard manufacturers earlier this year told us they were building boards for 320-350 W turbo power to give additional thermal headroom or in the event that the 250 W suggestion is completely ignored. Choosing a motherboard just got more complex if a user wants the best out of their new Comet Lake processor.
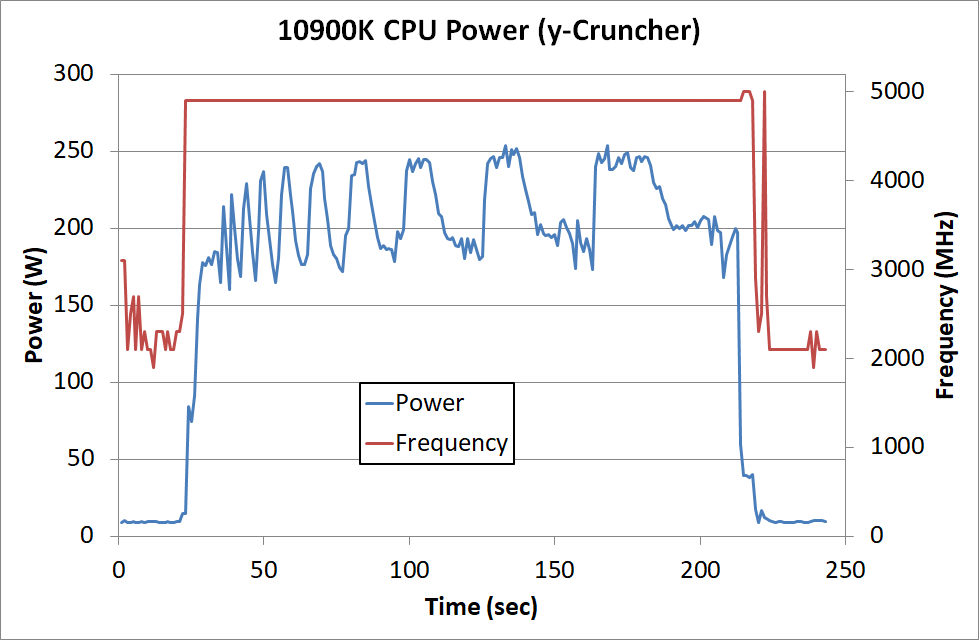
For example, here is an output from our y-Cruncher test, which uses an AVX2 optimized code path. We see that the Core i9-10900K boosts uses up to 254 W at peak moments, but through the whole test it uses 4.9 GHz for ~175 seconds. Intel's turbo has a recommended length of 56 seconds according to the specification sheets, and on our test system here, the motherboard manfuacturer is confident that its power delivery can support a longer-than-56 second turbo time. This is all above board according to Intel, as they recommend that motherboard vendors apply what they think is best for the product they have built. It only becomes out of specification if an overclock is applied - Intel does not consider this an overclock.
Beyond the standard Core i9 parts, it’s worth pointing out the low power processors, such as the Core i9-10900T. This processor has a TDP of 35 W, and a base frequency of 1.9 GHz, but can turbo all cores up to 3.7 GHz. Here’s a reminder that the power consumed while in turbo mode can go above the TDP, into the turbo power state, which can be 250 W to 350 W. I’ve asked Intel for a sample of the processor, as this is going to be a key question for the chips that have a strikingly low TDP.
It’s worth noting that only the Core i9 parts have Intel Thermal Velocity Boost. The Core i7 hardware and below only have Turbo Max 3.0 ‘favored core’ arrangements. We’ve clarified with Intel that the favored core drivers have been a part of Windows 10 since 1609, and have been mainlined into the Linux kernel since January 2017.
With the F processors, the ones without integrated graphics, the price saving seems to be lower for Core i9 than for any other of Intel’s segments. The cost difference per-unit between the 10900K and 10900KF is only $16, whereas the 10700 and 10700F is $25.
This Review
For this review, we managed to secure three processors for testing: the Core i9-10900K, the Core i7-10700K, and the Core i5-10600K. These three 125 W processors represent the overclocking parts from each of the main categories (there is no overclockable Core i3 this generation).
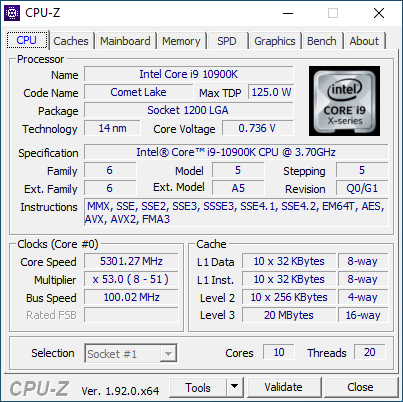
We tested all three processors in the ASRock Z490 PG Velocita, and the only serious issue experienced was an error completely on my part – I got fluff in the socket when changing processors. The ASRock board and all three CPUs cruised through our test-suites.
All three CPUs are based on the 10 core silicon dies (more on the next page), which lead to some interesting core-to-core latencies which we’ll go into. Unlike some of Intel’s previous parts, we had no issues hitting the Thermal Velocity Boost on the Core i9-10900K, as show in the CPU-Z screenshot with 5.3 GHz being registered. It does look like that most motherboards are ignoring Intel’s TVB completely, and making those numbers the new Turbo Boost Max 3.0 – both our system and our colleagues at other Future publications saw similar with their motherboards tested.
Elephant in the Room
As mentioned, 10th Gen Comet Lake is, by and large, the same CPU core design as 6th Gen Skylake from 2015. This is, for lack of a better explanation, Skylake++++ built on 14++. Aside from increasing the core count, the frequency, the memory support, some of the turbo responses, and enabling more voltage/frequency customization (more on the next page), there has been no significant increase in IPC from Intel all while AMD has gone from Excavator to Zen to Zen 2, with sizable IPC increases and efficiency improvements. With Intel late on 10nm, Comet Lake does feel like another hold-over until Intel can either get its 10nm process right for the desktop market or backport its newer architectures to 14nm; so Intel should be trying its best to avoid a sixth generation of the same core design after this. Comet Lake is still aiming to carve a spot in the market, with the main marketing materials from Intel promising the best gaming experience.

Despite Intel telling us over the previous years that ‘mega-tasking’ is the new buzzword for demanding software running simultaneously on an enthusiast system, with Comet Lake the messaging is back to one purpose – offering the best single-threaded gaming experience. We know that AMD’s Zen 2 has as a slight 10-15% IPC advantage over 9th Gen Coffee Lake, so it will be interesting to see if Intel’s 10% peak frequency advantage affords many benefits. We’ll be keeping an eye on that power consumption too, something that Intel users have chastised AMD hardware for in the past.
Socket, Silicon, Security
Editor's note: this page is mostly a carbon copy of our deep-dive covering the Comet Lake 10th Gen announcement, with some minor tweaks as new information has been obtained.
The new CPUs have the LGA1200 socket, which means that current 300-series motherboards are not sufficient, and users will require new LGA1200 motherboards. This is despite the socket being the same size. Also as part of the launch, Intel provided us with a die shot:
It looks very much like an elongated Comet Lake chip, which it is. Intel have added two cores and extended the communication ring between the cores. This should have a negligible effect on core-to-core latency which will likely not be noticed by end-users. The die size for this chip should be in the region of ~200 mm2, based on previous extensions of the standard quad core die:
CFL 4C die: 126.0 mm2
CFL 6C die: 149.6 mm2
CFL 8C die: 174.0 mm2
CML 10C die: ~198.4 mm2

Original 7700K/8700K die shots from Videocardz
Overall, Intel is using the new 10C silicon for the ten core i9 parts, as well as for the eight core i7 parts where those get dies with two cores disabled. Meanwhile for the six core i5 parts, Intel is apparently using a mix of two dies. The company has a native 6C Comet Lake-S design, but they're also using harvested dies as well. At this point it appears that the K/KF parts – the i5-10600K and i5-10600KF – get the harvested 10C design, while all of the rest of the i5s and below get the native 6C design.
For security, Intel is applying the same modifications it had made to Coffee Lake, matching up with the Cascade Lake and Whiskey Lake designs.
| Spectre and Meltdown on Intel | ||||||
| AnandTech | Comet Lake |
Coffee Refresh |
Cascade Lake | Whiskey Lake |
||
| Spectre | Variant 1 | Bounds Check Bypass | OS/VMM | OS/VMM | OS/VMM | OS/VMM |
| Spectre | Variant 2 | Branch Target Injection | Firmware + OS | Firmware + OS | Hardware + OS | Firmware + OS |
| Meltdown | Variant 3 | Rogue Data Cache Load | Hardware | Hardware | Hardware | Hardware |
| Meltdown | Variant 3a | Rogue System Register Read | Microcode Update | Firmware | Firmware | Firmware |
| Variant 4 | Speculative Store Bypass | Hardware + OS | Firmware + OS | Firmware + OS | Firmware + OS | |
| Variant 5 | L1 Terminal Fault | Hardware | Hardware | Hardware | Hardware | |
Box Designs
Intel has again chanced the box designs for this generation. Previously the Core i9-9900K/KS came in a hexagonal presentation box – this time around we get a window into the processor.

There will be minor variations for the unlocked versions, and the F processors will have ‘Discrete Graphics Required’ on the front of the box as well.
Die Thinning
One of the new features that Intel is promoting with the new Comet Lake processors is die thinning – taking layers off of the silicon and in response making the integrated heat spreader thicker in order to enable better thermal transfer between silicon and the cooling. Because modern processors are ‘flip-chips’, the bonding pads are made at the top of the processor during manufacturing, then the chip is flipped onto the substrate. This means that the smallest transistor features are nearest the cooling, however depending on the thickness of the wafer means that there is potential, with polishing to slowly remove silicon from this ‘rear-end’ of the chip.

In this slide, Intel suggests that they apply die thinning to products using STIM, or a soldered thermal interface. During our briefing, Intel didn’t mention if all the new processors use STIM, or just the overclockable ones, and neither did Intel state if die thinning was used on non-STIM products. We did ask how much the die is thinned by, however the presenter misunderstood the question as one of volume (?). We’re waiting on a clearer answer.
Overclocking Tools and Overclocking Warranties
For this generation, Intel is set to offer several new overclocking features.
First up is allowing users to enable/disable hyperthreading on a per-core basis, rather than a whole processor binary selection. As a result, users with 10 cores could disable HT on half the cores, for whatever reason. This is an interesting exercise mostly aimed at extreme overclockers that might have single cores that perform better than others, and want to disable HT on that specific core.
That being said, an open question exists as to whether the operating system is set up to identify if individual cores have hyperthreads or not. Traditionally Windows can determine if a whole chip has HT or not, but we will be interested to see if it can determine which of my threads on a 10C/15T setup are hyperthreads or not.

Also for overclocking, Intel has enabled in the specification new segmentation and timers to allow users to overclock both the PCIe bus between CPU and add-in cards as well as the DMI bus between the CPU and the chipset. This isn’t strictly speaking new – when processors were driven by FSB, this was a common element to that, plus the early Sandy Bridge/Ivy Bridge core designs allowed for a base frequency adjustment that also affected PCIe and DMI. This time around however, Intel has separated the PCIe and DMI base frequencies from everything else, allowing users to potentially get a few more MHz from their CPU-to-chipset or CPU-to-GPU link.
The final element is to do with voltage/frequency curves. Through Intel’s eXtreme Tuning Utility (XTU) and other third party software that uses the XTU SDK, users can adjust the voltage/frequency curve for their unlocked processor to better respond to requests for performance. For users wanting a lower idle power, then the voltage during idle can be dropped for different multiplier offsets. The same thing as the CPU ramps up to higher speeds.
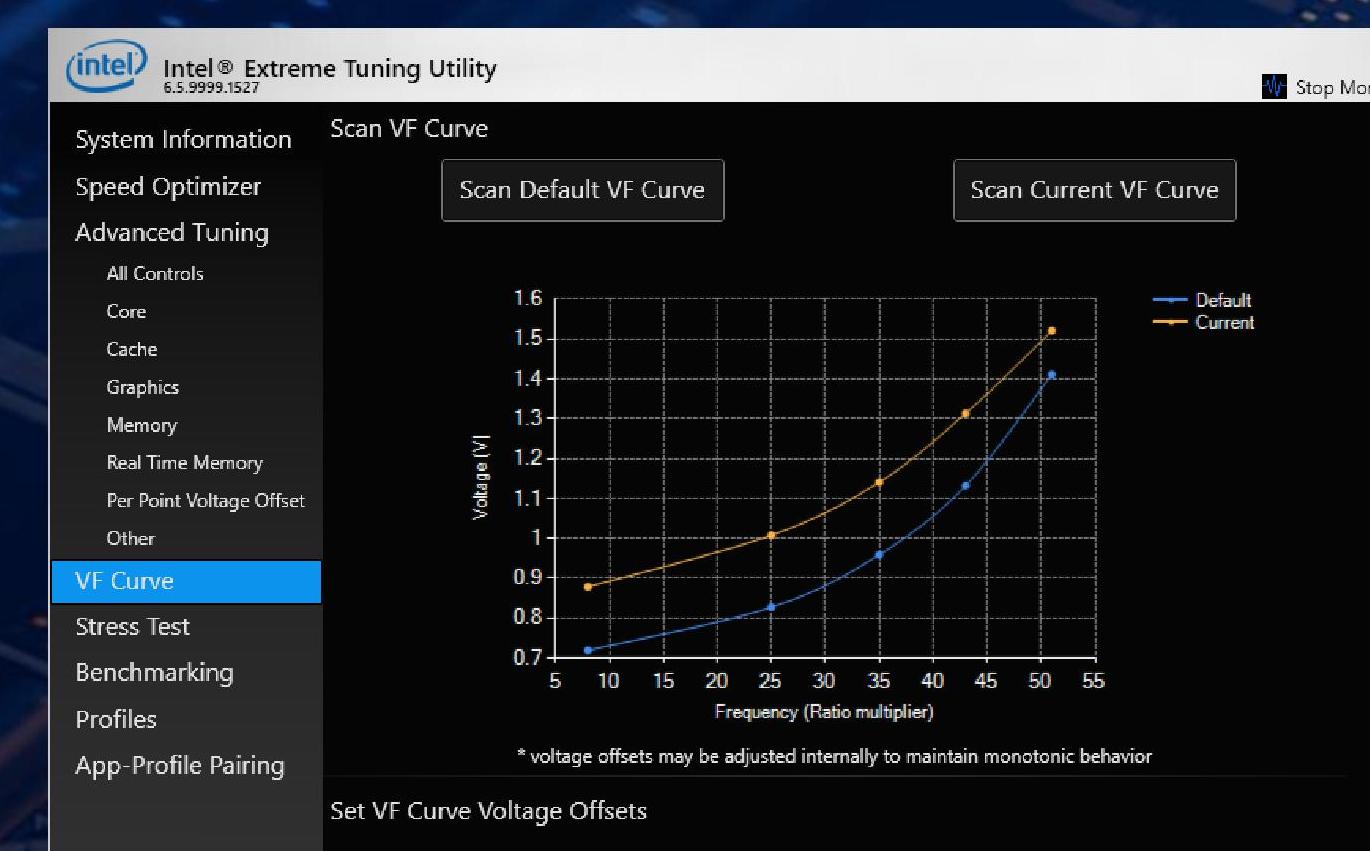
It will be interesting to see the different default VF curves that Intel is using, in case they are per-processor, per-batch, or just generic depending on the model number. Note that the users also have to be mindful of different levels of stability when the CPU goes between different frequency states, which makes it a lot more complicated than just a peak or all-core overclock.
On the subject of overclocking warranties, even though Intel promotes the use of overclocking, it isn’t covered by the standard warranty. (Note that motherboard manufacturers can ignore the turbo recommendations from Intel and the user is still technically covered by warranty, unless the motherboard does a technical overclock on frequency.) Users who want to overclock and obtain a warranty can go for Intel’s Processor Protection Plans, which will still be available.
Motherboards, Z490, and PCIe 4.0 ??
Due to the use of the new socket, Intel is also launching a range of new motherboard chipsets, including Z490, B460, and H470. We have a separate article specifically on those, and there are a small number of changes compared to the 300 series.

The two key features that Intel is promoting to users is support for Intel’s new 2.5 GbE controller, the I225-V, in order to drive 2.5 gigabit Ethernet adoption. It still requires the motherboard manufacturer to purchase the chip and put it on the board, and recent events might make that less likely – recent news has suggested that the first generation of the I225 silicon is not up to specification, and certain connections might not offer full speed. As a result Intel is introducing new B2 stepping silicon later this year, and we suspect all motherboard vendors to adopt this. The other new feature is MAC support for Wi-Fi 6, which can use Intel’s AX201 CNVi RF wireless controllers.

One big thing that users will want to know about is PCIe 4.0. Some of the motherboards being announced today state that they will support PCIe 4.0 with future generations of Intel products. At present Comet Lake is PCIe 3.0 only, however the motherboard vendors have essentially confirmed that Intel’s next generation desktop product, Rocket Lake, will have some form of PCIe 4.0 support.
Now it should be stated that for the motherboards that do support PCIe 4.0, they only support it on the PCIe slots and some (very few) on the first M.2 storage slot. This is because the motherboard vendors have had to add in PCIe 4.0 timers, drivers, and redrivers in order to enable future support. The extra cost of this hardware, along with the extra engineering/low loss PCB, means on average an extra $10 cost to the end-user for this feature that they cannot use yet. The motherboard vendors have told us that their designs conform to PCIe 4.0 specification, but until Intel starts distributing samples of Rocket Lake CPUs, they cannot validate it except to the strict specification. (This also means that Intel has not distributed early Rocket Lake silicon to the MB vendors yet.)
So purchasing a Z490 motherboard with PCIe 4.0 costs users more money, and they cannot use it at this time. It essentially means that the user is committing to upgrading to Rocket Lake in the future. Personally I would have preferred it if vendors made the current Z490 motherboards be the best Comet Lake variants they could be, and then with a future chipset (Z590?), make those the best Rocket Lake variants they could be. We will see how this plays out, given that some motherboard vendors are not being completely open with their PCIe 4.0 designs.
Test Bed and Setup
As per our processor testing policy, we take a premium category motherboard suitable for the socket, and equip the system with a suitable amount of memory running at the manufacturer's maximum supported frequency. This is also typically run at JEDEC subtimings where possible. It is noted that some users are not keen on this policy, stating that sometimes the maximum supported frequency is quite low, or faster memory is available at a similar price, or that the JEDEC speeds can be prohibitive for performance. While these comments make sense, ultimately very few users apply memory profiles (either XMP or other) as they require interaction with the BIOS, and most users will fall back on JEDEC supported speeds - this includes home users as well as industry who might want to shave off a cent or two from the cost or stay within the margins set by the manufacturer. Where possible, we will extend out testing to include faster memory modules either at the same time as the review or a later date.
| Test Setup | |
| Intel Core 10th Gen | Intel Core i9-10900K Intel Core i7-10700K Intel Core i5-10600K |
| Motherboard | ASRock Z490 PG Velocita (P1.30a) |
| CPU Cooler | TRUE Copper (2kg) |
| DRAM | Corsair Vengeance RGB 4x8GB DDR4-2933 Corsair Vengeance RGB 4x8GB DDR4-2666 |
| GPU | Sapphire RX 460 2GB (CPU Tests) MSI GTX 1080 Gaming 8G (Gaming Tests) |
| PSU | Corsair AX860i |
| SSD | Crucial MX500 2TB |
| OS | Windows 10 1909 |
Please note we are still using our 2019 gaming test suite for CPU reviews with a GTX 1080. We are in the process of rewriting our gaming test suite with some new tests, such as Borderlands and Gears Tactics, as well as changing the settings we test and moving up to an RTX 2080 Ti. It's going to take a while to do regression testing for our gaming suite, so please bear with us.
Many thanks to...
We must thank the following companies for kindly providing hardware for our multiple test beds. Some of this hardware is not in this test bed specifically, but is used in other testing.
| Hardware Providers | |||
| Sapphire RX 460 Nitro | MSI GTX 1080 Gaming X OC | Crucial MX200 + MX500 SSDs |
Corsair AX860i + AX1200i PSUs |
 |
 |
 |
 |
| G.Skill RipjawsV, SniperX, FlareX |
Crucial Ballistix DDR4 |
Silverstone Coolers |
Silverstone Fans |
 |
 |
 |
 |
Scale Up vs Scale Out: Benefits of Automation
One comment we get every now and again is that automation isn’t the best way of testing – there’s a higher barrier to entry, and it limits the tests that can be done. From our perspective, despite taking a little while to program properly (and get it right), automation means we can do several things:
- Guarantee consistent breaks between tests for cooldown to occur, rather than variable cooldown times based on ‘if I’m looking at the screen’
- It allows us to simultaneously test several systems at once. I currently run five systems in my office (limited by the number of 4K monitors, and space) which means we can process more hardware at the same time
- We can leave tests to run overnight, very useful for a deadline
- With a good enough script, tests can be added very easily
Our benchmark suite collates all the results and spits out data as the tests are running to a central storage platform, which I can probe mid-run to update data as it comes through. This also acts as a mental check in case any of the data might be abnormal.
We do have one major limitation, and that rests on the side of our gaming tests. We are running multiple tests through one Steam account, some of which (like GTA) are online only. As Steam only lets one system play on an account at once, our gaming script probes Steam’s own APIs to determine if we are ‘online’ or not, and to run offline tests until the account is free to be logged in on that system. Depending on the number of games we test that absolutely require online mode, it can be a bit of a bottleneck.
Benchmark Suite Updates
As always, we do take requests. It helps us understand the workloads that everyone is running and plan accordingly.
A side note on software packages: we have had requests for tests on software such as ANSYS, or other professional grade software. The downside of testing this software is licensing and scale. Most of these companies do not particularly care about us running tests, and state it’s not part of their goals. Others, like Agisoft, are more than willing to help. If you are involved in these software packages, the best way to see us benchmark them is to reach out. We have special versions of software for some of our tests, and if we can get something that works, and relevant to the audience, then we shouldn’t have too much difficulty adding it to the suite.
Core-to-Core Latency: Issues with the Core i5
For Intel’s Comet Late 10th Gen Core parts, the company is creating two different silicon dies for most of the processor lines: one with 10 cores and one with 6 cores. In order to create the 8 and 4 core parts, different cores will be disabled. This isn’t anything new, and has happened for the best part of a decade across both AMD and Intel in order to minimize the number of new silicon designs, and also to build in a bit of redundancy into the silicon and enable most of the wafer to be sold even if defects are found.
For Comet Lake, Intel is splitting the silicon such that all 10-core Core i9 and 8-core Core i7 processors are built from the 10c die, as is perhaps expected, and the 6-core Core i5 and 4-core Core i3 processors are built from the 6c die. The only exception to these rules are the Core i5-10600K/KF processors which will use the 10-core die with four cores disabled, giving six cores total. This leads to a potential issue.
So imagine a 10c die as two columns of five cores, capped on each end by the System Agent (DRAM, IO) and Graphics, creating a ring of 12 stops that data has to go through to reach other parts of the silicon. Let us start simple, and imagine disabling two cores to make an 8c processor. It can be pretty straightforward to guess the best/worst case scenario in order to get the best/worst core-to-core latency

The other worst 8c case might be to keep Core 0 enabled, and then disable Core 1 and Core 2, leaving Core 3-9 enabled.
We can then disable four cores from the original 10 core setup. It can be any four cores, so imagine another worst case and a best case scenario.
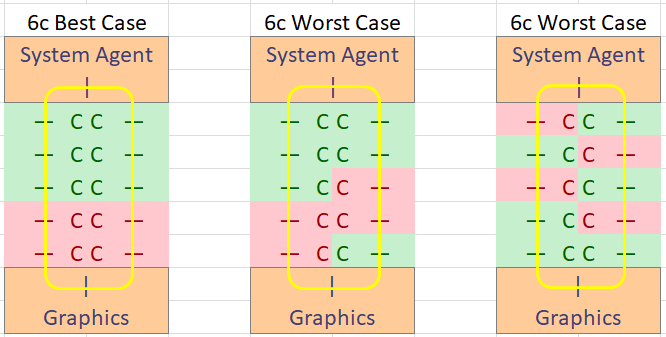
On the left we have the absolute best case arrangement that minimizes all core-to-core latency. In the middle is the absolute worst case, with any contact to the first core in the top left being a lot higher latency with more distance to travel from any core. On the right is an unbalanced design, but perhaps a lower variance in latency.
When Intel disables cores to create these 8c and 6c designs, the company has in the past promised that any disabling would leave the rest of the processor ‘with similar performance targets’, and that while different individual units might have different cores disabled, they should all fall within a reasonable spectrum.
So let us start with our Core i5-10600K core-to-core latency chart.
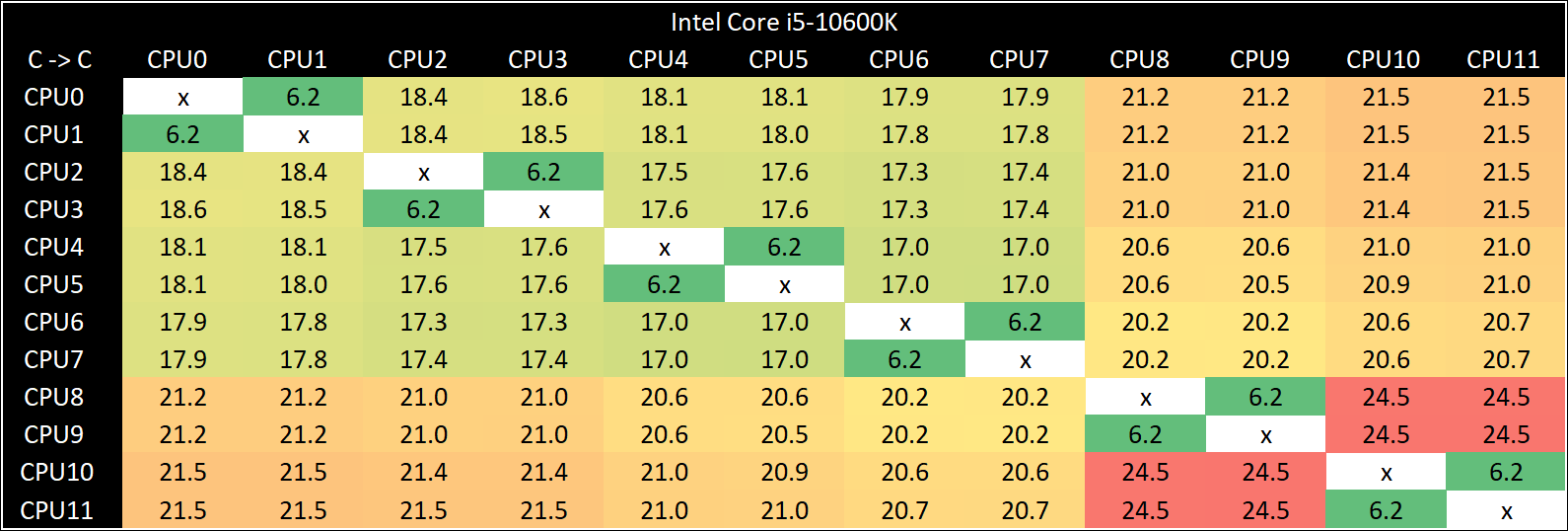
Cores next door seem well enough, then as we make longer trips around the ring, it takes about 1 nanosecond longer for each stop. Until those last two cores that is, where we get a sudden 4 nanosecond jump. It’s clear that the processor we have here as a whole is lopsided in its core-to-core latency and if any thread gets put onto those two cores at the end, there might be some questionable performance.
Now it’s very easy to perhaps get a bit heated with this result. Unfortunately we don’t have an ‘ideal’ 6c design to compare it against, which makes comparisons on performance to be a bit tricky. But it does mean that there is likely to be variation between different Core i5-10600K samples.
The effect still occurs on the 8-core Core i7-10700K, however it is less pronounced.
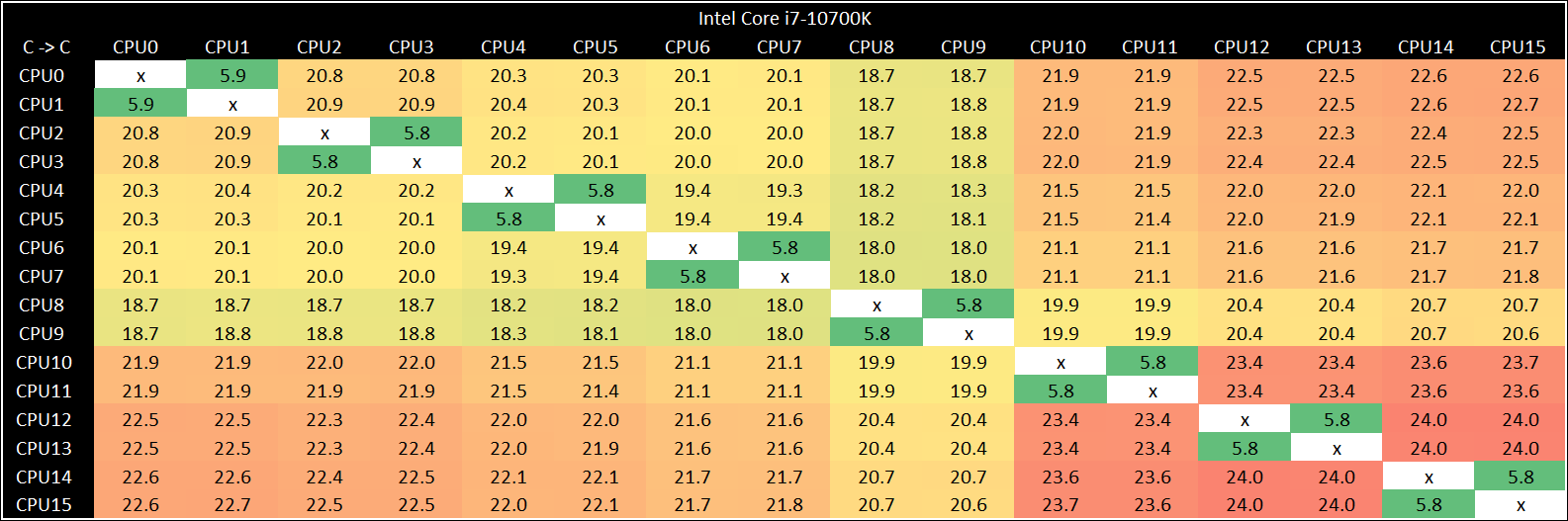
There’s still a sizeable jump between the 3 cores at the end compared to the other five cores. One of the unfortunate downsides with the test is that the enumeration of the cores won’t correspond to any physical location, so it might be difficult to narrow down the exact layout of the chip.
Moving up to the big 10-core processor yields an interesting result:
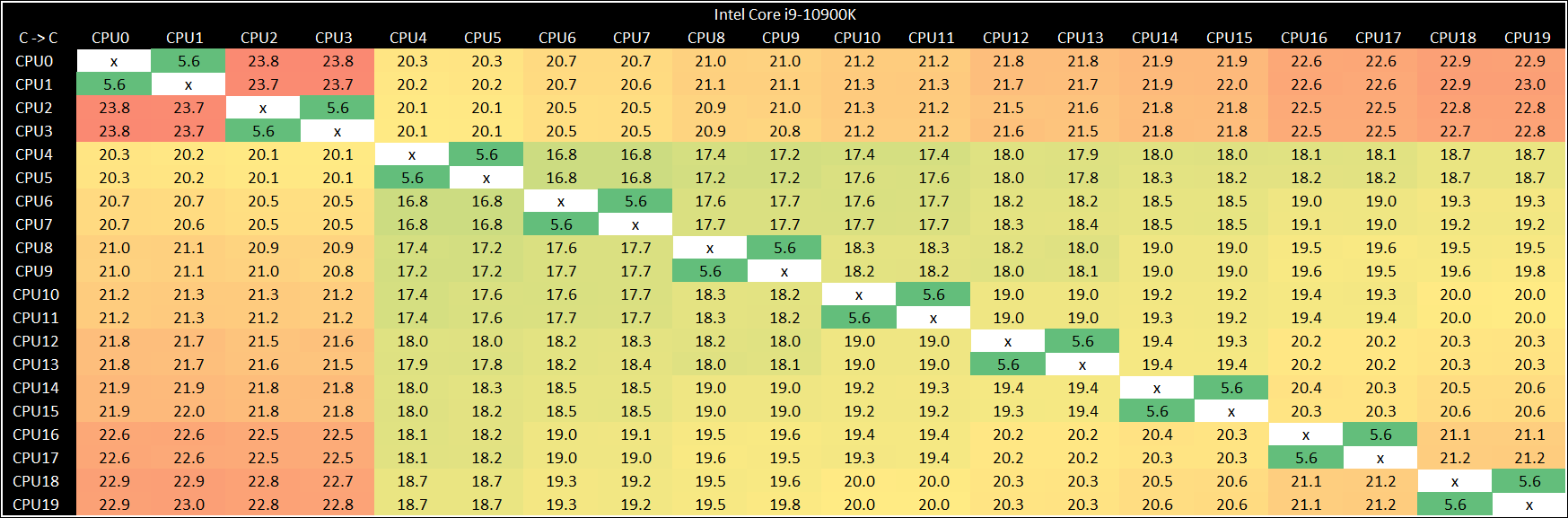
So while we should have a steadily increasing latency here, there’s still that 3-4 nanosecond jump with two of the cores. This points to a different but compounding issue.
Our best guess is that these two extra cores are not optimized for this sort of ring design in Comet Lake. For their Core lineup of processors, Intel has been using a ring bus as the principle interconnect between its cores for over a decade, and we typically see them on four and six core processors. Intel also used a ring bus in its enterprise processors for many years, with chips up to 24 cores, however those designs used dual-ring buses in order to keep core-to-core latency down. Intel has put up to 12 cores on a single ring, though broadly speaking the company seems to prefer keeping designs to 8 or fewer cores per ring.
If Intel could do it for those enterprise chips, then why not for the 10 core Comet Lake designs here? We suspect it is because the original ring design that went into consumer Skylake processors, while it was for four cores, doesn’t scale linearly as the core count increases. There is a noticeable increase in the latency as we move from four to six and six to eight core silicon designs, but a ten-core ring is just a step too far, and additional repeaters are required in the ring in order to support the larger size.
There could also be an explanation relating to these cores also having additional function on that section of the ring, such as sharing duties with IO parts of the core, or PCIe lanes, and as a result extra cycles are required for any additional cacheline transfers.
We are realistically reaching the limits of any ring-line interconnect for Intel’s Skylake consumer line processors here. If Intel were to create a 12-core version of Skylake consumer for a future processor, a single ring interconnect won’t be able to handle it without an additional latency penalty, which might be more of a penalty if the ring isn't tuned for the size. There's also a bandwidth issue, as the same ring and memory has to support more cores. If Intel continue down this path, they will either have to use dual rings, use a different interconnect paradigm altogether (mesh, chiplet), or move to a new microarchitecture and interconnect design completely.
Frequency Ramps
We also performed our frequency ramps on all three processors. Nothing much to say here – all three CPUs went from 800 MHz idle to peak frequency in 16 milliseconds, or one frame at 60 Hz. We saw the peak turbo speeds on all the parts.



Power
We kind of gave a sneak preview on the front page with our frequency graph, but the short answer as to whether these new Core i9 processors really need 250 W for 10 cores is yes. Intel sent us details on what it has determined should be the recommended settings for its K processor line:
- Core i9-10900K: TDP is 125 W, PL2 is 250 W, Tau is 56 seconds
- Core i7-10700K: TDP is 125 W, PL2 is 229 W, Tau is 56 seconds
- Core i5-10600K: TDP is 125 W, PL2 is 182 W, Tau is 56 seconds
For those not used to these terms, we have the TDP or Thermal Design Power, which is meant to be the long-term sustained power draw of the processor at which Intel guarantees the base frequency of the processor – so in this case, the Core i9-10900K guarantees that with a heavy, long-running workload it will max out at 125 W with a frequency of at least 3.7 GHz (the base frequency).
The PL2 is known as the turbo power limit, which means that while the processor is allowed to turbo, this is the upper power limit that the processor can reach. As mentioned on the first page of this review, the value for PL2 is only a suggested guide, and Intel lets motherboard vendors set this value to whatever they want based on how well the motherboard is designed. Sometimes in laptops we will see this value lower than what Intel recommends for thermal or battery reasons, however on consumer motherboards often this value is as high as it can possibly be.
The final term, Tau, is meant to be a time by which the turbo can happen. In reality the TDP value and the Tau value is multiplied together to give a value for a ‘bucket’ of energy that the processor can use to turbo with. The bucket is refilled at a continuous rate, but if there is excess energy then the processor can turbo – if the bucket is being emptied at the same rate as it is refilled, then the processor is down at the long-term TDP power limit. Again, this is a value that Intel recommends and does not fix for the vendors, and most consumer motherboards have Tau set to 999 seconds (or the equivalent of infinite time) so the processor can turbo as much as possible.
Note, when we asked Intel about why it doesn’t make these hard specifications and how we should test CPUs given that we’re somewhat enable to keep any motherboard consistent (it might change between BIOS revisions) for a pure CPU review, the response was to test a good board and a bad board. I think that on some level Intel’s engineers don’t realize how much Intel’s partners abuse the ability to set PL2 and Tau to whatever values they want.
All that aside, we did some extensive power testing on all three of our CPUs across a number of simulation and real-world benchmarks.
Core i9-10900K Power
Through our tests, we saw the Intel Core i9-10900K peak at 254 W during our AVX2-accelerated y-cruncher test. LINPACK and 3DPMavx did not push the processor as hard.
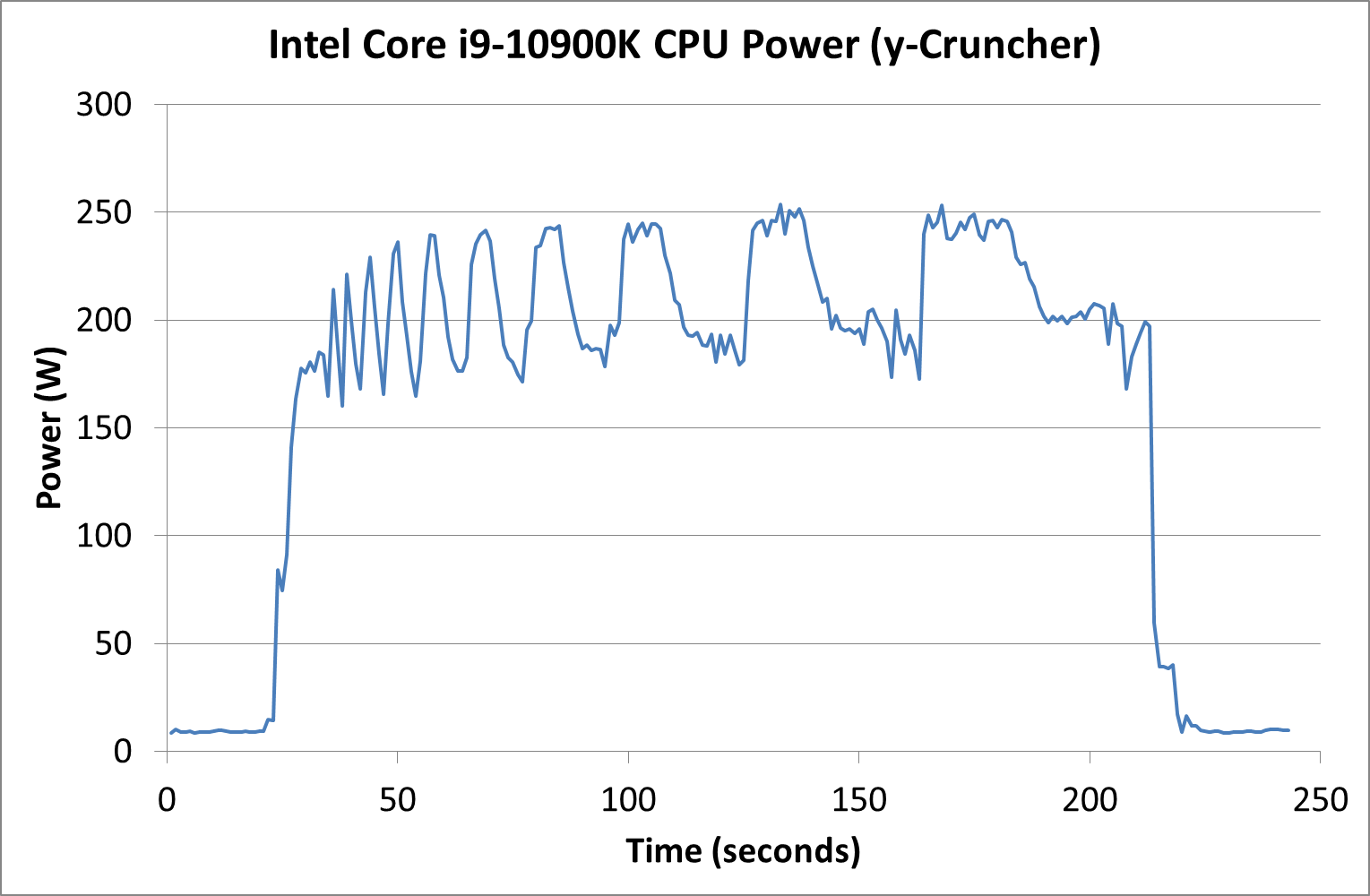
The more real-world tests, AI Benchmark and Photoscan, showed that in a variable operation workload mixing threads, we are more likely to see the 125-150 W range, with spikes up to 200W for specific operations.

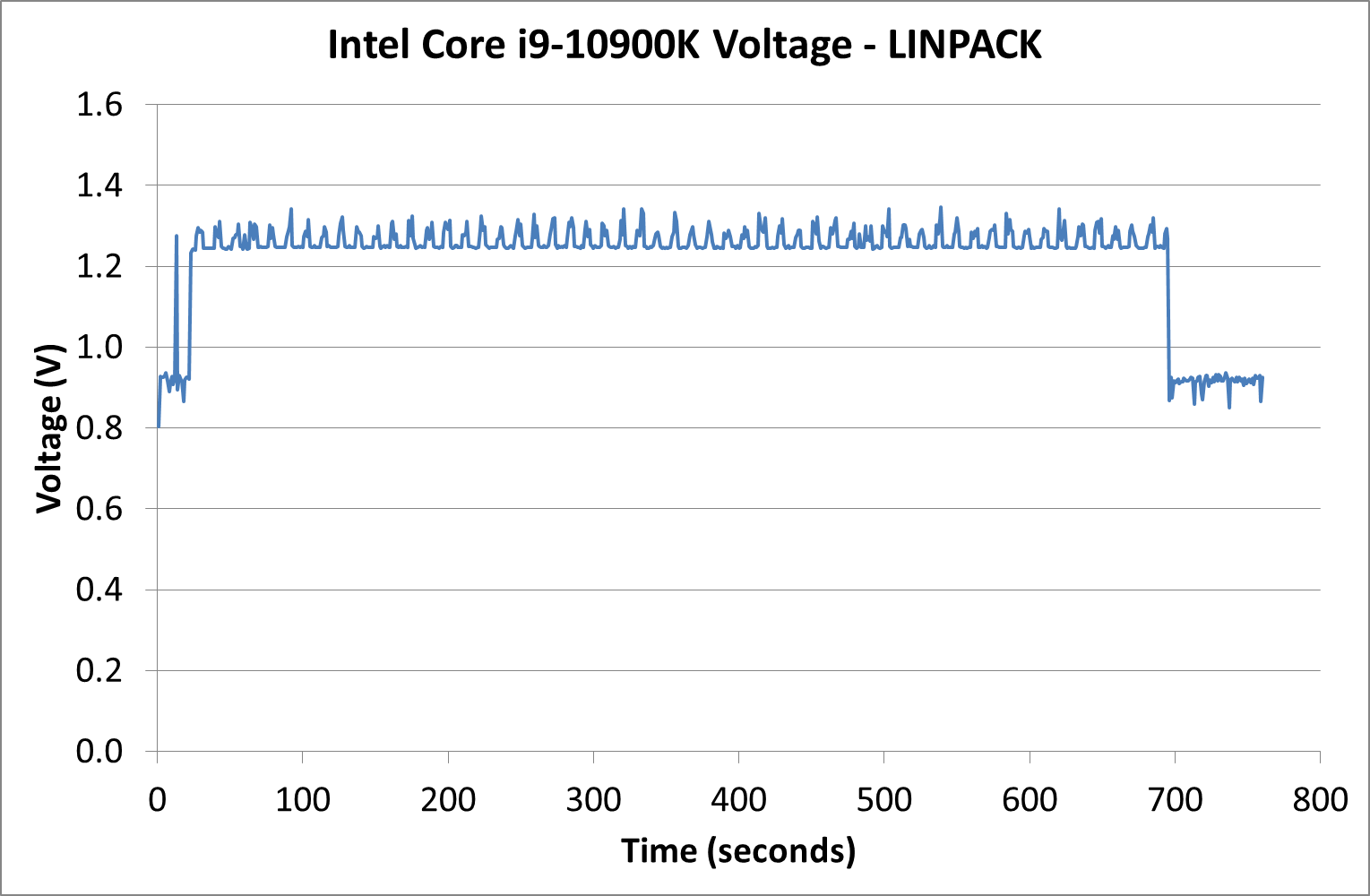
For users interested in the voltage for our Core i9-10900K, we saw the processor peak at 1.34 volts, however even during an AVX2 workload it was nearer to 1.25 volts.
Intel Core i7-10700K
The Intel Core i7-10700K is rated by Intel to have a peak turbo power of 229 W, however our sample peaked at 207 W during y-Cruncher. LINPACK achieved similar results, whereas 3DPMavx was nearer 160 W.
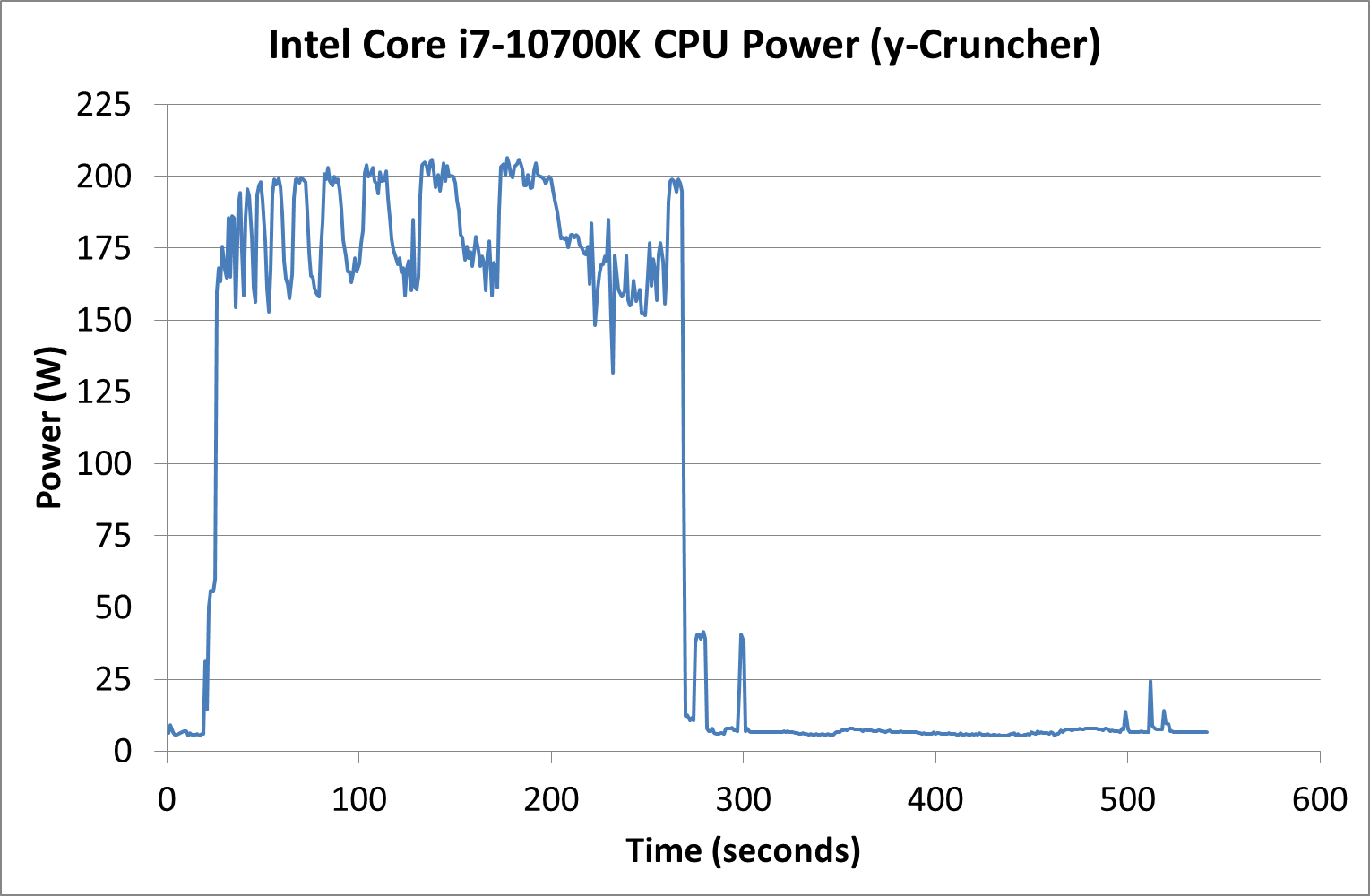
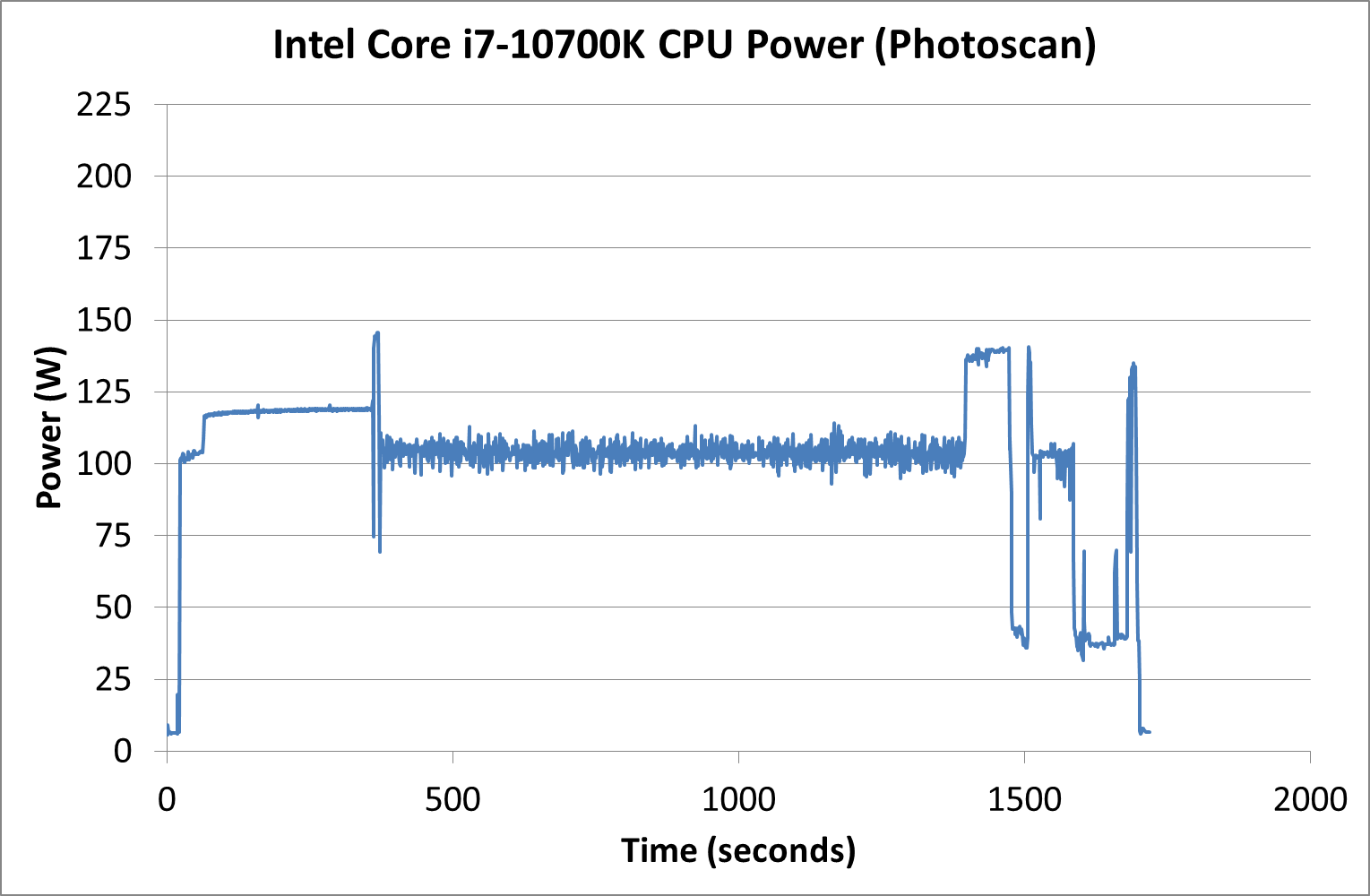
Our AI Benchmark power wrapper failed for the 10700K due to a configuration issue, but the Photoscan ‘real world’ power test put the processor mostly in the 100-125 W range, peaking just below 150 W in a couple of places.
Intel Core i5-10600K
Intel’s Core i5-10600K has a recommended PL2 of 182 W, but we observed a peak of 125 W in y-Cruncher and 131 W in LINPACK.
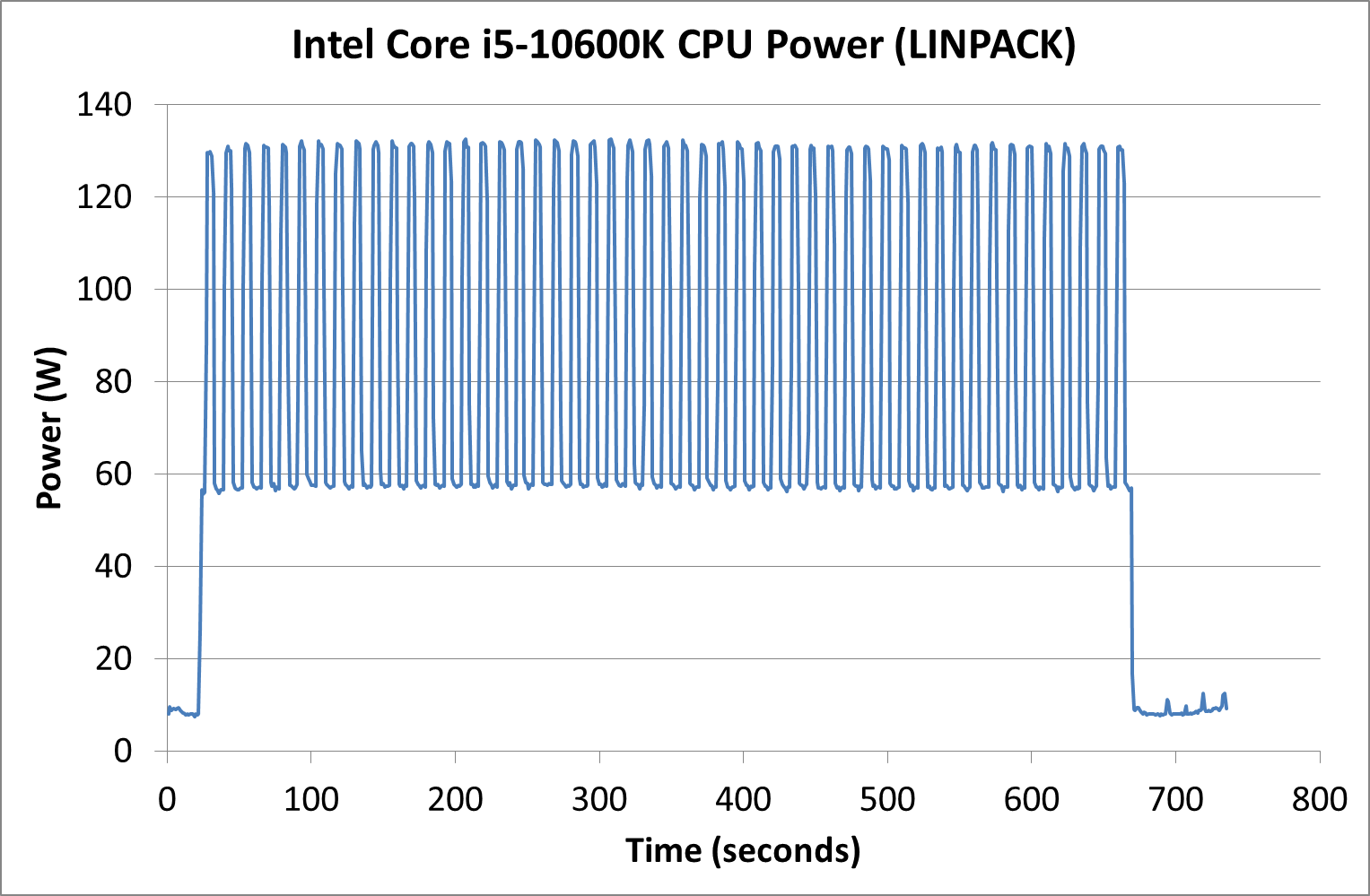
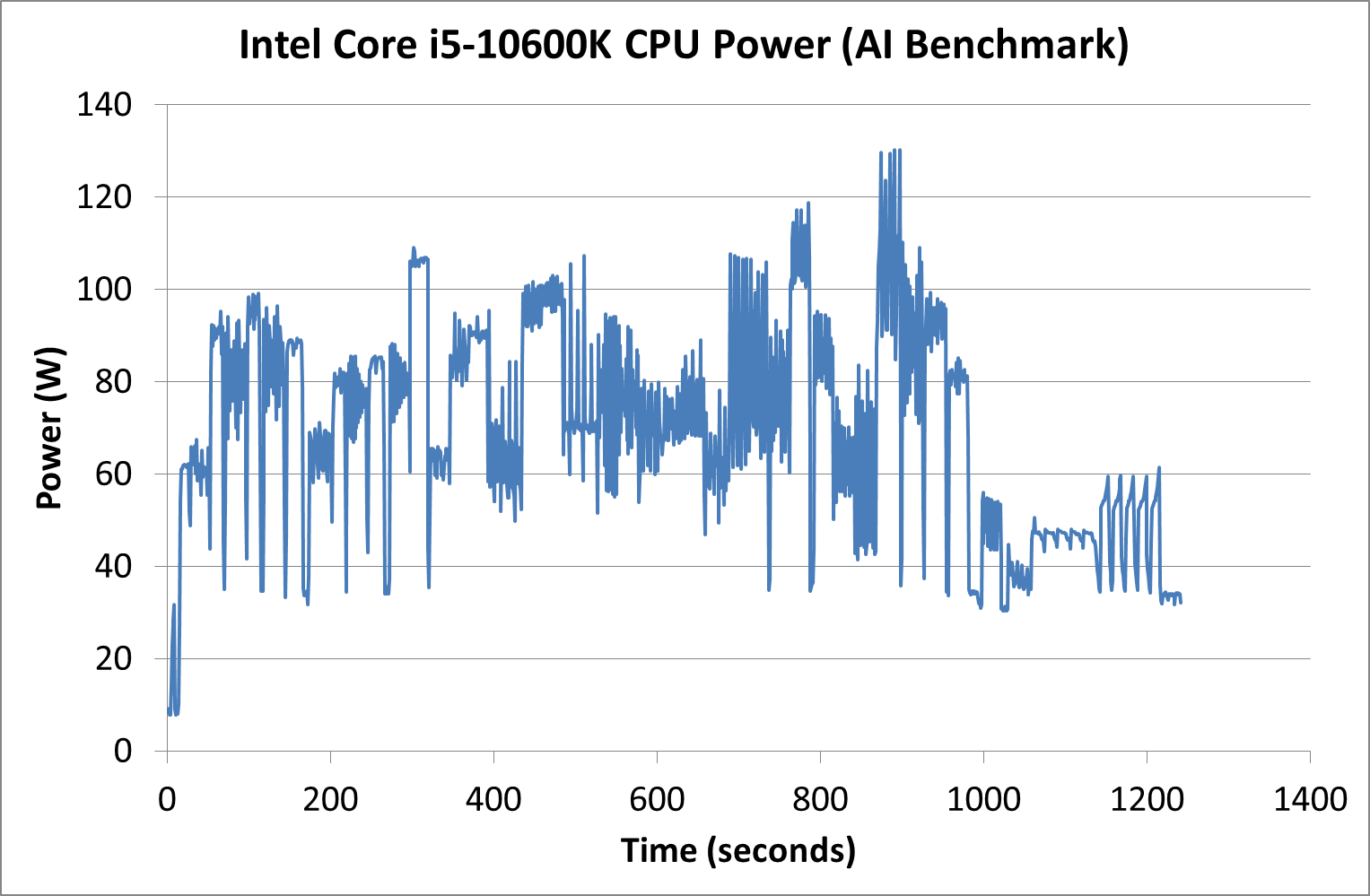
We actually saw our AI Benchmark real-world test hit 130 W as well, while Photoscan was nearer the 60-80 W range for most of the test.
The full set of power graphs can be found here:






In terms of overall peak power consumption, our values look like this:

Note, 254 W is quite a lot, and we get 10 cores at 4.9 GHz out of it. By comparison, AMD's 3990X gives 64 cores at 3.2 GHz for 280 W, which goes to show the trade-offs between going wide and going deep. Which one would you rather have?
Our Office and Science Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, artificial intelligence, and AVX accelerated code.
All of our benchmark results can also be found in our benchmark engine, Bench.
Office Tests
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.

GIMP likes fast single core performance, and so the Core i9 wins here.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

Agisoft is a mix of variable threaded workloads, so a good balanced system works best. Intel's $500 option is faster than AMD's $500 option here, with two fewer cores.
AI Benchmark
One of the longest time requests we’ve had for our benchmark suite is AI-related benchmark, and the folks over at ETH have moved their popular AI Benchmark from mobile over PC. Using Intel’s MKL and Tensorflow 2.1.0, we use version 0.1.2 of the benchmark which tests both training and inference over a variety of different models. You can read the full scope of the benchmark here.
This is one of our new tests in the database, and we are still gaining data for it.
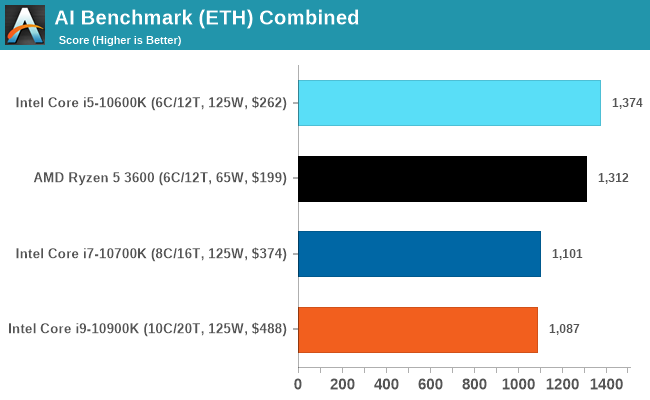
AIBench is a new test here, covering both training and inference. In the breakdown of results, we noticed that the faster processors were actually slower, scoring a lower result. We believe this is down to the lower bandwidth/core afforded by the 10c design against the 6c design.
Accelerated Science Tests
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
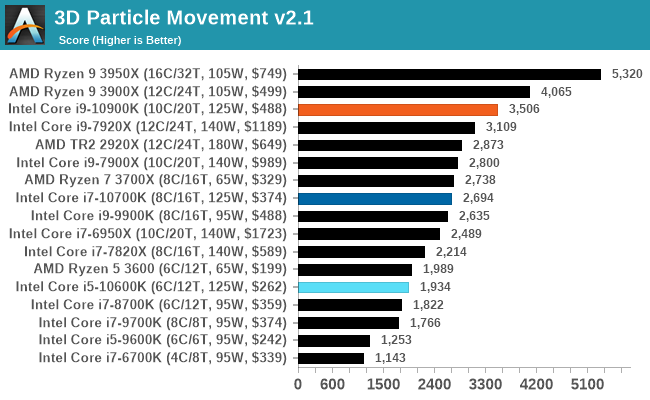
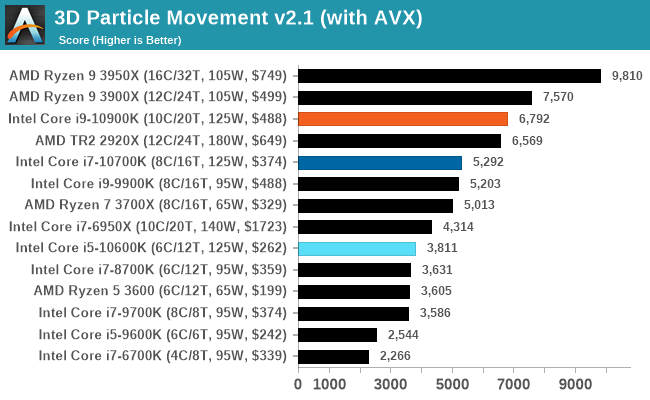
No real surprises in our 3DPM tests.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
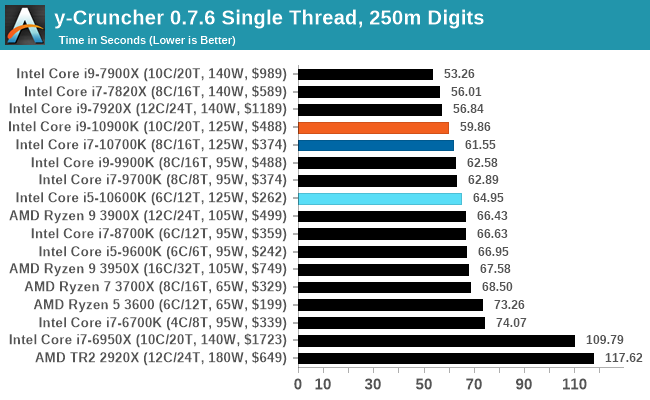
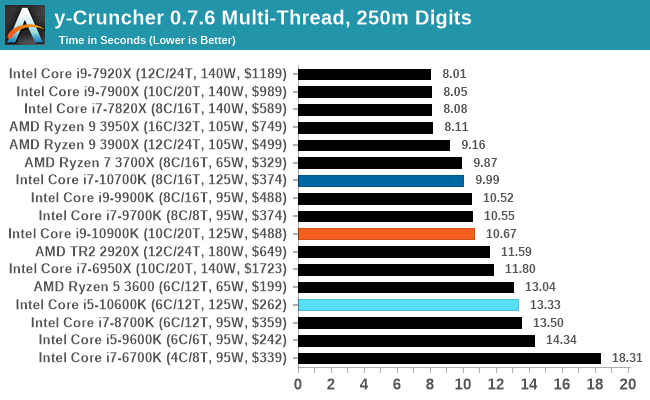
y-Cruncher is another one where the Core i9 performs worse than the Core i7 in the multithreaded test, despite being better on the single threaded test. We again put this down to memory bandwidth. We need to update this test to the latest version of y-Cruncher, which has additional optimizations for Zen 2 processors, but also to increase the digit count in our MT test.
CPU Performance: Rendering Tests
Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice.
All of our benchmark results can also be found in our benchmark engine, Bench.
Crysis CPU Render
One of the most oft used memes in computer gaming is ‘Can It Run Crysis?’. The original 2007 game, built in the Crytek engine by Crytek, was heralded as a computationally complex title for the hardware at the time and several years after, suggesting that a user needed graphics hardware from the future in order to run it. Fast forward over a decade, and the game runs fairly easily on modern GPUs, but we can also apply the same concept to pure CPU rendering – can the CPU render Crysis? Since 64 core processors entered the market, one can dream. We built a benchmark to see whether the hardware can.
For this test, we’re running Crysis’ own GPU benchmark, but in CPU render mode. This is a 2000 frame test, which we run over a series of resolutions from 800x600 up to 1920x1080. For simplicity, we provide the 1080p test here.
This is one of our new benchmarks, so we are slowly building up the database as we start regression testing older processors.
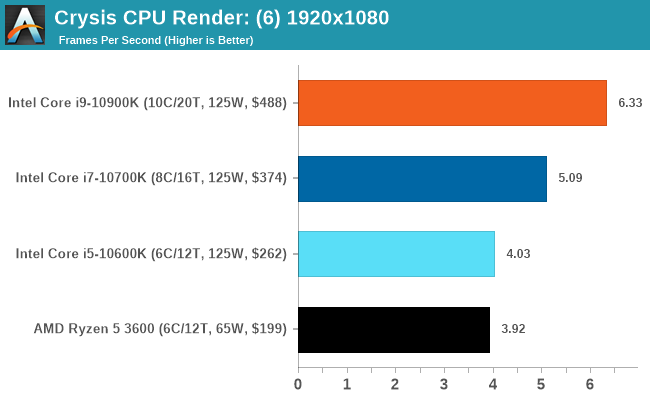
The Core i9-10900K scores 15 FPS at 800x600, which is just about playable.
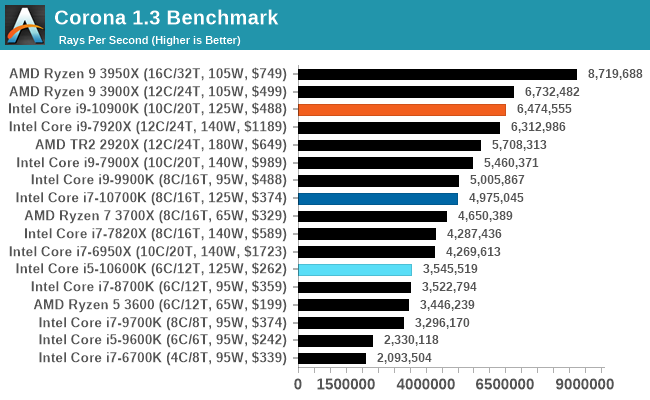
Corona 1.3: Performance Render
An advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand.
The Corona benchmark website can be found at https://corona-renderer.com/benchmark
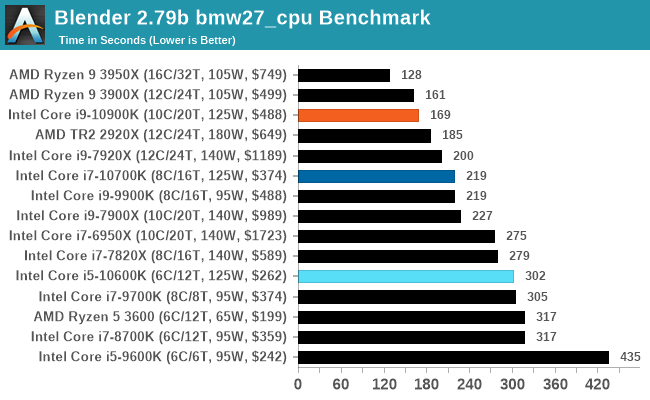
Blender 2.79b: 3D Creation Suite
A high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render.
Blender can be downloaded at https://www.blender.org/download/
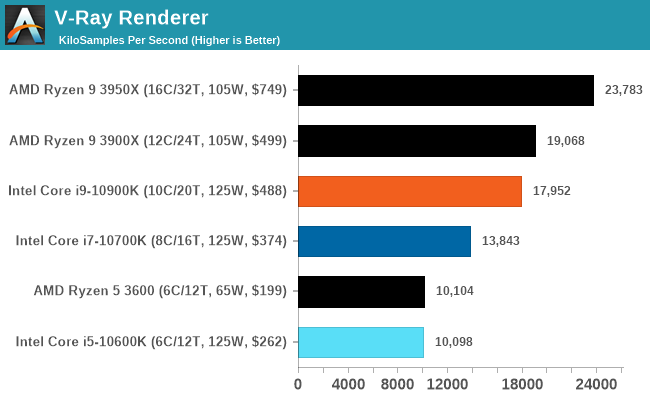
V-Ray
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
This is another one of our recently added tests.
POV-Ray 3.7.1: Ray Tracing
The Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line.
POV-Ray can be downloaded from http://www.povray.org/
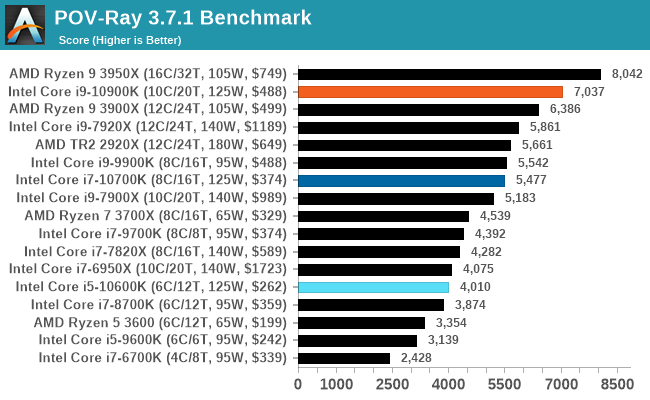
Interestingly the Core i9 with only 10C outperforms the 12C Ryzen 9 3900X here, likely due to the higher sustained frequency of the Intel chip. We clocked 220W on our Intel chip for this test however, well beyond the 120W of the AMD processor.
CPU Performance: Simulation Tests
A number of our benchmarks fall into the category of simulations, whereby we are either trying to emulate the real world or re-create systems with systems. In this set of tests, we have a variety including molecular modelling, non-x86 video game console emulation, a simulation of the equivalent of a slug brain with neurons and synapses firing, and finally a popular video game that simulates the growth of a fictional land including historical events and important characters within that world.
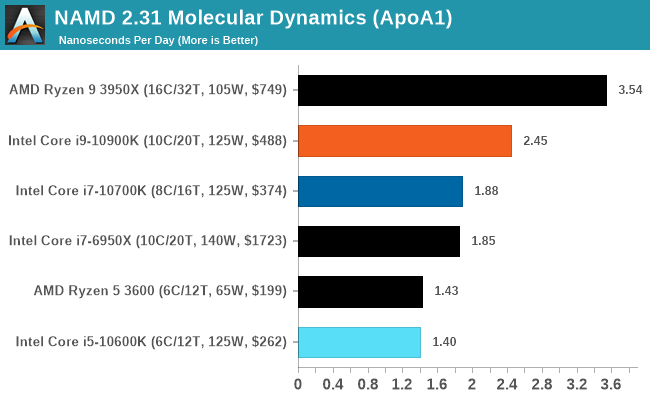
NAMD ApoA1
One frequent request over the years has been for some form of molecular dynamics simulation. Molecular dynamics forms the basis of a lot of computational biology and chemistry when modeling specific molecules, enabling researchers to find low energy configurations or potential active binding sites, especially when looking at larger proteins. We’re using the NAMD software here, or Nanoscale Molecular Dynamics, often cited for its parallel efficiency. Unfortunately the version we’re using is limited to 64 threads on Windows, but we can still use it to analyze our processors. We’re simulating the ApoA1 protein for 10 minutes, and reporting back the ‘nanoseconds per day’ that our processor can simulate. Molecular dynamics is so complex that yes, you can spend a day simply calculating a nanosecond of molecular movement.
This is one of our new tests, so we will be filling in more data as we start regression testing for older CPUs.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/

DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.
Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
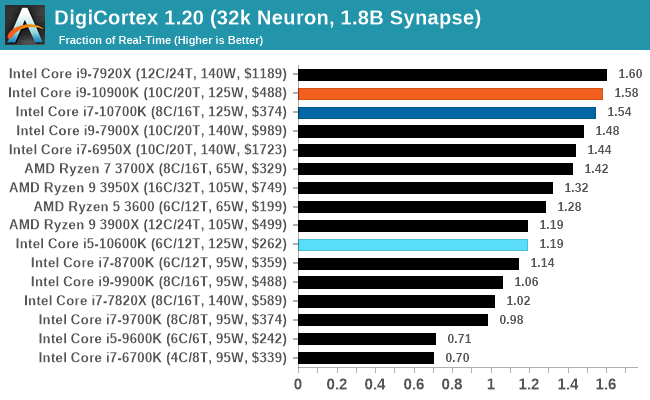
The additional bandwidth of the HEDT platforms put them higher up the chart here - Digicortex always ends up as an odd mix of bottlenecks mostly around memory, but it can be localized internal bandwidth limited as well.
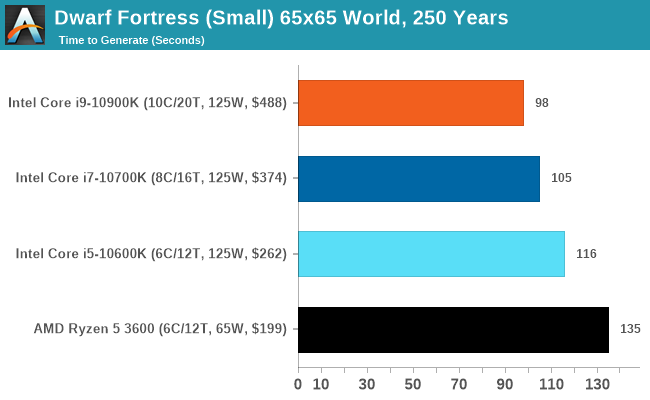
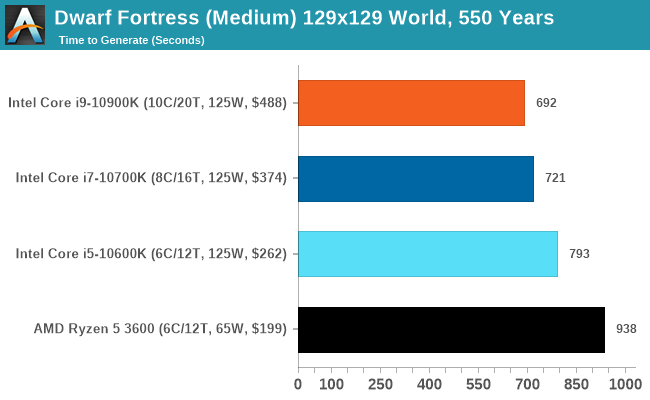
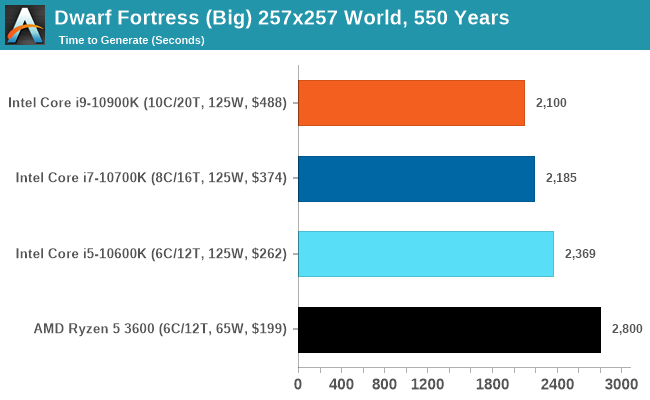
Dwarf Fortress
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006. Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes.
DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. I’ve barely scratched the surface here, but after analyzing the test, we ended up going for three different world generation sizes.
This is another of our new tests.
CPU Performance: Encoding Tests
With the rise of streaming, vlogs, and video content as a whole, encoding and transcoding tests are becoming ever more important. Not only are more home users and gamers needing to convert video files into something more manageable, for streaming or archival purposes, but the servers that manage the output also manage around data and log files with compression and decompression. Our encoding tasks are focused around these important scenarios, with input from the community for the best implementation of real-world testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
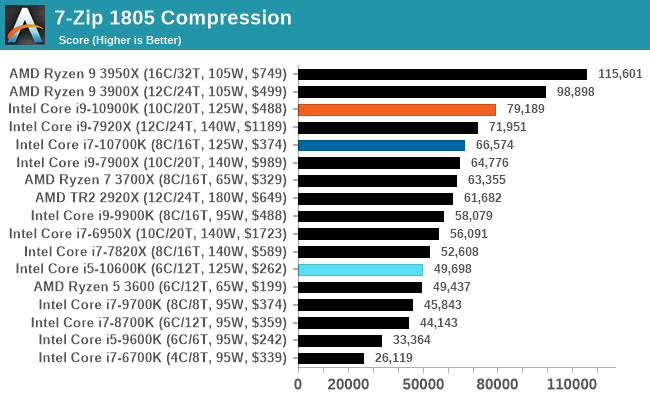
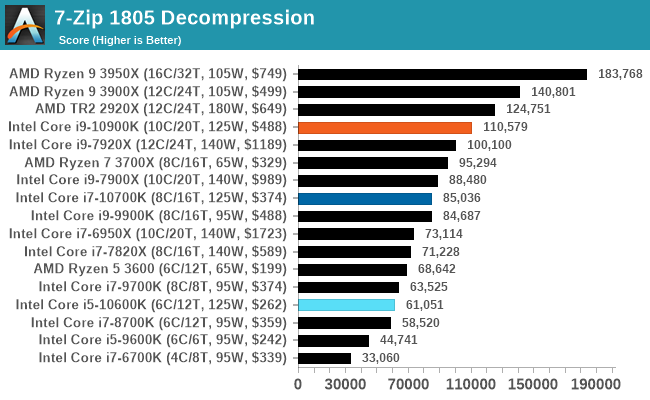
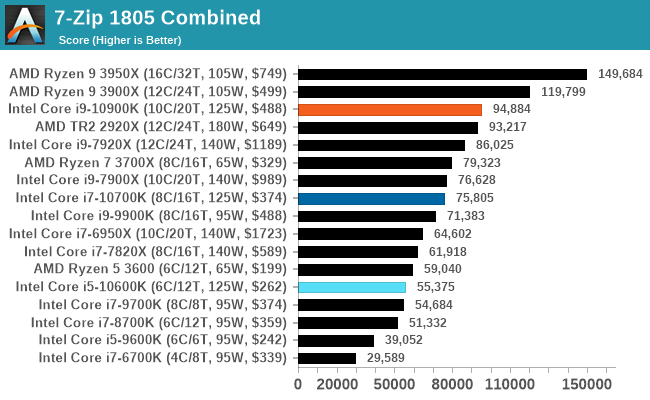
7-zip v1805: Popular Open-Source Encoding Engine
Out of our compression/decompression tool tests, 7-zip is the most requested and comes with a built-in benchmark. For our test suite, we’ve pulled the latest version of the software and we run the benchmark from the command line, reporting the compression, decompression, and a combined score.
It is noted in this benchmark that the latest multi-die processors have very bi-modal performance between compression and decompression, performing well in one and badly in the other. There are also discussions around how the Windows Scheduler is implementing every thread. As we get more results, it will be interesting to see how this plays out.
Please note, if you plan to share out the Compression graph, please include the Decompression one. Otherwise you’re only presenting half a picture.
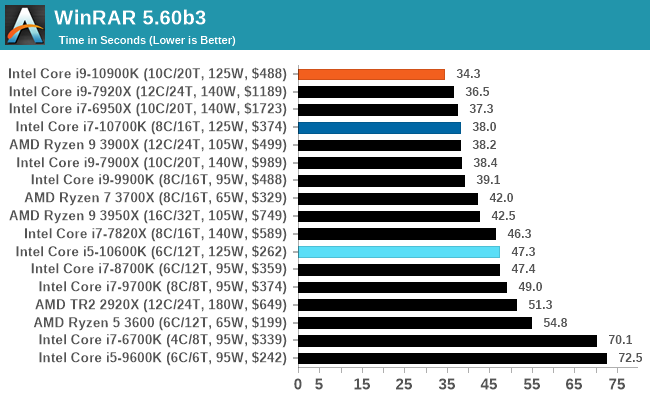
WinRAR 5.60b3: Archiving Tool
My compression tool of choice is often WinRAR, having been one of the first tools a number of my generation used over two decades ago. The interface has not changed much, although the integration with Windows right click commands is always a plus. It has no in-built test, so we run a compression over a set directory containing over thirty 60-second video files and 2000 small web-based files at a normal compression rate.
WinRAR is variable threaded but also susceptible to caching, so in our test we run it 10 times and take the average of the last five, leaving the test purely for raw CPU compute performance.
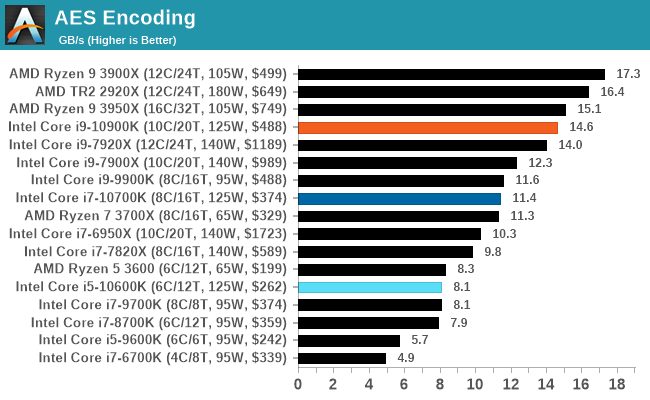
AES Encryption: File Security
A number of platforms, particularly mobile devices, are now offering encryption by default with file systems in order to protect the contents. Windows based devices have these options as well, often applied by BitLocker or third-party software. In our AES encryption test, we used the discontinued TrueCrypt for its built-in benchmark, which tests several encryption algorithms directly in memory.
The data we take for this test is the combined AES encrypt/decrypt performance, measured in gigabytes per second. The software does use AES commands for processors that offer hardware selection, however not AVX-512.
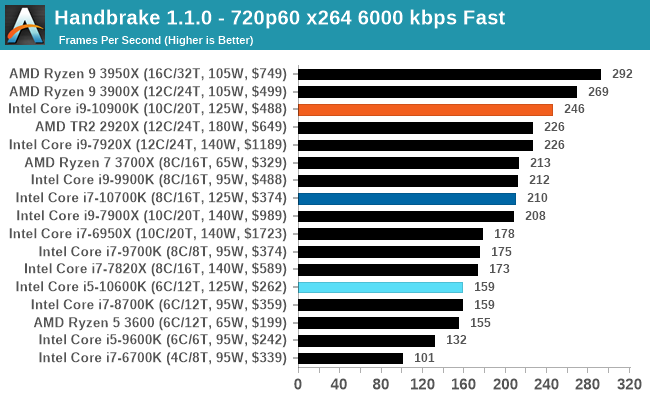
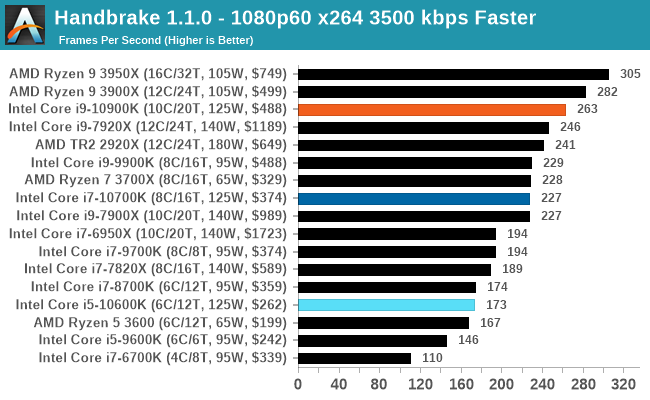
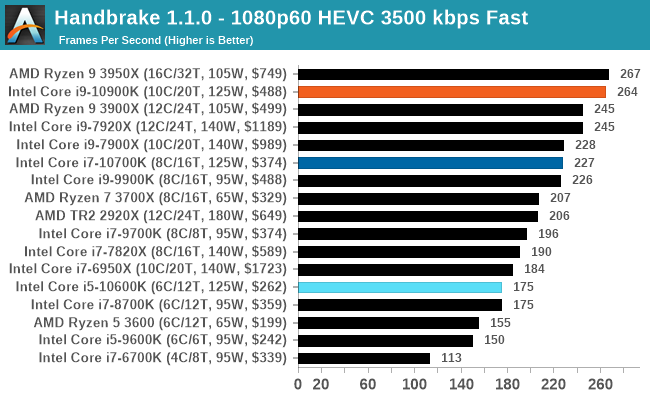
Handbrake 1.1.0: Streaming and Archival Video Transcoding
A popular open source tool, Handbrake is the anything-to-anything video conversion software that a number of people use as a reference point. The danger is always on version numbers and optimization, for example the latest versions of the software can take advantage of AVX-512 and OpenCL to accelerate certain types of transcoding and algorithms. The version we use here is a pure CPU play, with common transcoding variations.
We have split Handbrake up into several tests, using a Logitech C920 1080p60 native webcam recording (essentially a streamer recording), and convert them into two types of streaming formats and one for archival. The output settings used are:
- 720p60 at 6000 kbps constant bit rate, fast setting, high profile
- 1080p60 at 3500 kbps constant bit rate, faster setting, main profile
- 1080p60 HEVC at 3500 kbps variable bit rate, fast setting, main profile
CPU Performance: Web and Legacy Tests
While more the focus of low-end and small form factor systems, web-based benchmarks are notoriously difficult to standardize. Modern web browsers are frequently updated, with no recourse to disable those updates, and as such there is difficulty in keeping a common platform. The fast paced nature of browser development means that version numbers (and performance) can change from week to week. Despite this, web tests are often a good measure of user experience: a lot of what most office work is today revolves around web applications, particularly email and office apps, but also interfaces and development environments. Our web tests include some of the industry standard tests, as well as a few popular but older tests.
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
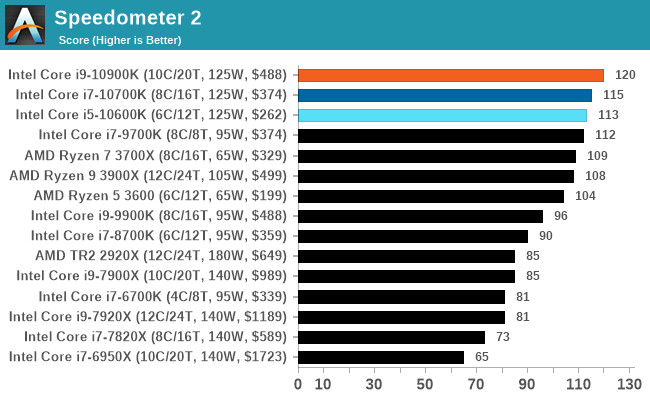
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a accrued test over a series of javascript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics. We report this final score.
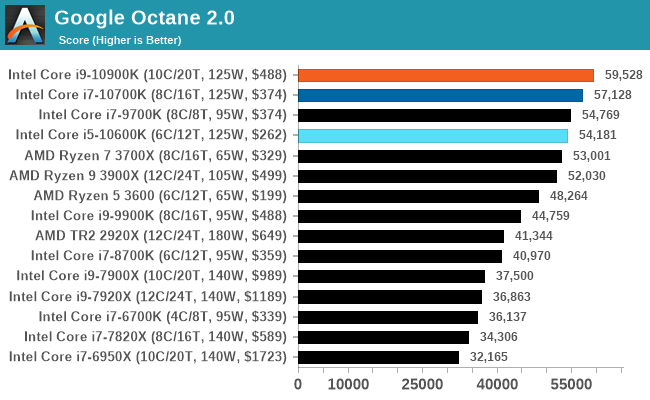
Google Octane 2.0: Core Web Compute
A popular web test for several years, but now no longer being updated, is Octane, developed by Google. Version 2.0 of the test performs the best part of two-dozen compute related tasks, such as regular expressions, cryptography, ray tracing, emulation, and Navier-Stokes physics calculations.
The test gives each sub-test a score and produces a geometric mean of the set as a final result. We run the full benchmark four times, and average the final results.
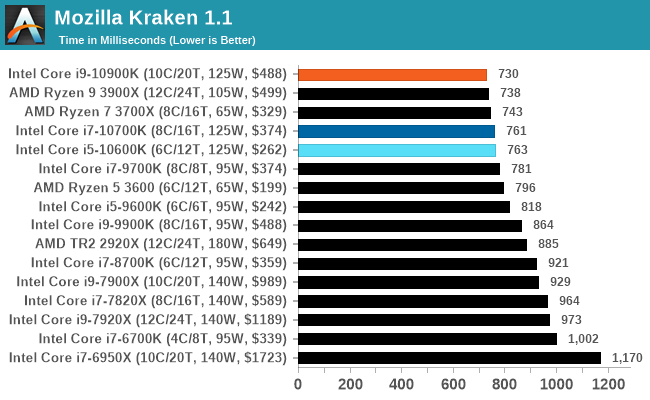
Mozilla Kraken 1.1: Core Web Compute
Even older than Octane is Kraken, this time developed by Mozilla. This is an older test that does similar computational mechanics, such as audio processing or image filtering. Kraken seems to produce a highly variable result depending on the browser version, as it is a test that is keenly optimized for.
The main benchmark runs through each of the sub-tests ten times and produces an average time to completion for each loop, given in milliseconds. We run the full benchmark four times and take an average of the time taken.
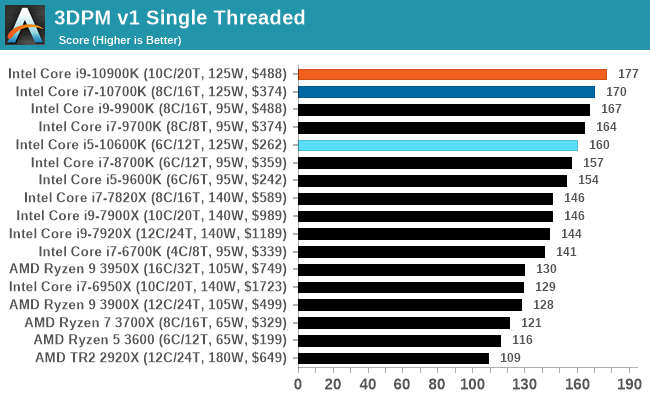
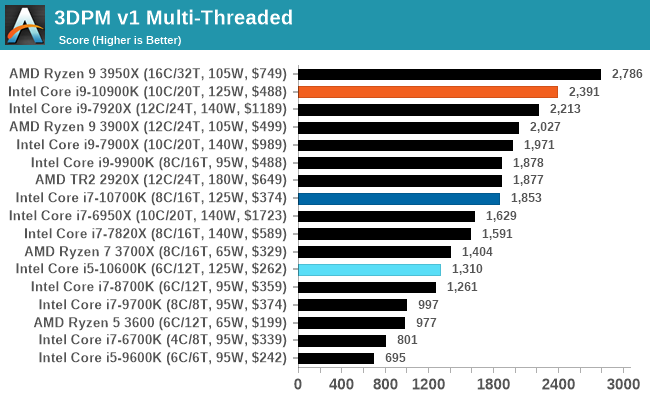
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
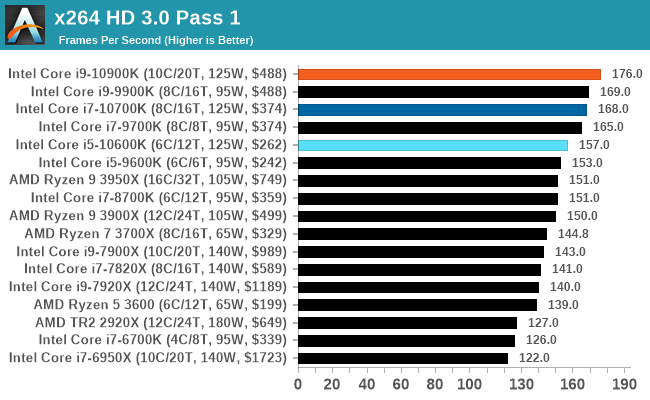
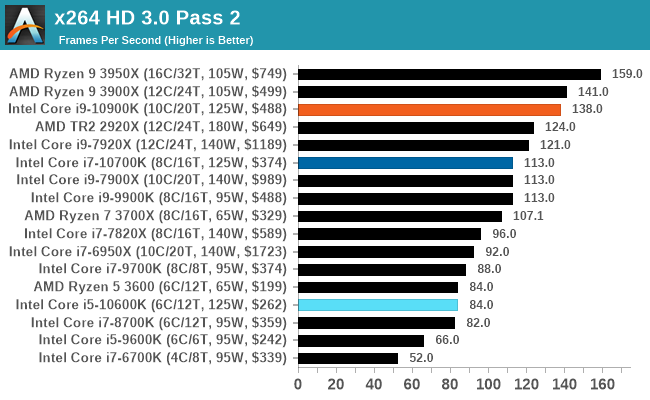
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.
CPU Performance: Synthetic Tests
As with most benchmark suites, there are tests that don’t necessarily fit into most categories because their role is just to find the peak throughput in very particular coding scenarios. For this we rely on some of the industry standard tests, like Geekbench and Cinebench.
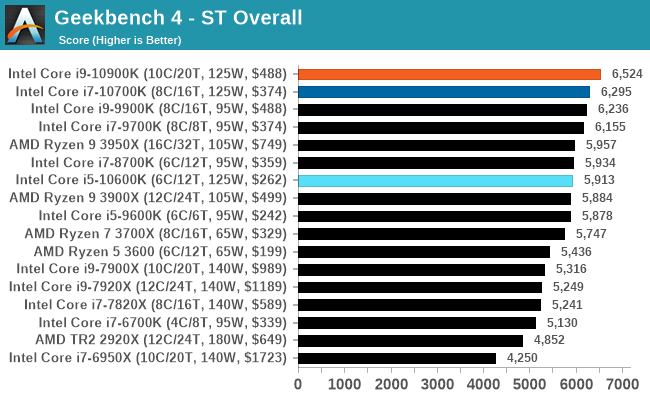
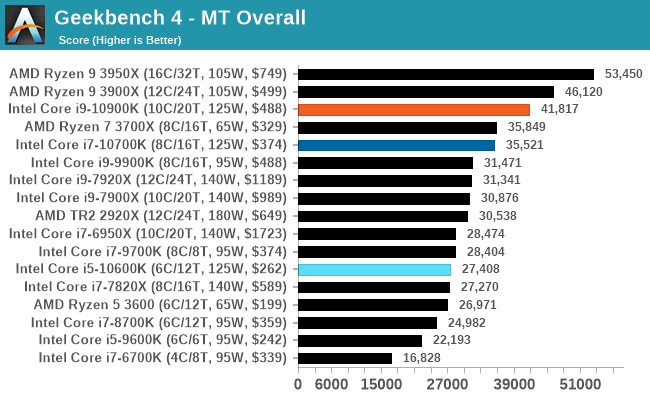
GeekBench4: Synthetics
A common tool for cross-platform testing between mobile, PC, and Mac, GeekBench 4 is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We record the main subtest scores (Crypto, Integer, Floating Point, Memory) in our benchmark database, but for the review we post the overall single and multi-threaded results.
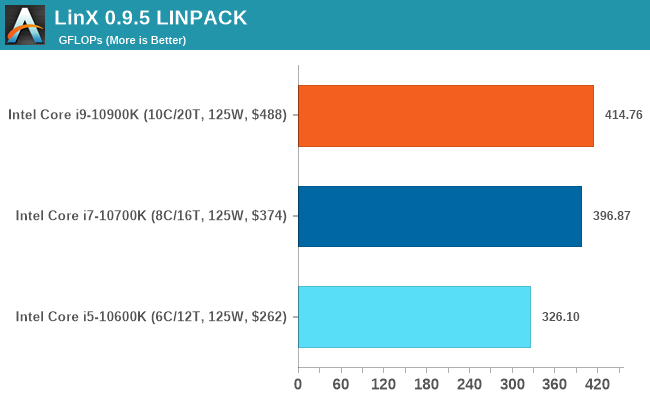
LinX: LINPACK
The main tool for ordering the TOP500 computer list involves running a variant of an accelerated matrix multiply algorithm typically found from the LINPACK suite. Here we use a tool called LinX to do the same thing on our CPUs. We scale our test based on the number of cores present in order to not run out of scaling but still keeping the test time consistent.
This is another of our new tests for 2020. Data will be added as we start regression testing older CPUs.
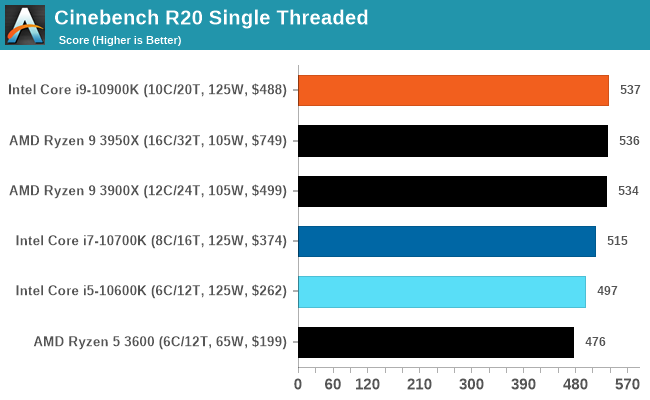
Cinebench R20
The Cinebench line of tests is very well known among technology enthusiasts, with the software implementing a variant of the popular Cinema4D engine to render through the CPU a complex scene. The latest version of Cinebench comes with a number of upgrades, including support for >64 threads, as well as offering a much longer test in order to stop the big server systems completing it in seconds. Not soon after R20 was launched, we ended up with 256 thread servers that completed the test in about two seconds. While we wait for the next version of Cinebench, we run the test on our systems in single thread and multithread modes, running for a minimum of 10 minutes each.

CPU Performance: SPEC 1T
A popular industry standard comparison tool between processors are the range of SPEC benchmarks. We use SPEC2006 and SPEC2017 in our major microarchitecture analysis pieces as a way to determine where certain processors might be bottlenecked given a particular microprocessor design decision. For the purposes of this review, we are looking at the aggregate results between some of the other processors we have tested, given that this benchmark has only recently rolled into our regular suite.
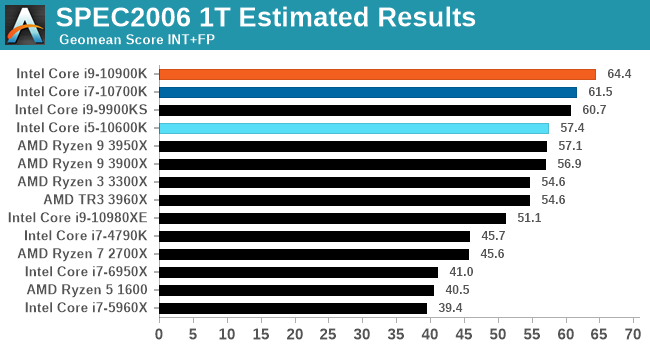
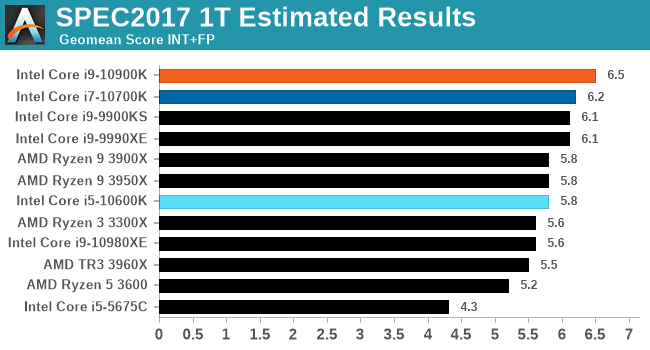
All the sub-tests for our SPEC runs are provided in our benchmark database, Bench.
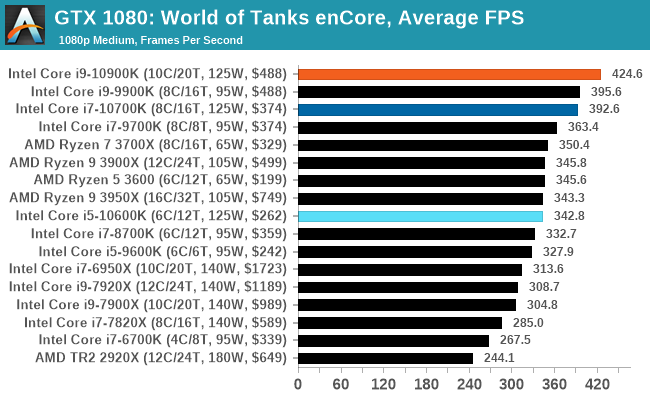
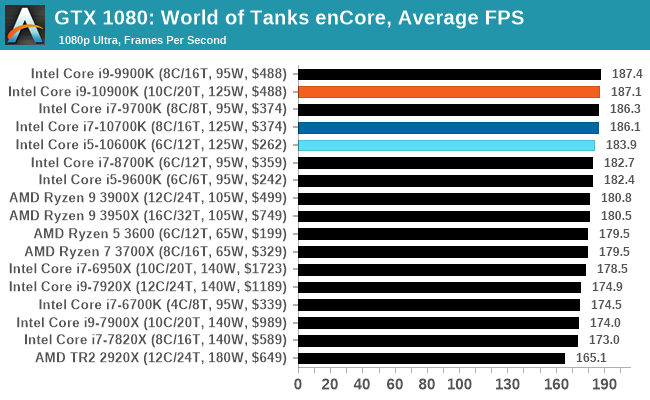
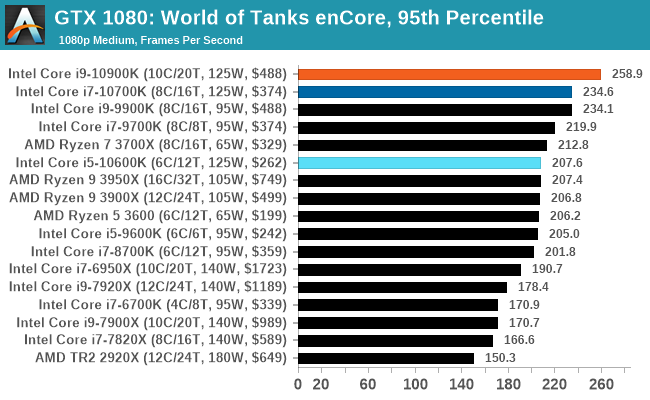
Gaming: World of Tanks enCore
Albeit different to most of the other commonly played MMO or massively multiplayer online games, World of Tanks is set in the mid-20th century and allows players to take control of a range of military based armored vehicles. World of Tanks (WoT) is developed and published by Wargaming who are based in Belarus, with the game’s soundtrack being primarily composed by Belarusian composer Sergey Khmelevsky. The game offers multiple entry points including a free-to-play element as well as allowing players to pay a fee to open up more features. One of the most interesting things about this tank based MMO is that it achieved eSports status when it debuted at the World Cyber Games back in 2012.

World of Tanks enCore is a demo application for a new and unreleased graphics engine penned by the Wargaming development team. Over time the new core engine will implemented into the full game upgrading the games visuals with key elements such as improved water, flora, shadows, lighting as well as other objects such as buildings. The World of Tanks enCore demo app not only offers up insight into the impending game engine changes, but allows users to check system performance to see if the new engine run optimally on their system.
All of our benchmark results can also be found in our benchmark engine, Bench.
| AnandTech | IGP | Low | Medium |
| Average FPS | 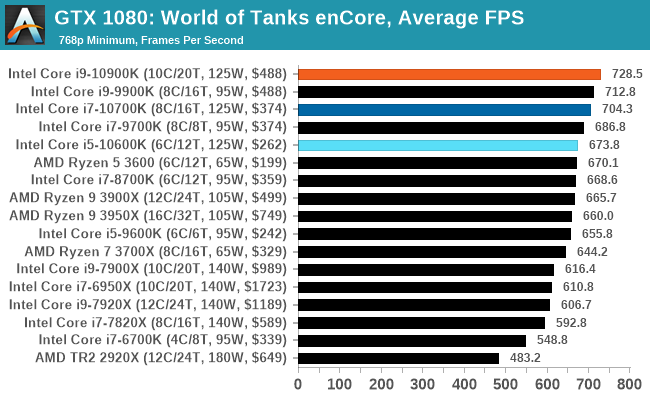 |
 |
 |
| 95th Percentile | 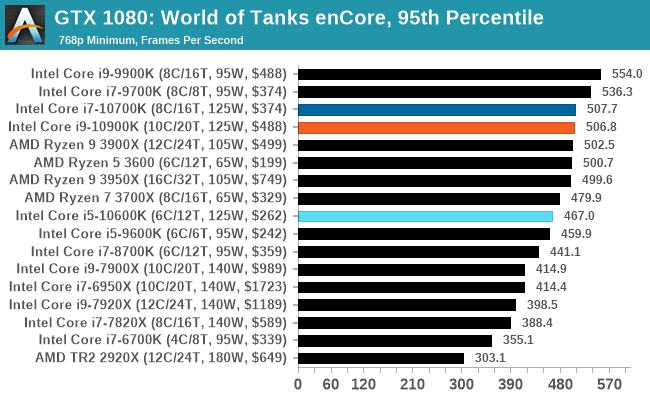 |
 |
 |
As we'll see through most of the gaming tests, Intel's CPUs usually sit at the top or near the top.
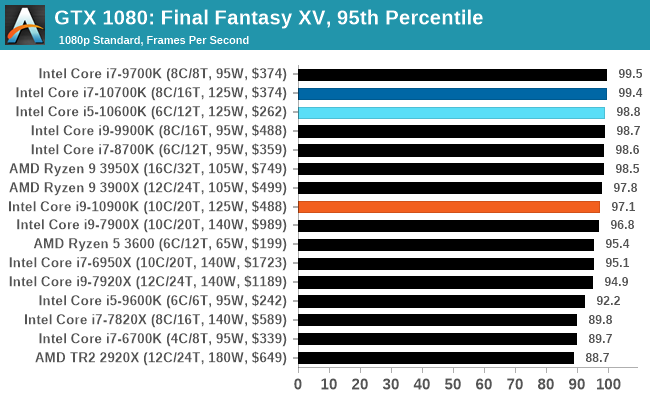
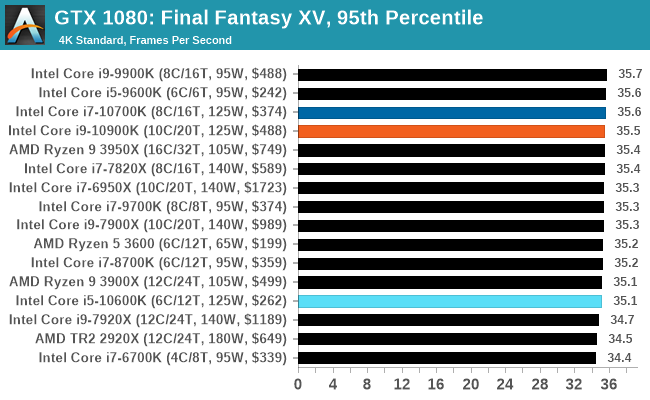
Gaming: Final Fantasy XV
Upon arriving to PC earlier this, Final Fantasy XV: Windows Edition was given a graphical overhaul as it was ported over from console, fruits of their successful partnership with NVIDIA, with hardly any hint of the troubles during Final Fantasy XV's original production and development.
In preparation for the launch, Square Enix opted to release a standalone benchmark that they have since updated. Using the Final Fantasy XV standalone benchmark gives us a lengthy standardized sequence to record, although it should be noted that its heavy use of NVIDIA technology means that the Maximum setting has problems - it renders items off screen. To get around this, we use the standard preset which does not have these issues.

Square Enix has patched the benchmark with custom graphics settings and bugfixes to be much more accurate in profiling in-game performance and graphical options. For our testing, we run the standard benchmark with a FRAPs overlay, taking a 6 minute recording of the test.
All of our benchmark results can also be found in our benchmark engine, Bench.

| AnandTech | IGP | Low | Medium | High |
| Average FPS |  |
 |
 |
 |
| 95th Percentile | 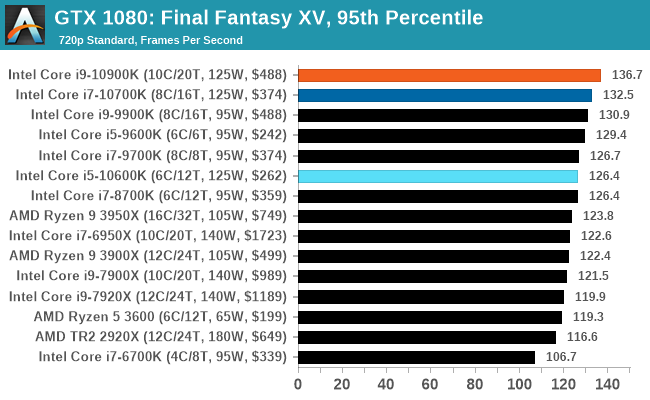 |
 |
 |
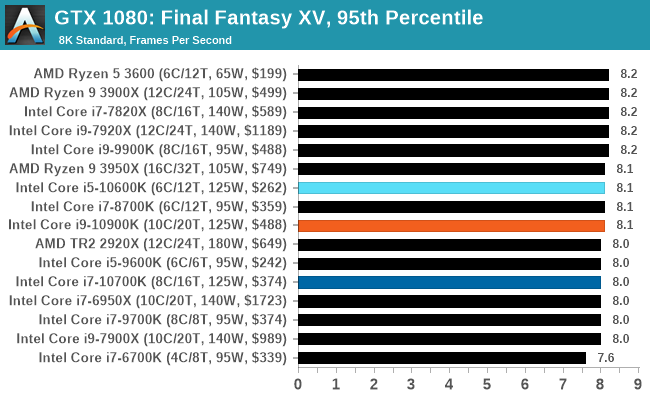 |
Even though our settings combinations end up being GPU limited very quickly, the Intel CPUs still appear near the top if not at the top.
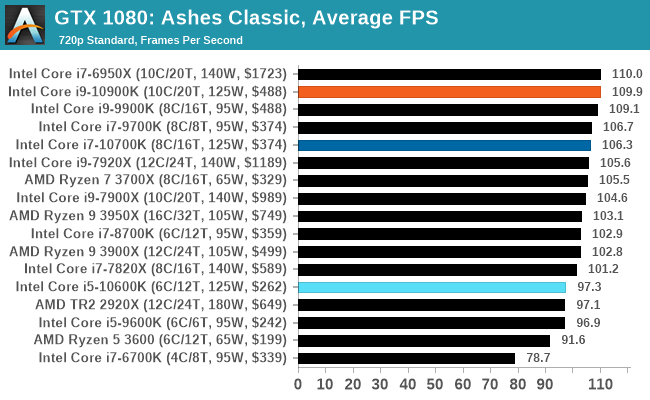
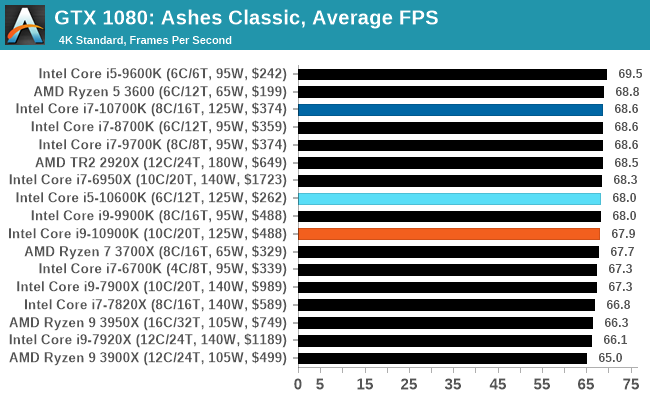
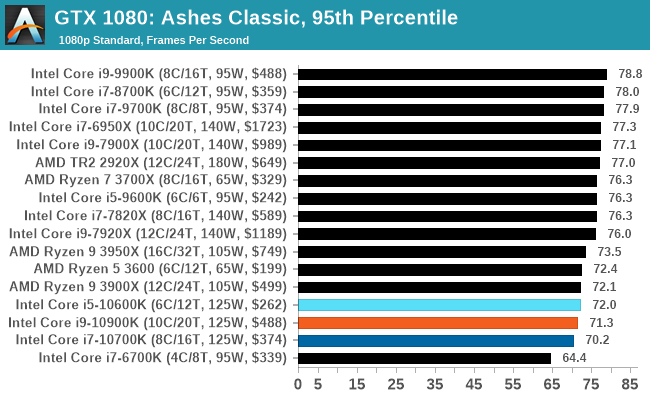
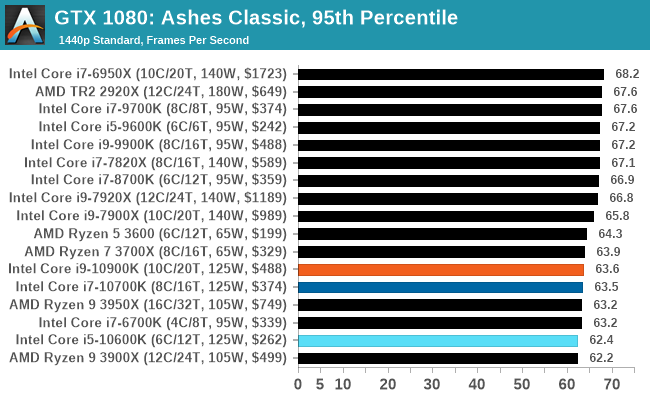
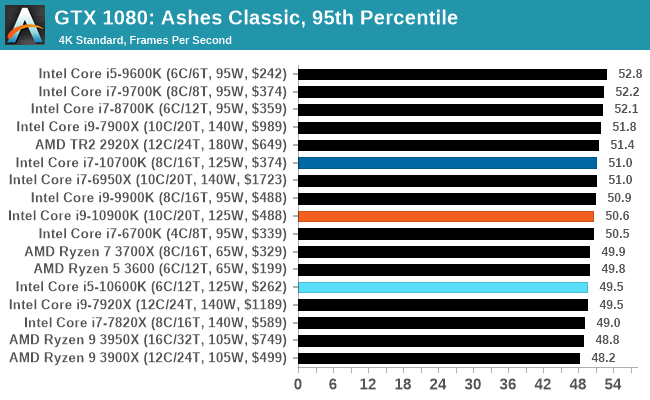
Gaming: Ashes Classic (DX12)
Seen as the holy child of DirectX12, Ashes of the Singularity (AoTS, or just Ashes) has been the first title to actively go explore as many of the DirectX12 features as it possibly can. Stardock, the developer behind the Nitrous engine which powers the game, has ensured that the real-time strategy title takes advantage of multiple cores and multiple graphics cards, in as many configurations as possible.

As a real-time strategy title, Ashes is all about responsiveness during both wide open shots but also concentrated battles. With DirectX12 at the helm, the ability to implement more draw calls per second allows the engine to work with substantial unit depth and effects that other RTS titles had to rely on combined draw calls to achieve, making some combined unit structures ultimately very rigid.
Stardock clearly understand the importance of an in-game benchmark, ensuring that such a tool was available and capable from day one, especially with all the additional DX12 features used and being able to characterize how they affected the title for the developer was important. The in-game benchmark performs a four minute fixed seed battle environment with a variety of shots, and outputs a vast amount of data to analyze.
For our benchmark, we run Ashes Classic: an older version of the game before the Escalation update. The reason for this is that this is easier to automate, without a splash screen, but still has a strong visual fidelity to test.
Ashes has dropdown options for MSAA, Light Quality, Object Quality, Shading Samples, Shadow Quality, Textures, and separate options for the terrain. There are several presents, from Very Low to Extreme: we run our benchmarks at the above settings, and take the frame-time output for our average and percentile numbers.
All of our benchmark results can also be found in our benchmark engine, Bench.
| AnandTech | IGP | Low | Medium | High |
| Average FPS |  |
 |
 |
 |
| 95th Percentile | 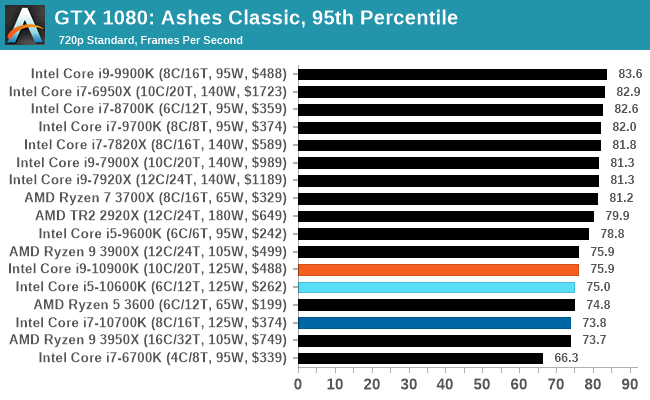 |
 |
 |
 |
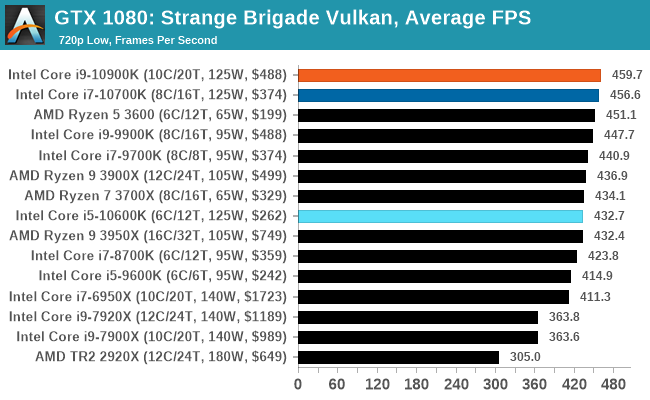
Gaming: Strange Brigade (DX12, Vulkan)
Strange Brigade is based in 1903’s Egypt and follows a story which is very similar to that of the Mummy film franchise. This particular third-person shooter is developed by Rebellion Developments which is more widely known for games such as the Sniper Elite and Alien vs Predator series. The game follows the hunt for Seteki the Witch Queen who has arose once again and the only ‘troop’ who can ultimately stop her. Gameplay is cooperative centric with a wide variety of different levels and many puzzles which need solving by the British colonial Secret Service agents sent to put an end to her reign of barbaric and brutality.

The game supports both the DirectX 12 and Vulkan APIs and houses its own built-in benchmark which offers various options up for customization including textures, anti-aliasing, reflections, draw distance and even allows users to enable or disable motion blur, ambient occlusion and tessellation among others. AMD has boasted previously that Strange Brigade is part of its Vulkan API implementation offering scalability for AMD multi-graphics card configurations.
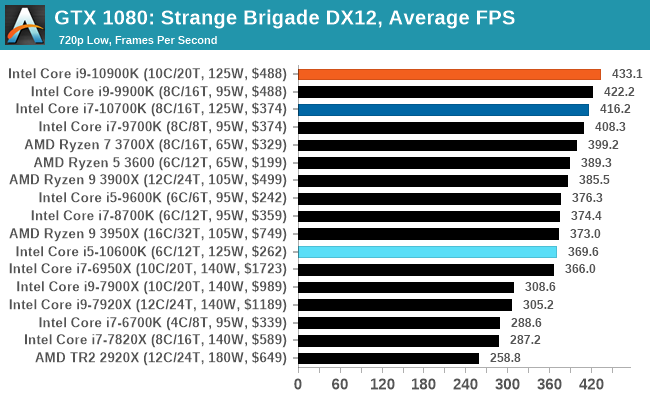
| AnandTech | IGP | Low |
| Average FPS |  |
 |
| 95th Percentile | 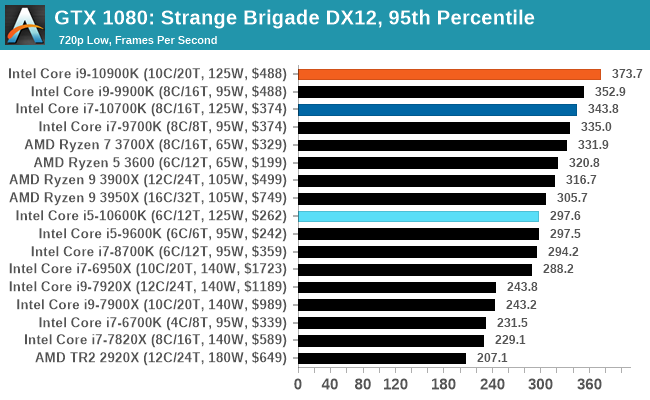 |
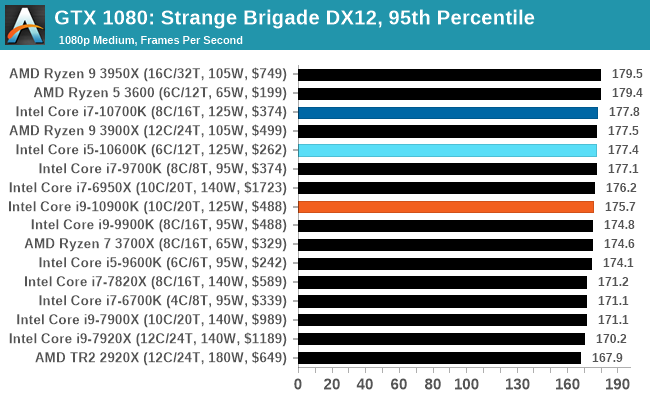 |
All of our benchmark results can also be found in our benchmark engine, Bench.
| AnandTech | IGP | Low |
| Average FPS |  |
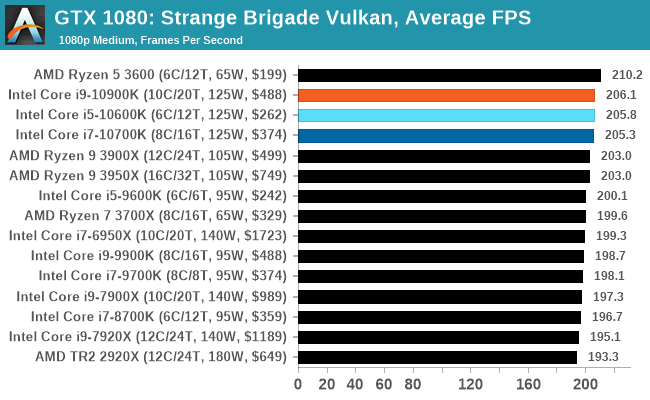 |
| 95th Percentile | 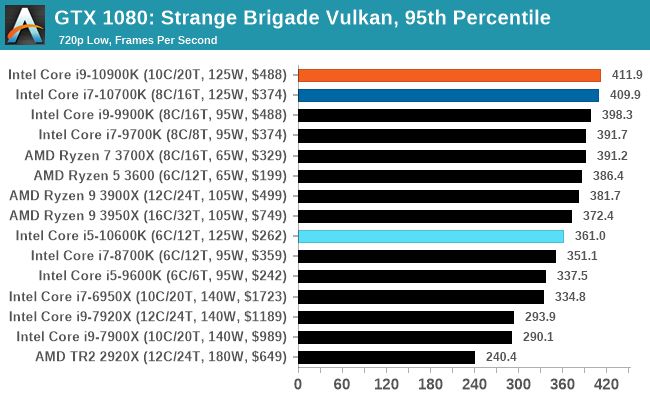 |
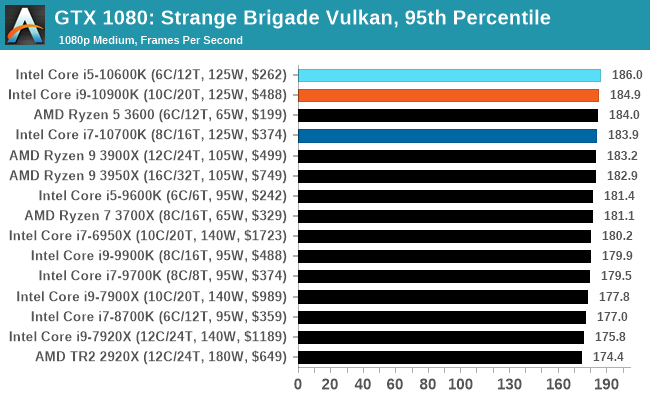 |
Gaming: Grand Theft Auto V
The highly anticipated iteration of the Grand Theft Auto franchise hit the shelves on April 14th 2015, with both AMD and NVIDIA in tow to help optimize the title. GTA doesn’t provide graphical presets, but opens up the options to users and extends the boundaries by pushing even the hardest systems to the limit using Rockstar’s Advanced Game Engine under DirectX 11. Whether the user is flying high in the mountains with long draw distances or dealing with assorted trash in the city, when cranked up to maximum it creates stunning visuals but hard work for both the CPU and the GPU.

For our test we have scripted a version of the in-game benchmark. The in-game benchmark consists of five scenarios: four short panning shots with varying lighting and weather effects, and a fifth action sequence that lasts around 90 seconds. We use only the final part of the benchmark, which combines a flight scene in a jet followed by an inner city drive-by through several intersections followed by ramming a tanker that explodes, causing other cars to explode as well. This is a mix of distance rendering followed by a detailed near-rendering action sequence, and the title thankfully spits out frame time data.
There are no presets for the graphics options on GTA, allowing the user to adjust options such as population density and distance scaling on sliders, but others such as texture/shadow/shader/water quality from Low to Very High. Other options include MSAA, soft shadows, post effects, shadow resolution and extended draw distance options. There is a handy option at the top which shows how much video memory the options are expected to consume, with obvious repercussions if a user requests more video memory than is present on the card (although there’s no obvious indication if you have a low end GPU with lots of GPU memory, like an R7 240 4GB).
All of our benchmark results can also be found in our benchmark engine, Bench.
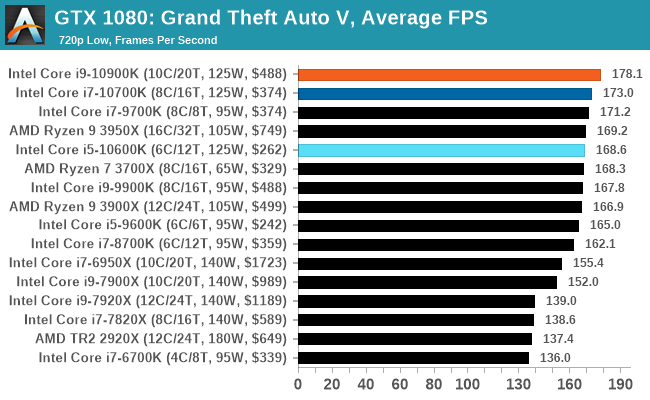
| AnandTech | IGP | Low |
| Average FPS |  |
 |
| 95th Percentile | 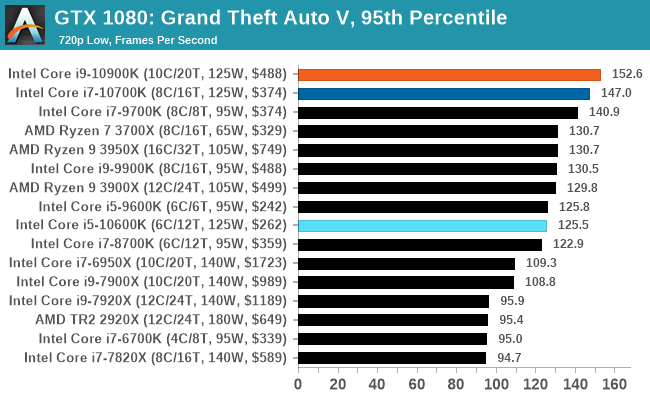 |
 |
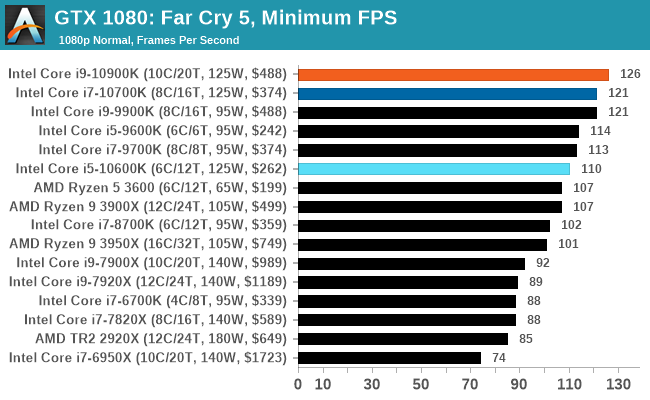
Gaming: Far Cry 5
The latest title in Ubisoft's Far Cry series lands us right into the unwelcoming arms of an armed militant cult in Montana, one of the many middles-of-nowhere in the United States. With a charismatic and enigmatic adversary, gorgeous landscapes of the northwestern American flavor, and lots of violence, it is classic Far Cry fare. Graphically intensive in an open-world environment, the game mixes in action and exploration.

Far Cry 5 does support Vega-centric features with Rapid Packed Math and Shader Intrinsics. Far Cry 5 also supports HDR (HDR10, scRGB, and FreeSync 2). We use the in-game benchmark for our data, and report the average/minimum frame rates.
All of our benchmark results can also be found in our benchmark engine, Bench.
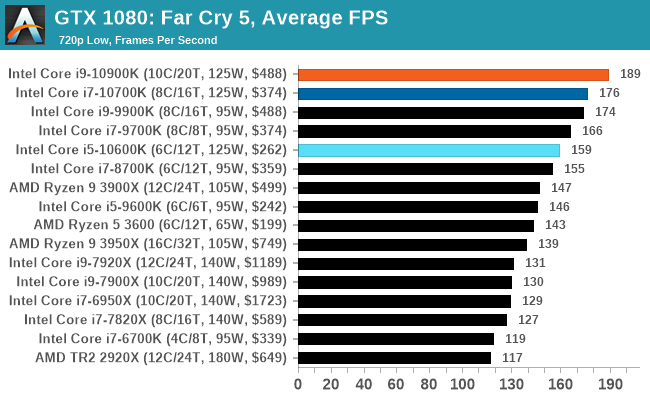
| AnandTech | IGP | Low | High |
| Average FPS |  |
 |
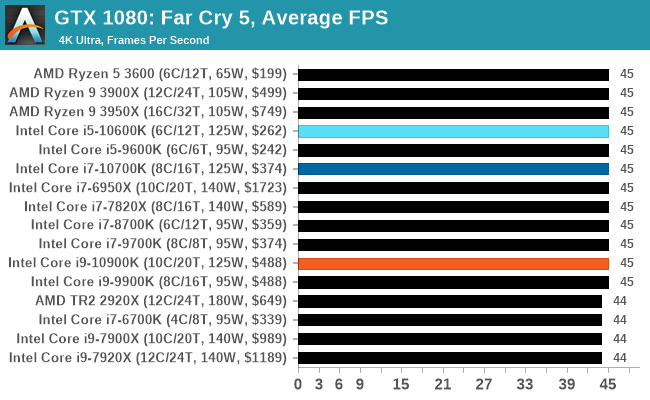 |
| 95th Percentile | 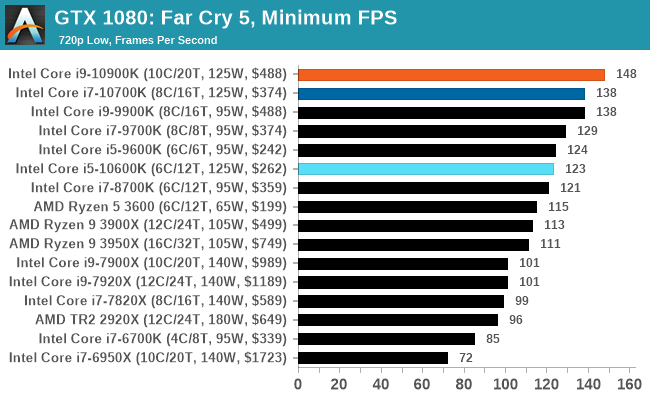 |
 |
 |
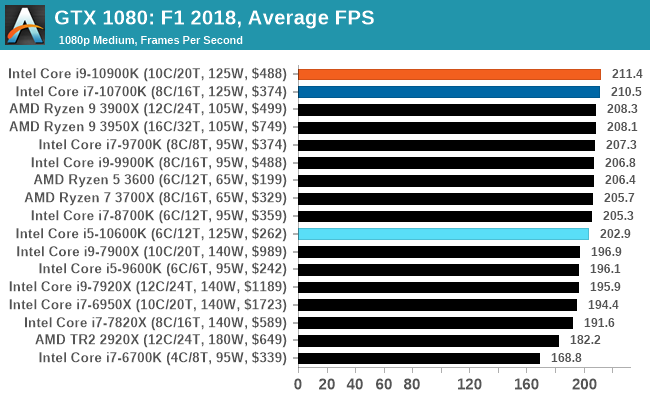
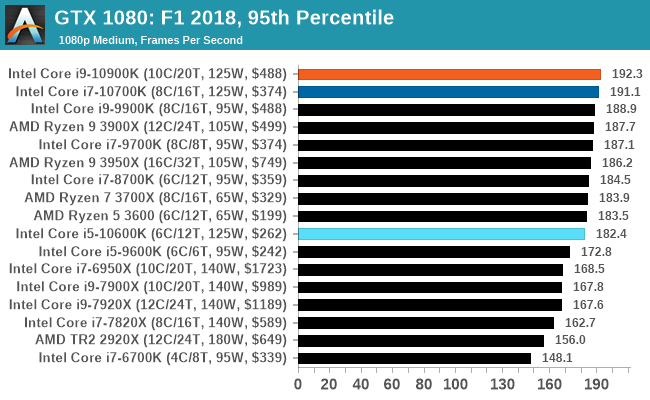
Gaming: F1 2018
Aside from keeping up-to-date on the Formula One world, F1 2017 added HDR support, which F1 2018 has maintained; otherwise, we should see any newer versions of Codemasters' EGO engine find its way into F1. Graphically demanding in its own right, F1 2018 keeps a useful racing-type graphics workload in our benchmarks.
We use the in-game benchmark, set to run on the Montreal track in the wet, driving as Lewis Hamilton from last place on the grid. Data is taken over a one-lap race.
All of our benchmark results can also be found in our benchmark engine, Bench.
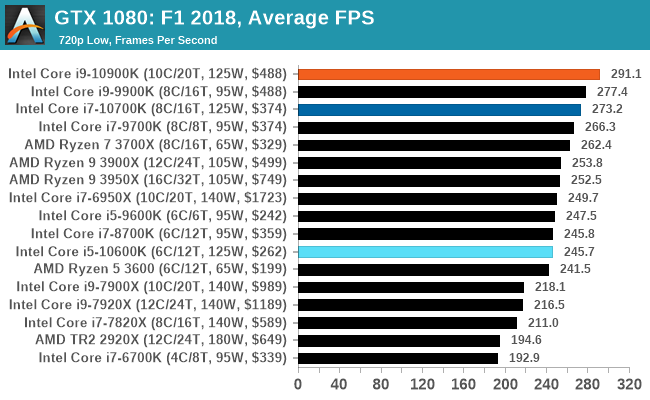
| AnandTech | IGP | Low |
| Average FPS |  |
 |
| 95th Percentile | 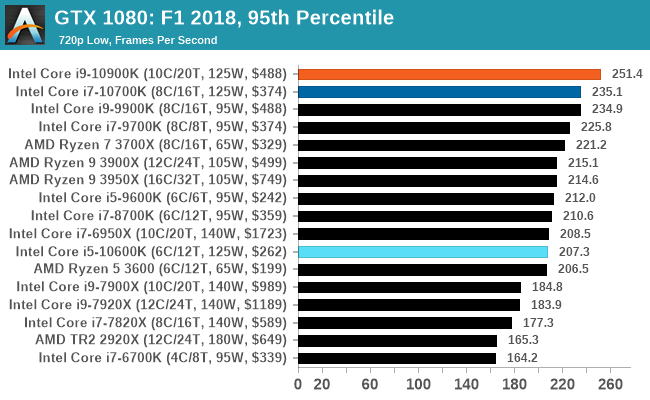 |
 |
Conclusion: Less Lakes, More Coves Please
One thing that Intel has learned through the successive years of the reiterating the Skylake microarchitecture on the same process but with more cores has been optimization – the ability to squeeze as many drops out of a given manufacturing node and architecture as is physically possible, and still come out with a high-performing product when the main competitor is offering similar performance at a much lower power.
Intel has pushed Comet Lake and its 14nm process to new heights, and in many cases, achieving top results in a lot of our benchmarks, at the expense of power. There’s something to be said for having the best gaming CPU on the market, something which Intel seems to have readily achieved here when considering gaming in isolation, though now Intel has to deal with the messaging around the power consumption, similar how AMD had to do in the Vishera days.
One of the common phrases that companies in this position like to use is that ‘when people use a system, they don’t care about how much power it’s using at any specific given time’. It’s the same argument borne out of ‘some people will pay for the best, regardless of price or power consumption’. Both of these arguments are ones that we’ve taken onboard over the years, and sometimes we agree with them – if all you want is the best, then yes these other metrics do not matter.

In this review we tested the Core i9-10900K with ten cores, the Core i7-10700K with eight cores, and the Core i5-10600K with six cores. On the face of it, the Core i9-10900K with its ability to boost all ten cores to 4.9 GHz sustained (in the right motherboard) as well as offering 5.3 GHz turbo will be a welcome recommendation to some users. It offers some of the best frame rates in our more CPU-limited gaming tests, and it competes at a similar price against an AMD processor that offers two more cores at a lower frequency. This is really going to be a case of ‘how many things do you do at once’ type of recommendation, with the caveat of power.
The ability of Intel to pull 254 W on a regular 10 core retail processor is impressive. After we take out the system agent and DRAM, this is around 20 W per core. With its core designs, Intel has often quoted its goal to scale these Core designs from fractions of a Watt to dozens of Watts. The only downside now of championing something in the 250 W range is going to be that there are competitive offerings that do 24, 32, and 64 cores in this power range. Sure, those processors are more expensive, but they do a lot more work, especially for large multi-core scenarios.
If we remember back to AMD’s Vishera days, the company launched a product with eight cores, 5.0 GHz, with a 220 W TDP. At peak power consumption, the AMD FX-9590 was nearer 270 W, and while AMD offered caveats listed above (‘people don’t’ really care about the power of the system while in use’) Intel chastised the processor for being super power hungry and not high performance enough to be competitive. Fast forward to 2020, we have the reverse situation, where Intel is pumping out the high power processor, but this time, there’s a lot of performance.
The one issue that Intel won’t escape from is that all this extra power requires extra money to be put into cooling the chip. While the Core i9 processor is around the same price as the Ryzen 9 3900X, the AMD processor comes with a 125 W cooler which will do the job – Intel customers will have to go forth and source expensive cooling in order to keep this cool. Speaking with a colleague, he had issues cooling his 10900K test chip with a Corsair H115i, indicating that users should look to spending $150+ on a cooling setup. That’s going to be a critical balancing element here when it comes to recommendations.
For recommendations, Intel’s Core i9 is currently performing the best in a lot of tests, and that’s hard to ignore. But will the end-user want that extra percent of performance, for the sake of spending more on cooling and more in power? Even in the $500 CPU market, that’s a hard one to ask. Then add in the fact that the Core i9 doesn’t have PCIe 4.0 support, we get to a situation that it’s the best offering if you want Intel, and you want the best processor, but AMD has almost the same ST performance, better MT performance in a lot of cases, and a much better power efficiency and future PCIe support – it comes across as the better package overall.
Throughout this piece I’ve mainly focused on the Core i9, with it being the flagship part. The Core i7 and the Core i5 are also in our benchmark results, and their results are a little mixed.
The Core i5 doesn’t actually draw too much power, but it doesn’t handle the high performance aspect in multi-threaded scenarios. At $262 it comes in at more expensive than the Ryzen 5 3600 which is $200, and the trade-off here is the Ryzen’s better IPC against the Core i5’s frequency. Most of the time the Core i5-10600K wins, as it should do given that it costs an extra $60, but again doesn’t have the PCIe 4.0 support that the AMD chip offers. When it comes to building that $1500 PC, this will be an interesting trade-off to consider.
For the Core i7-10700K, at 8C/16T, we really have a repeat of the Core i9-9900K from the previous generation. It offers a similar sort of performance and power, except with Turbo Boost Max 3.0 giving it a bit more frequency. There’s also the price – at $374 it is certainly a lot more attractive than it was at $488. Anand once said that there are no bad products, only bad prices, and a $114 price drop on the 8c overclocked part is highly welcome. At $374 it fits between the Ryzen 9 3900X ($432) and the Ryzen 7 3800X ($340), so we’re still going to see some tradeoffs against the Ryzen 7 in performance vs power vs cost.
Final Thoughts
Overall, I think the market is getting a little bit of fatigue from continuous recycling of the Skylake microarchitecture on the desktop. The upside is that a lot of programs are optimized for it, and Intel has optimized the process and the platform so much that we’re getting a lot higher frequencies out of it, at the expense of power. Intel is still missing key elements in its desktop portfolio, such as PCIe 4.0 and DDR4-3200, as well as anything resembling a decent integrated graphics processor, but ultimately one could argue that the product team are at the whims of the manufacturing arm, and 10nm isn’t ready yet for the desktop prime time.
When 10nm will be ready for the desktop we don’t know - Intel is set to showcase 10nm Ice Lake for servers at Hot Chips in August, as well as 10nm Tiger Lake for notebooks. If we’re stuck on 14nm on the desktop for another generation, then we really need a new microarchitecture that scales as well. Intel might be digging itself a hole, optimizing Skylake so much, especially if it can’t at least match what might be coming next – assuming it even has enough space on the manufacturing line to build it. Please Intel, bring a Cove our way soon.
For the meantime, we get a power hungry Comet Lake, but at least the best chip in the stack performs well enough to top a lot of our charts for the price point.
These processors should be available from today. As far as we understand, the overclockable parts will be coming to market first, with the rest coming to shelves depending on region and Intel's manufacturing plans.






