Original Link: https://www.anandtech.com/show/16680/tiger-lake-h-performance-review
Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
Last week Intel launched their Tiger Lake-H family of laptop processors. Aimed at the larger 14-inch and above laptops, this processor family is Intel’s newest offering for the high-performance laptop market, stepping in above Intel’s mobility-focused U and Y series of chips. Based on the same Tiger Lake architecture that we first became familiar with last year, Tiger Lake-H is bigger and better (at least where the CPU is concerned), offering up to 8 CPU cores and other benefits like additional PCIe lanes. Overall, Intel’s H-series chips have long served as the performance backbone of their laptop efforts, and with Tiger Lake-H they are looking to continue that tradition.
While last week was Tiger Lake-H’s official launch, as has become increasingly common for laptop launches, the embargoes for the launch information and for hardware reviews have landed on separate dates. So, while we were able to take about the platform last week, it’s only today that we’re able to share with you our data on TGL-H – and our evaluation on whether it lives up to Intel’s claims as well as how it stacks up to the competition.

Like Intel’s other laptop chips, Tiger Lake-H has multiple facets, with the company needing to balance CPU performance, GPU performance, and power consumption, all while ensuring it’s suitable to manufacture on Intel’s revised 10nm “SuperFin” process. Balancing all of these elements is a challenge in and of itself, never mind the fact that arch-rival AMD is looking to compete with their own Zen 3 architecture-based Ryzen 5000 Mobile (Cezanne) APUs.
| Intel Tiger Lake-H Consumer | ||||||||||
| AnandTech | Cores Threads |
35W Base |
45W Base |
65W Base |
2C Turbo |
4C Turbo |
nT Turbo |
L3 Cache |
Xe GPU |
Xe MHz |
| i9-11980HK | 8C/16T | - | 2.6 | 3.3 | 5.0* | 4.9 | 4.5 | 24 MB | 32 | 1450 |
| i9-11900H | 8C/16T | 2.1 | 2.5 | - | 4.9* | 4.8 | 4.4 | 24 MB | 32 | 1450 |
| i7-11800H | 8C/16T | 1.9 | 2.3 | - | 4.6 | 4.5 | 4.2 | 24 MB | 32 | 1450 |
| i5-11400H | 6C/12T | 2.2 | 2.7 | - | 4.5 | 4.3 | 4.1 | 12 MB | 16 | 1450 |
| i5-11260H | 6C/12T | 2.1 | 2.6 | - | 4.4 | 4.2 | 4.0 | 12 MB | 16 | 1400 |
| *Turbo Boost Max 3.0 | ||||||||||
Intel’s Reference Design Laptop: Core i9-11980HK Inside
For our Tiger Lake-H performance review, Intel has once again sent over one of their reference design laptops. As with the Tiger Lake-U launch last year, these reference design laptops are not retail laptops in and of themselves, but more of an advanced engineering sample designed to demonstrate the performance of the underlying hardware. In this specific case, the BIOS identifies that the laptop was assembled by MSI.

Wanting to put their best foot forward in terms of laptop performance, Intel’s TGL-H reference design laptop is, as you’d imagine, a rather high-end system. The 16-inch laptop is based around Intel’s best TGL-H part, the Core i9-11980HK, which offers 8 Willow Cove architecture CPU cores with SMT, for a total of 16 threads. This processor can turbo as high as 5.0GHz on its favored cores, a bit behind Intel’s previous-generation Comet Lake-H CPUs, but keeping clockspeeds close while making up the difference on IPC.
Unfortunately, their desire to put their best foot forward means that Intel has configured the CPU in this system to run at 65W, rather than the more typical 45W TDP of most high-end laptops. 65W is a valid mode for this chip, so strictly speaking Intel isn’t juicing the chip, but the bulk of the Tiger Lake-H lineup is intended to run at a more lap-friendly 45W. This gives the Intel system an innate advantage in terms of performance, since it has more TDP headroom to play with.
| Intel Reference Design: Tiger Lake-H | |
| CPU | Intel Core i9-11980HK 8 Cores, 16 Threads 2600 MHz Base (45W) 3300 MHz Base (65W) 5000 MHz Turbo 2C 4500 MHz Turbo nT |
| GPU | Integrated: Xe-LP Graphics 32 Execution Units, up to 1450 MHz Discrete: NVIDIA GeForce RTX 3060 Laptop 30 SMs, up to 1703MHz |
| DRAM | 32 GB DDR4-3200 CL22 |
| Storage | 2x OEM Phison E16 512GB SSD (NVMe PCIe 4.0 x4) |
| Display | 16-inch 2560x1600 |
| IO | 2x USB-C 2x USB-A |
| Wi-Fi | Intel AX210 Wi-Fi 6E + BT5.2 Adapter |
| Power Mode | 65 W (Mostly tested at 45W) |
Meanwhile the focus on CPU performance with TGL-H does come at a cost to integrated GPU performance. TGL-H parts include Intel’s Xe-LP GPU, but with only 32 EUs instead of the 96 found on high-end Tiger Lake-U systems. With TGL-H, Intel is expecting these systems to be bundled with discrete GPUs, so they don’t dedicate nearly as much die space to an integrated GPU that may not get used much anyhow. To that end, the reference system comes with an NVIDIA GeForce RTX 3060 Laptop graphics adapter as well, which is paired with its own 6GB of GDDR6.

Rounding out the package, the system comes with 32GB of DDR4-3200 installed. Storage is provided by a pair of Phison E16-based OEM drives, allowing Intel to show off the benefits of PCIe 4.0 connectivity for SSDs. Finally, Wi-Fi connectivity is also Intel-powered, using the company’s new AX210 adapter, which offers Wi-Fi 6E + BT5.2 on a single M.2 adapter. It’s worth noting that the AX210 is a fully discrete adapter, so it doesn’t leverage TGL-H’s integrated (CNVi) MAC, as that doesn’t support Wi-Fi 6E.
And, in keeping with making this reference system look as close to a retail design as reasonably possible, Intel even put the usual Intel Core and NVIDIA GeForce stickers on the laptop.

Unfortunately, we’ve had relatively little time with the system ahead of today’s embargo. The embargo on performance figures was originally scheduled for last Thursday (May 13th). However due to delays in shipping these laptops to reviewers, we didn’t receive the system until the end of last week, and Intel bumped back the embargo accordingly. So with just over two days to look over the system, we’ve really only had a chance to take a look at the most critical aspects of the system when it comes to performance.
Power Consumption - Up to 65W or not?
TDPs and power consumption has been a topic we’ve been revisiting on an (unfortunately) regular basis on almost every product launch. Over the last few generations of product launches in particular, we’ve been attempting to explain the current industry situation in more depth in order to demystify marketed power and thermal envelope figures versus what you can actually expect to encounter in the real products.
Given our limited time in writing up this Tiger Lake-H system, I’ll refer back to our more extensive articles, in particular the in-depth explanation of TDPs and Intel’s new generation product behaviour in our review of the Tiger Lake reference platform last September:
Alongside that piece, we also want to point out more extensive historical talks about TDPs, Turbo and power consumption:
- Why Intel Processors Draw More Power Than Expected: TDP and Turbo Explained
- Talking TDP, Turbo and Overclocking: An Interview with Intel Fellow Guy Therien
- Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
- AMD Ryzen 9 5980HS Cezanne Review: Ryzen 5000 Mobile Tested
In the context of today’s Tiger Lake-H reference laptop and system, the one thing we must preface the rest of the review is the power settings the laptop came in and the resulting behaviour and thermal characteristics of the Core i9-11980HK SKU we’ll be reviewing today.
Intel’s reference laptop, out of the box as delivered to us by Intel seemingly was set up with no PL1 limit, or at least what we suspect is the maximum cTDP limit of 65W of the i9-11980HK. Generally speaking, this is no surprise as TGL-H is targeting the high-power desktop replacement laptop market which tends to come with capable and extensive thermal dissipation designs.
At first, we started running our tests on the platform in this default reference setting, representing what we had hoped being the best-case scenario for the chip and platform, until we discovered some concerning thermal behaviour when under full load:
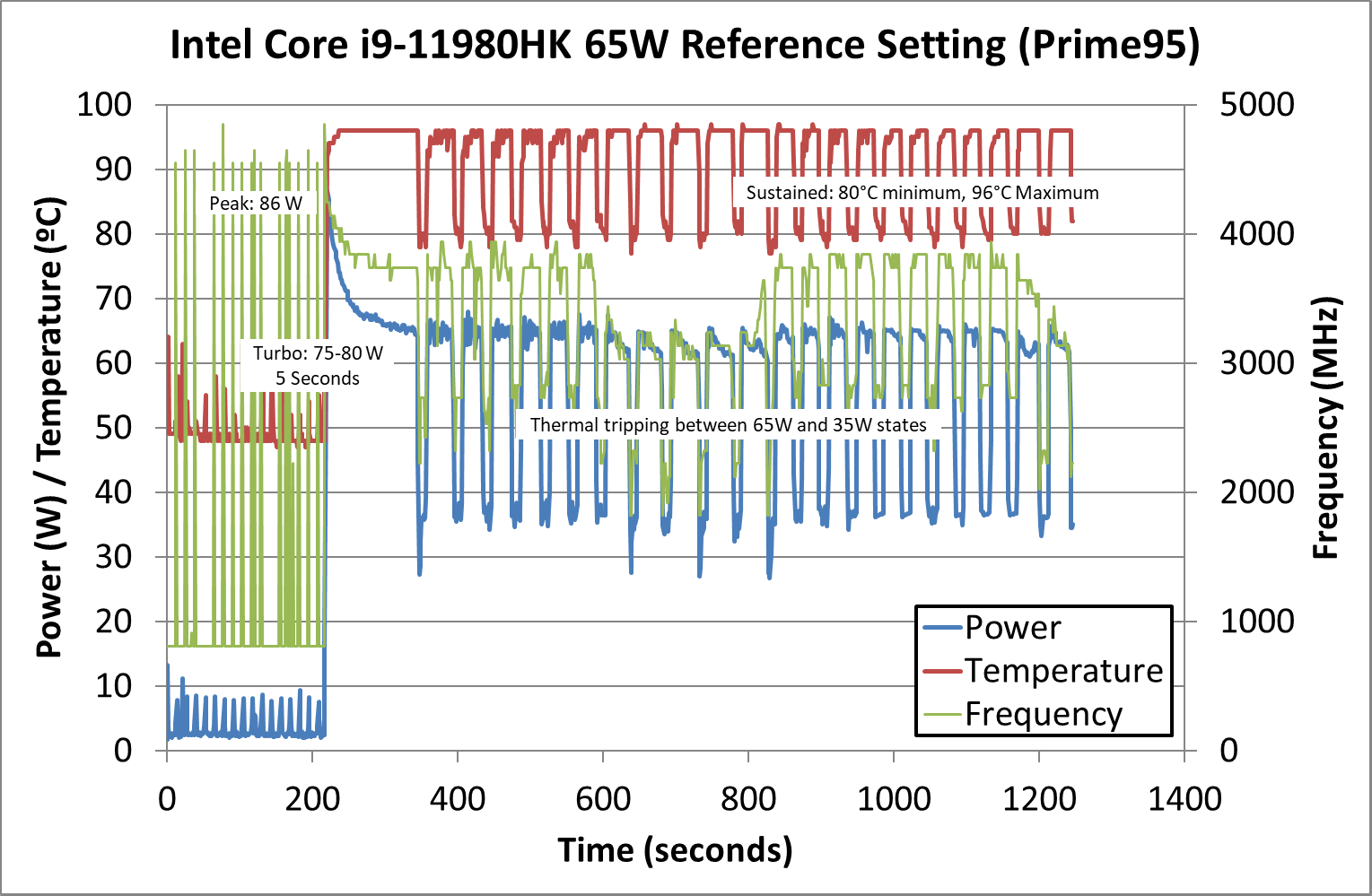
Under a Prime95 load in a more prolonged test period of 10+ minutes, when tracking package power consumption as well as CPU temperatures and frequencies, we’re seeing that the TGL-H reference laptop is having great troubles at sustaining this default 65W TDP mode.
During the initial idle period we see the CPU has low power consumption in the 2.2W range with some workload noise in the mix, boosting the CPU frequencies up to 4.9GHz.
The initial load ramp results in peak power consumption of up to 86W, but this is a very transient measurement as power quickly throttles down to 70W and below within seconds. In our readouts it seems that Tau (PL2 turbo period) seems to be set at 5 seconds for this machine.
The worrying behaviour starts happening after around 2 minutes of load: we indeed see the CPU package generally trying to limit itself to around 65W, however it’s not a constant steady state, with very obvious large fluctuations between 65W and 35W.
Looking at the temperature, we’re seeing maximum load figures in excess of 95°C, with some 96°C peaks in our coarse sampled data. What seems to be happening here is that the CPU is thermal tripping between the 65W and 35W states, unable to sustain the 65W state for any amount of prolonged time.
We’ve confirmed that this throttling and power and frequency fluctuations happen on several workloads, and the only conclusion we can come to is that the reference system simply doesn’t have an adequate enough thermal dissipation solution to effectively enable the 65W cTDP mode of the CPU.
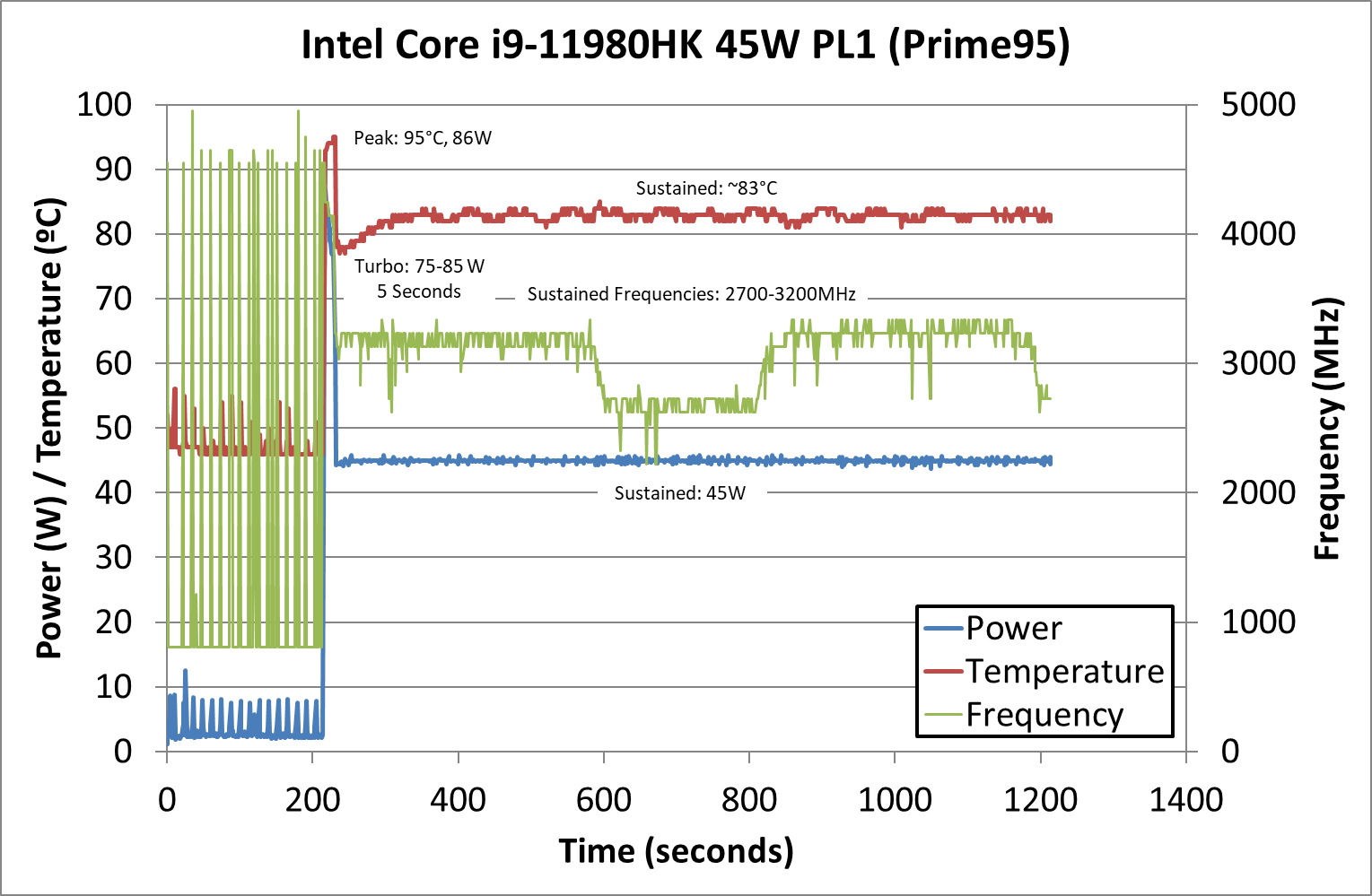
While the reference laptop had a bare-bones BIOS, fortunately enough we were able to rely on XTU to change the system’s PL1 settings, and we chose to re-test at 45W given that this is the i9-11980HK’s supposed default TDP setting.
Under this simple change, the thermal, power and frequency response of the system appears to be much more reasonable. We’re still seeing peak power consumption figures of 75-86W which should correspond to the PL2 figures of the chip, but again that’s only for short workloads which fit into the 5 second Tau/Turbo period.
For the remainder of the next 15 minutes, the machine was able to sustain a steady state CPU temperature of around 83°C, and power consumption capped at 45W. Frequencies ended up around 3200MHz all-core for most of the test but had a prolonged 2700MHz period a few minutes in. The 11980HK has an advertised base frequency of 2600MHz, so that seems to be in line with Intel’s specifications.
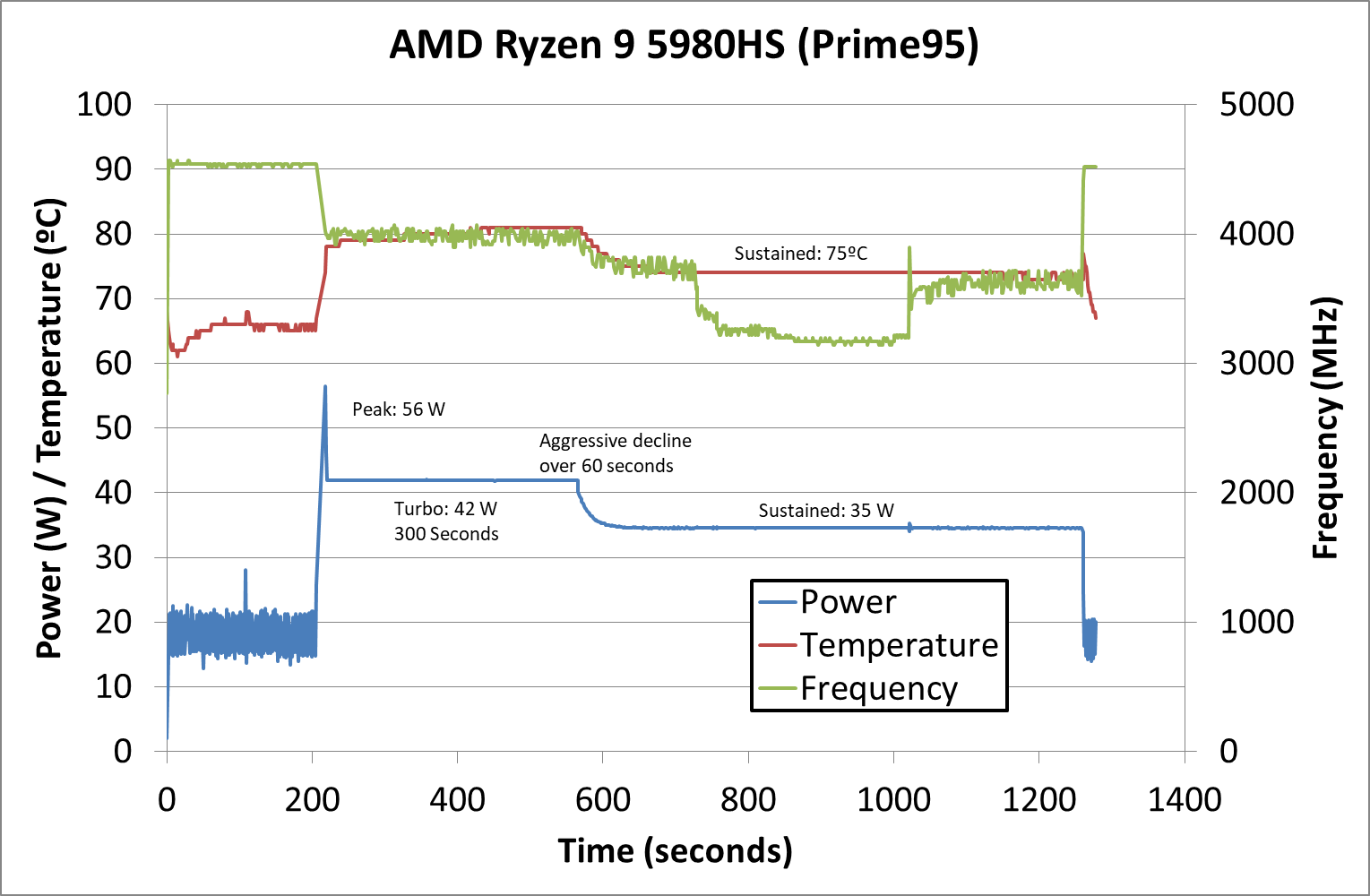
Unfortunately, we don’t have Intel’s previous generation H-Series processors in house for a direct generational comparison, but the next best thing is the 11980HK’s nearest competitor, AMD’s Ryzen 9 5980HS. This latter chip comes with a 35W TDP which is 10W lower than the new TGL-H SKU we have in house right now, and we see an obvious difference between the chip’s long-term thermals and power, ending up at different levels after some while.
The Ryzen 9 has a prolonged 300s semi-turbo state where it sustains 42W power until thermal saturation of the laptop. During this period, with similar power consumption to the 11980HK and also quite similar thermal results of around 80-83°C, both platforms seem to be quite similar – except for the fact that AMD Zen3 cores able to operate at all-core boost frequencies of around 4GHz, while the Willow Cove cores of the TGL-H system operate at around 3200MHz and below. This is an important metric to note as we dive deeper in other results of our test suite.
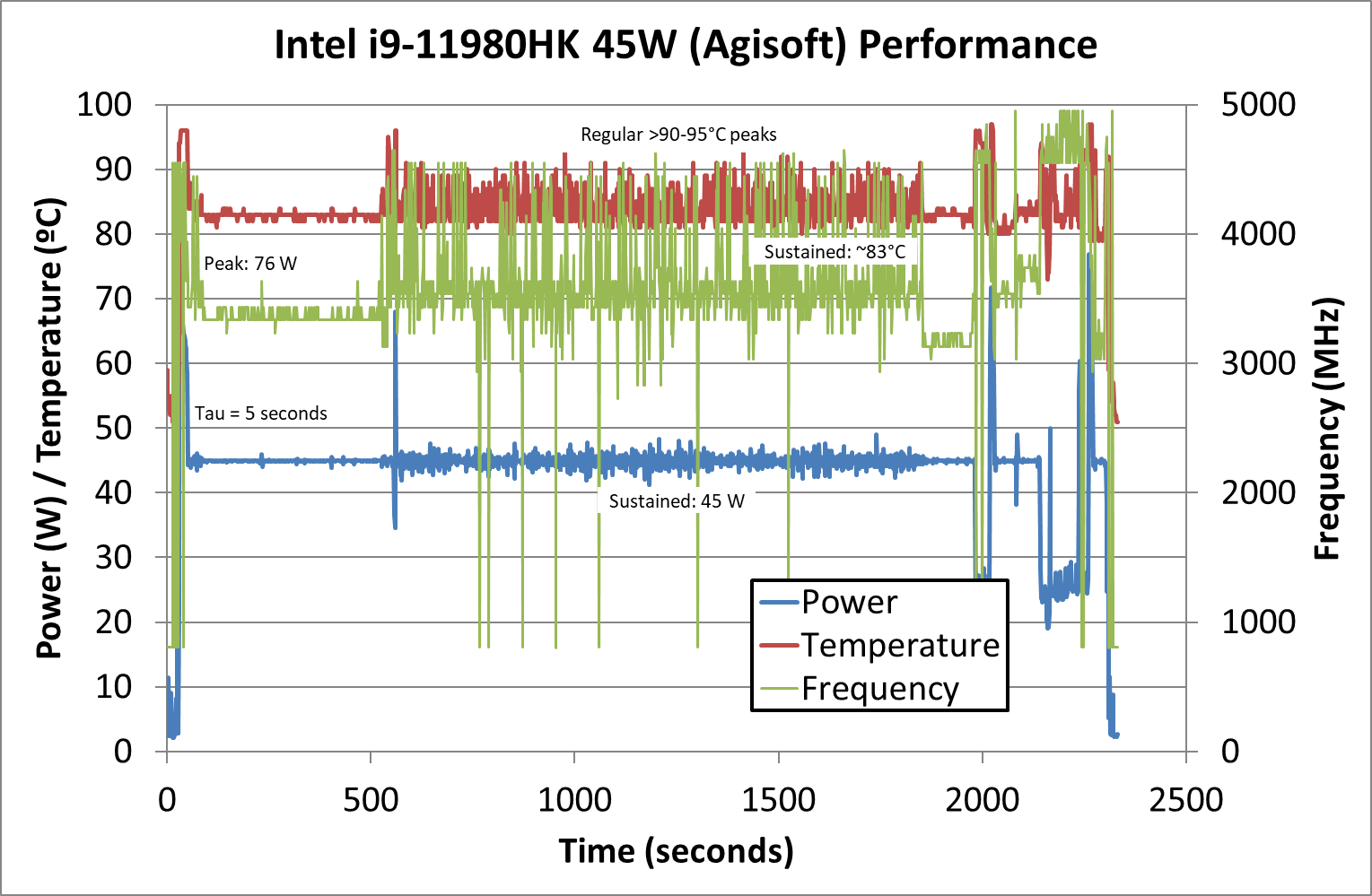
In more real-world full load workloads such as Agisoft, we’re seeing the i9-11980HK being able to have more aggressive boost frequencies due to the more dynamic and differentiated nature of the workload. Boost frequencies during the heft of the workload reach up to around 4.5GHz which is what Intel advertises as the nT turbo of the chip, while the rough average sits at around 3.5GHz. Towards the end of the test, we’re seeing lower core count boost frequencies reaching the near 5GHz 1-2T advertised boosts of the cores.
Still, what’s relatively concerning is that temperatures are still quite high even when tested in the 45W PL1 mode, we still see temperatures well in excess of 90°C and peaking at >95°C for transient periods.
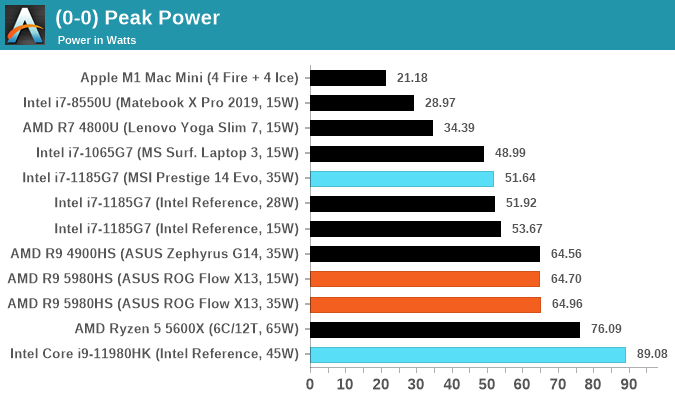
In terms of peak power comparisons, we see that the chip goes up to quite high transients, and has PL2 configurations of around 85-90W. Due to Tau and the turbo period here being only a mere 5 seconds, it shouldn’t affect thermals too much, and should give the system very good responsiveness, even though it will come at the cost of power and battery life.
Unfortunately, due to the embargo and extremely limited time we’ve had with the system we haven’t yet tested more power scenarios, such as 35W cTDP-down or unplugged battery-only behaviour of the platform. We’ll be following up with updates after today’s initial review.
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
In terms of the core-to-core tests on the Tiger Lake-H 11980HK, it’s best to actually compare results 1:1 alongside the 4-core Tiger Lake design such as the i7-1185G7:
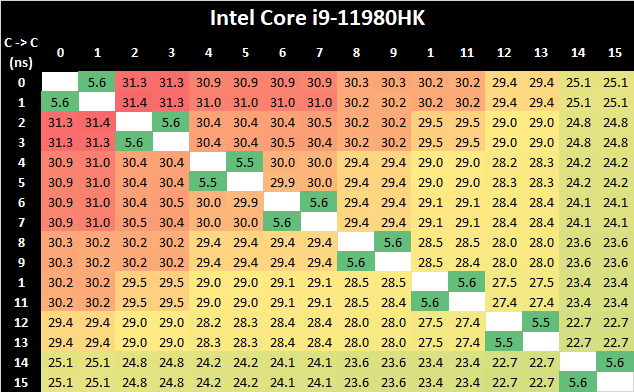

What’s very interesting in these results is that although the new 8-core design features double the cores, representing a larger ring-bus with more ring stops and cache slices, is that the core-to-core latencies are actually lower both in terms of best-case and worst-case results compared to the 4-core Tiger Lake chip.
This is generally a bit perplexing and confusing, generally the one thing to account for such a difference would be either faster CPU frequencies, or a faster clock of lower cycle latency of the L3 and the ring bus. Given that TGL-H comes 8 months after TGL-U, it is plausible that the newer chip has a more matured implementation and Intel would have been able to optimise access latencies.
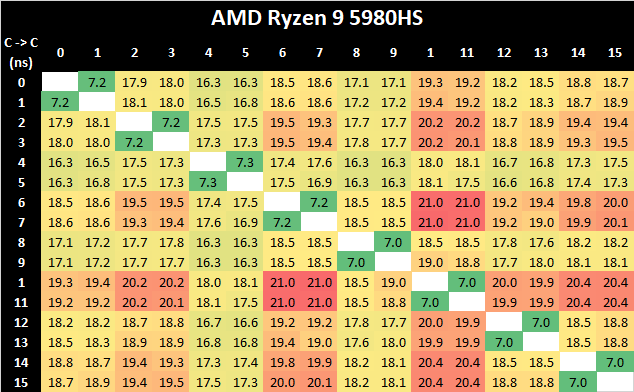
Due to AMD’s recent shift to a 8-core core complex, Intel no longer has an advantage in core-to-core latencies this generation, and AMD’s more hierarchical cache structure and interconnect fabric is able to showcase better performance.
Cache & DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
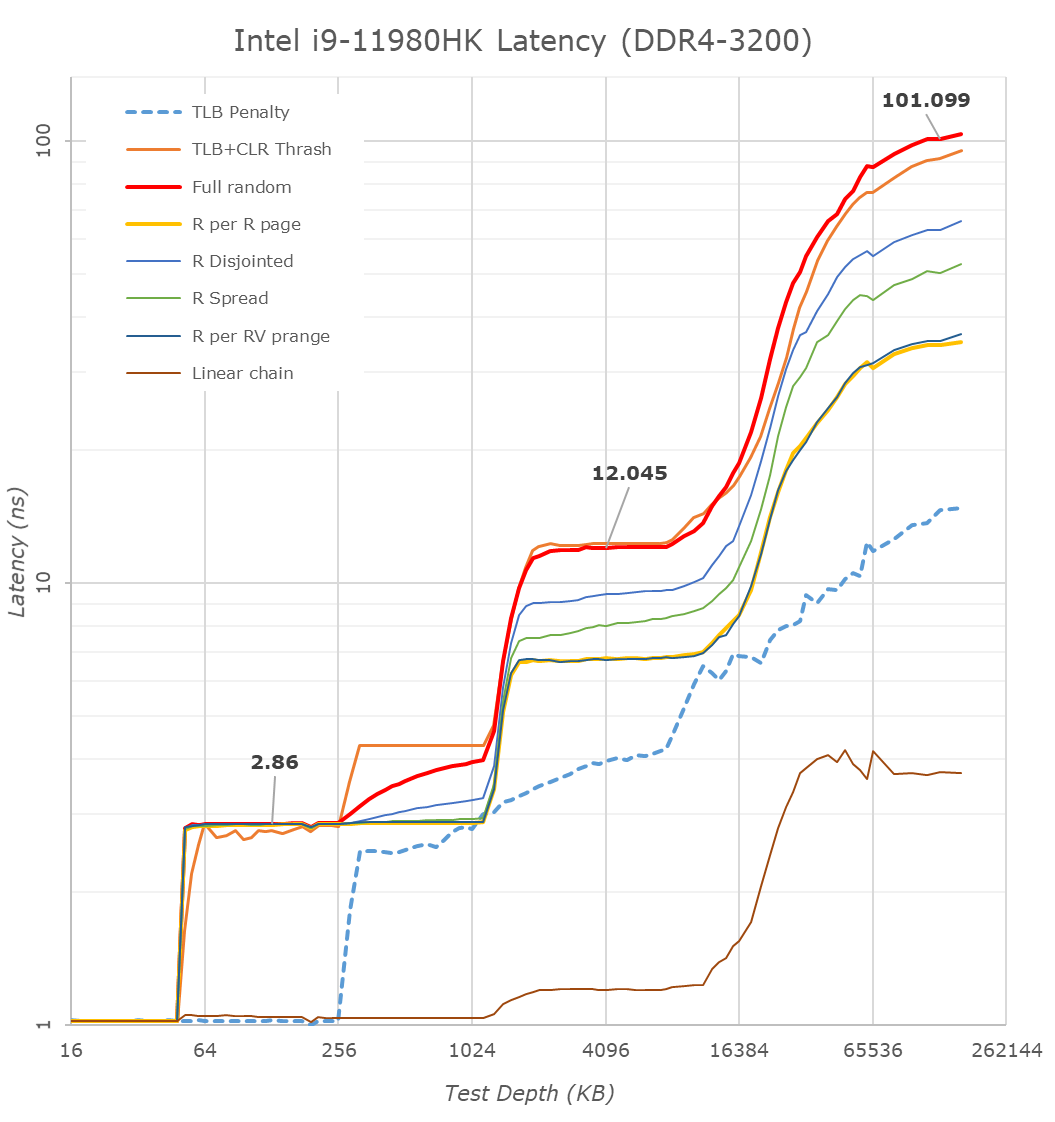
What’s of particular note for TGL-H is the fact that the new higher-end chip does not have support for LPDDR4, instead exclusively relying on DDR4-3200 as on this reference laptop configuration. This does favour the chip in terms of memory latency, which now falls in at a measured 101ns versus 108ns on the reference TGL-U platform we tested last year, but does come at a cost of memory bandwidth, which is now only reaching a theoretical peak of 51.2GB/s instead of 68.2GB/s – even with double the core count.
What’s in favour of the TGL-H system is the increased L3 cache from 12MB to 24MB – this is still 3MB per core slice as on TGL-U, so it does come with the newer L3 design which was introduced in TGL-U. Nevertheless, this fact, we do see some differences in the L3 behaviour; the TGL-H system has slightly higher access latencies at the same test depth than the TGL-U system, even accounting for the fact that the TGL-H CPUs are clocked slightly higher and have better L1 and L2 latencies. This is an interesting contradiction in context of the improved core-to-core latency results we just saw before, which means that for the latter Intel did make some changes to the fabric. Furthermore, we see flatter access latencies across the L3 depth, which isn’t quite how the TGL-U system behaved, meaning Intel definitely has made some changes as to how the L3 is accessed.
SPEC CPU - Single-Threaded Performance
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://[email protected]/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
Single-threaded performance of TGL-H shouldn’t be drastically different from that of TGL-U, however there’s a few factors which can come into play and affect the results: The i9-11980HK TGL-H system has a 200MHz higher boost frequency compared to the i7-1185G7, and a single core now has access to up to 24MB of L3 instead of just 12MB.
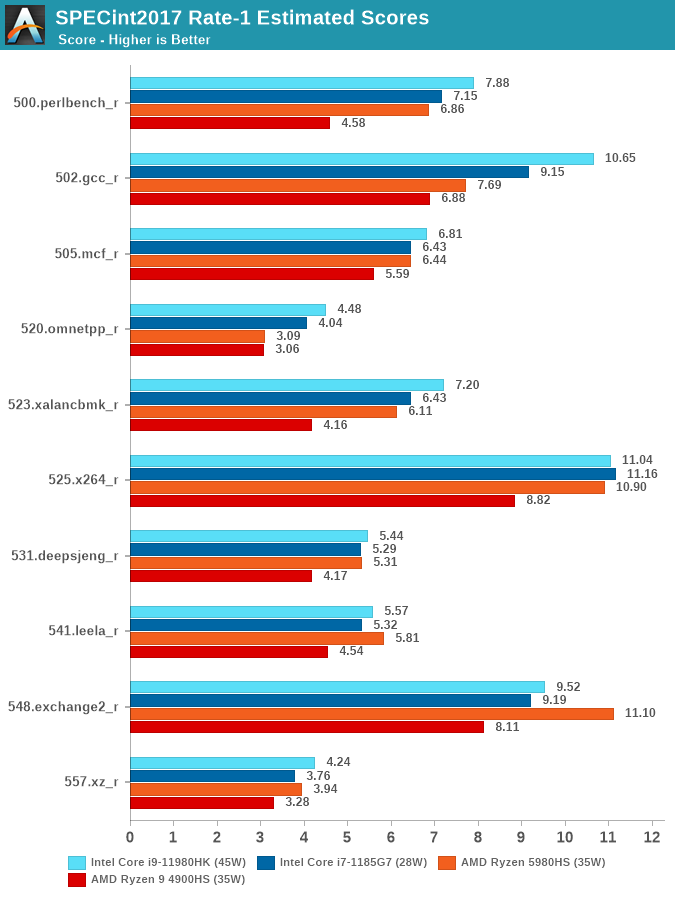
In SPECint2017, the one results which stands out the most if 502.gcc_r where the TGL-H processor lands in at +16% ahead of TGL-U, undoubtedly due to the increased L3 size of the new chip.
Generally speaking, the new TGL-H chip outperforms its brethren and AMD competitors in almost all tests.
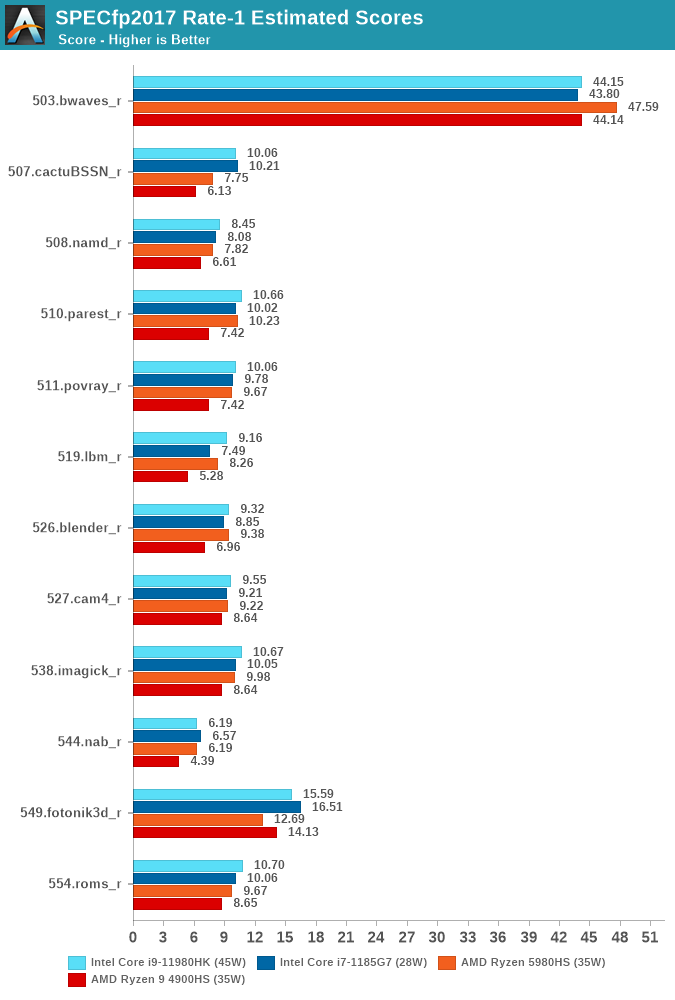
In the SPECfp2017 suite, we also see general small improvements across the board. The 549.fotonik3d_r test sees a regression which is a bit odd, but I think is related to the LPDDR4 vs DDR4 discrepancy in the systems which I’ll get back to in the next page where we’ll see more multi-threaded results related to this.
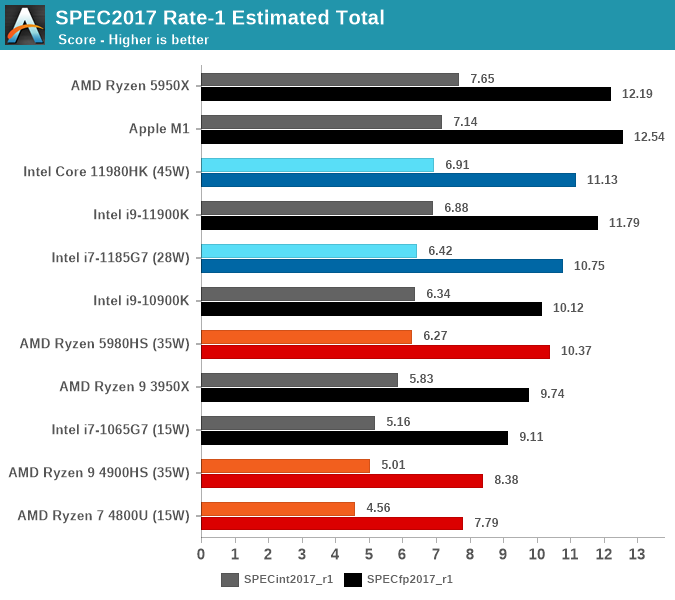
From an overall single-threaded performance standpoint, the TGL-H i9-11980HK adds in around +3.5-7% on top of what we saw on the i7-1185G7, which lands it amongst the best performing systems – not only amongst laptop CPUs, but all CPUs. The performance lead against AMD’s strongest mobile CPU, the 5980HS is even a little higher than against the i7-1185G7, but loses out against AMD’s best desktop CPU, and of course Apple M1 CPU and SoC used in the latest Macbooks. This latter comparison is apples-to-apples in terms of compiler settings, and is impressive given it does it at around 1/3rd of the package power under single-threaded scenarios.
SPEC CPU - Multi-Threaded Performance
Moving onto multi-threaded SPEC CPU 2017 results, these are the same workloads as on the single-threaded test (we purposefully avoid Speed variants of the workloads in ST tests). The key to performance here is not only microarchitecture or core count, but the overall power efficiency of the system and the levels of performance we can fit into the thermal envelope of the device we’re testing.
It’s to be noted that among the four chips I put into the graph, the i9-11980HK is the only one at a 45W TDP, while the AMD competition lands in at 35W, and the i7-1185G7 comes at a lower 28W. The test takes several hours of runtime (6 hours for this TGL-H SKU) and is under constant full load, so lower duration boost mechanisms don’t come into play here.
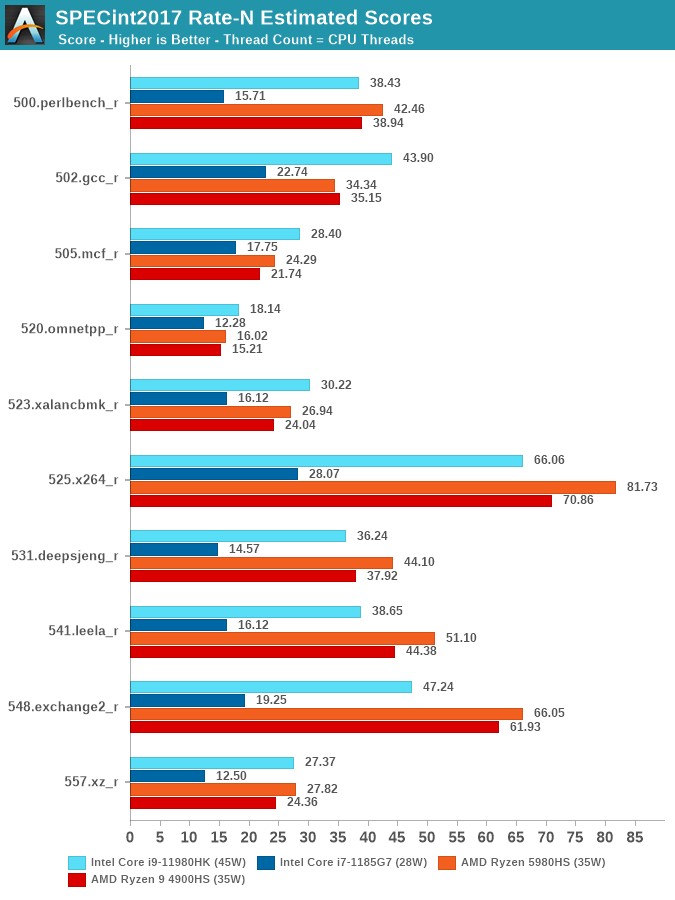
Generally as expected, the 8-core TGL-H chip leaves the 4-core TGL-U sibling in the dust, in many cases showcasing well over double the performance. The i9-11980HK also fares extremely well against the AMD competition in workloads which are more DRAM or cache heavy, however falls behind in other workloads which are more core-local and execution throughput bound. Generally that’d be a fair even battle argument between the designs, if it weren’t for the fact that the AMD systems are running at 23% lower TDPs.
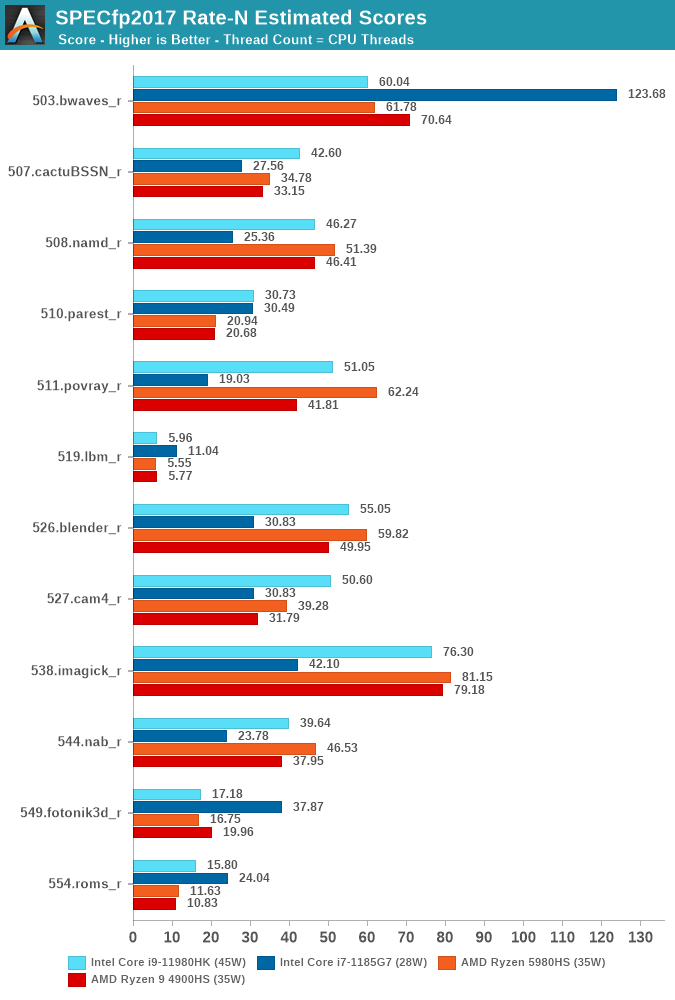
In the floating-point multi-threaded suite, we again see a similar competitive scenario where the TGL-H system battles against the best Cezanne and Renoir chips.
What’s rather odd here in the results is 503.bwaves_r and 549.fotonik_r which perform far below the numbers which we were able to measure on the TGL-U system. I think what’s happening here is that we’re hitting DRAM memory-level parallelism limits, with the smaller TGL-U system and its 8x16b LPDDR4 channel memory configuration allowing for more parallel transactions as the 2x64b DDR4 channels on the TGL-H system.
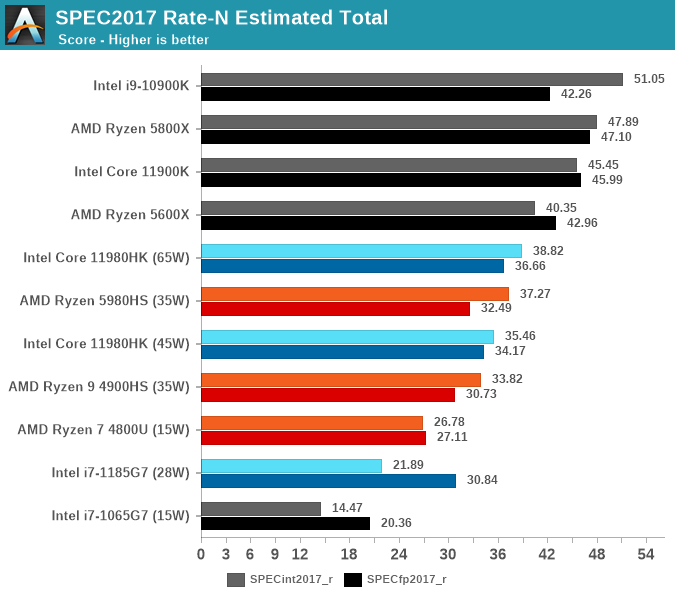
In terms of the overall performance, the 45W 11980HK actually ends up losing to AMD’s Ryzen 5980HS even with 10W more TDP headroom, at least in the integer suite.
We also had initially run the suite in 65W mode, the results here aren’t very good at all, especially when comparing it to the 45W results. For +40-44% TDP, the i9-11980HK in Intel’s reference laptop only performs +9.4% better. It’s likely here that this is due to the aforementioned heavy thermal throttling the system has to fall to, with long periods of time at 35W state, which pulls down the performance well below the expected figures. I have to be explicit here that these 65W results are not representative of the full real 65W performance capabilities of the 11980HK – just that of this particular thermal solution within this Intel reference design.
CPU Tests: Office and Science
Our previous set of ‘office’ benchmarks have often been a mix of science and synthetics, so this time we wanted to keep our office section purely on real world performance.
Agisoft Photoscan 1.3.3: link
The concept of Photoscan is about translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the final 3D model in both spatial accuracy and texturing accuracy. The algorithm has four stages, with some parts of the stages being single-threaded and others multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

For the update to version 1.3.3, the Agisoft software now supports command line operation. Agisoft provided us with a set of new images for this version of the test, and a python script to run it. We’ve modified the script slightly by changing some quality settings for the sake of the benchmark suite length, as well as adjusting how the final timing data is recorded. The python script dumps the results file in the format of our choosing. For our test we obtain the time for each stage of the benchmark, as well as the overall time.

In Agisoft Photoscan, the 11980HK is able to take a large performance leap ahead of the 1185G7 as well as the competition. Intel’s lead here undoubtedly comes also as part of the single-threaded performance advantage it has.
Application Opening: GIMP 2.10.18
First up is a test using a monstrous multi-layered xcf file to load GIMP for the first time. While the file is only a single ‘image’, it has so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This test is also the run where GIMP optimizes itself, and the optimization requirements scale linearlly with the number of threads in the system.
What we test here is the first run - normally on the first time a user loads the GIMP package from a fresh install, the system has to configure a few dozen files that remain optimized on subsequent opening. For our test we delete those configured optimized files in order to force a ‘fresh load’ each time the software in run. As it turns out, GIMP does optimizations for every CPU thread in the system, which requires that higher thread-count processors take a lot longer to run. So the test runs quick on systems with fewer threads, however fast cores are also needed.
We measure the time taken from calling the software to be opened, and until the software hands itself back over to the OS for user control. The test is repeated for a minimum of ten minutes or at least 15 loops, whichever comes first, with the first three results discarded.
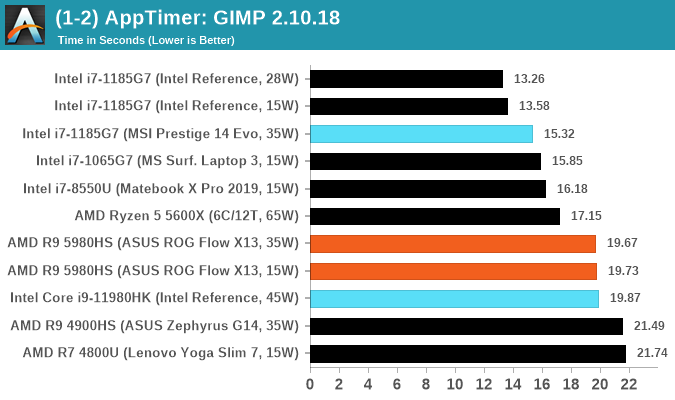
In AppTimer and GIMP, we’re seeing a bit of a weird result for the TGL-H system – I’m not too sure what’s happening here, so it’s something to investigate further once we have more time with the system.
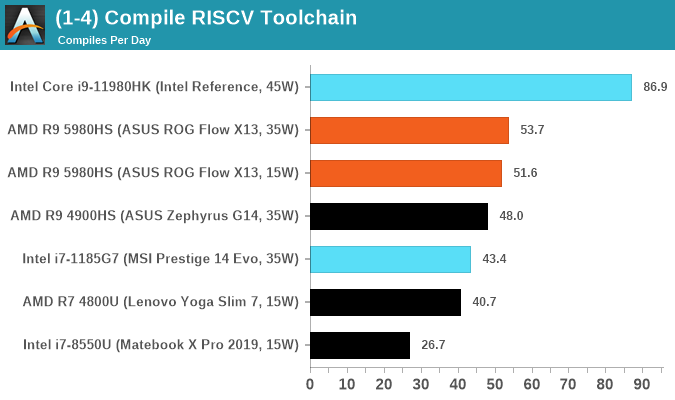
RISCV Toolchain Compile
Our latest test in our suite is the RISCV Toolchain compile from the Github source. This set of tools enables users to build software for a RISCV platform, however the tools themselves have to be built. For our test, we're running a complete fresh build of the toolchain, including from-stratch linking. This makes the test not a straightforward test of an updated compile on its own, but does form the basis of an ab initio analysis of system performance given its range of single-thread and multi-threaded workload sections. More details can be found here.
Science
In this version of our test suite, all the science focused tests that aren’t ‘simulation’ work are now in our science section. This includes Brownian Motion, calculating digits of Pi, molecular dynamics, and for the first time, we’re trialing an artificial intelligence benchmark, both inference and training, that works under Windows using python and TensorFlow. Where possible these benchmarks have been optimized with the latest in vector instructions, except for the AI test – we were told that while it uses Intel’s Math Kernel Libraries, they’re optimized more for Linux than for Windows, and so it gives an interesting result when unoptimized software is used.
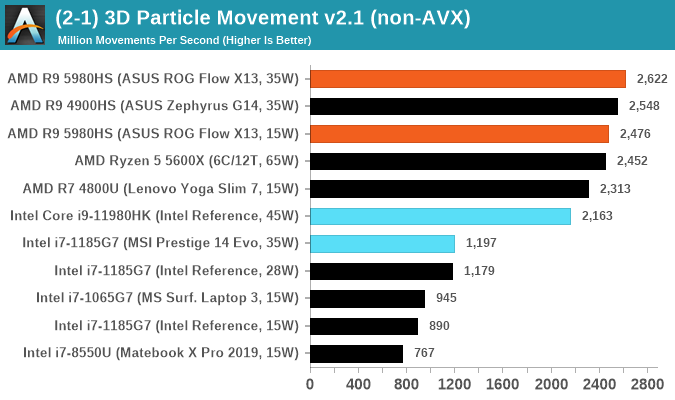
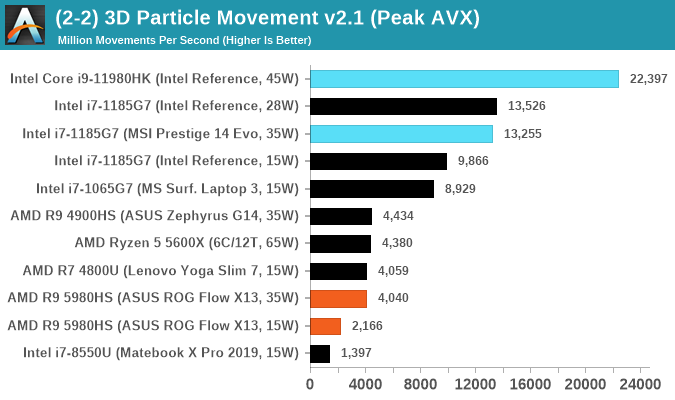
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of this benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, and flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.
For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The 3DPM test is set to output millions of movements per second, rather than time to complete a fixed number of movements.
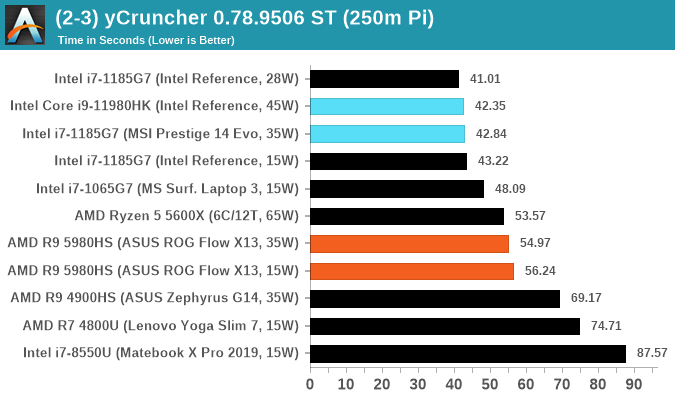
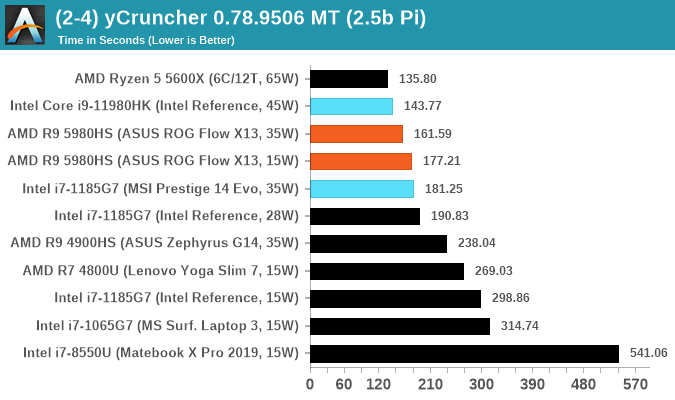
y-Cruncher 0.78.9506: www.numberworld.org/y-cruncher
If you ask anyone what sort of computer holds the world record for calculating the most digits of pi, I can guarantee that a good portion of those answers might point to some colossus super computer built into a mountain by a super-villain. Fortunately nothing could be further from the truth – the computer with the record is a quad socket Ivy Bridge server with 300 TB of storage. The software that was run to get that was y-cruncher.
Built by Alex Yee over the last part of a decade and some more, y-Cruncher is the software of choice for calculating billions and trillions of digits of the most popular mathematical constants. The software has held the world record for Pi since August 2010, and has broken the record a total of 7 times since. It also holds records for e, the Golden Ratio, and others. According to Alex, the program runs around 500,000 lines of code, and he has multiple binaries each optimized for different families of processors, such as Zen, Ice Lake, Sky Lake, all the way back to Nehalem, using the latest SSE/AVX2/AVX512 instructions where they fit in, and then further optimized for how each core is built.

For our purposes, we’re calculating Pi, as it is more compute bound than memory bound. In single thread mode we calculate 250 million digits, while in multithreaded mode we go for 2.5 billion digits. That 2.5 billion digit value requires ~12 GB of DRAM, and so is limited to systems with at least 16 GB.
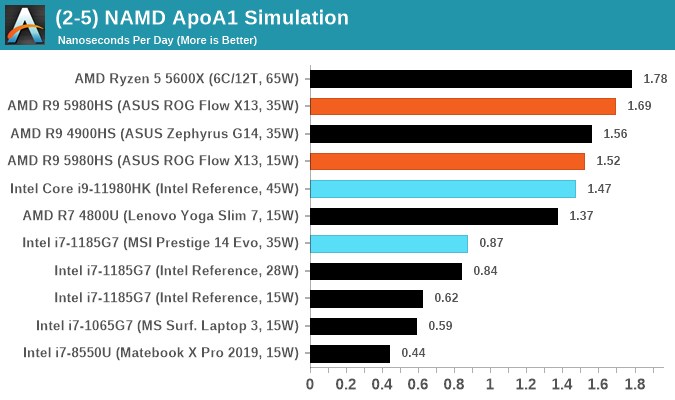
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modeling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps. We use version 2.13 as this was the recommended version at the time of integrating this benchmark into our suite. The latest nightly builds we’re aware have started to enable support for AVX-512, however due to consistency in our benchmark suite, we are retaining with 2.13. Other software that we test with has AVX-512 acceleration.
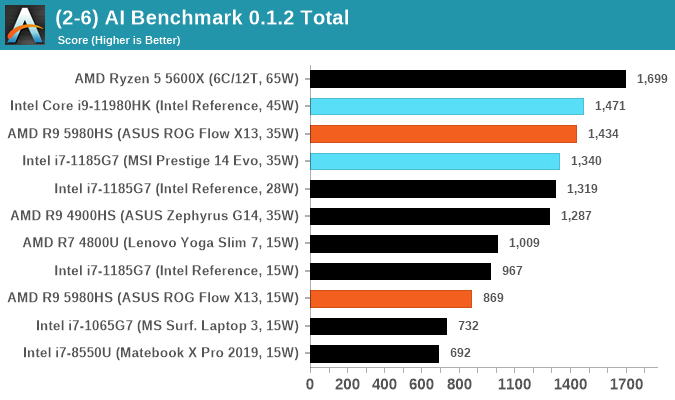
AI Benchmark 0.1.2 using TensorFlow: Link
Finding an appropriate artificial intelligence benchmark for Windows has been a holy grail of mine for quite a while. The problem is that AI is such a fast moving, fast paced word that whatever I compute this quarter will no longer be relevant in the next, and one of the key metrics in this benchmarking suite is being able to keep data over a long period of time. We’ve had AI benchmarks on smartphones for a while, given that smartphones are a better target for AI workloads, but it also makes some sense that everything on PC is geared towards Linux as well.
Thankfully however, the good folks over at ETH Zurich in Switzerland have converted their smartphone AI benchmark into something that’s useable in Windows. It uses TensorFlow, and for our benchmark purposes we’ve locked our testing down to TensorFlow 2.10, AI Benchmark 0.1.2, while using Python 3.7.6.

The benchmark runs through 19 different networks including MobileNet-V2, ResNet-V2, VGG-19 Super-Res, NVIDIA-SPADE, PSPNet, DeepLab, Pixel-RNN, and GNMT-Translation. All the tests probe both the inference and the training at various input sizes and batch sizes, except the translation that only does inference. It measures the time taken to do a given amount of work, and spits out a value at the end.
There is one big caveat for all of this, however. Speaking with the folks over at ETH, they use Intel’s Math Kernel Libraries (MKL) for Windows, and they’re seeing some incredible drawbacks. I was told that MKL for Windows doesn’t play well with multiple threads, and as a result any Windows results are going to perform a lot worse than Linux results. On top of that, after a given number of threads (~16), MKL kind of gives up and performance drops of quite substantially.
So why test it at all? Firstly, because we need an AI benchmark, and a bad one is still better than not having one at all. Secondly, if MKL on Windows is the problem, then by publicizing the test, it might just put a boot somewhere for MKL to get fixed. To that end, we’ll stay with the benchmark as long as it remains feasible.
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
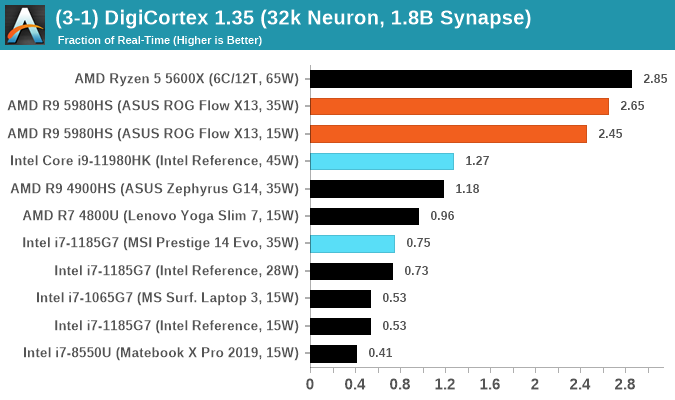
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
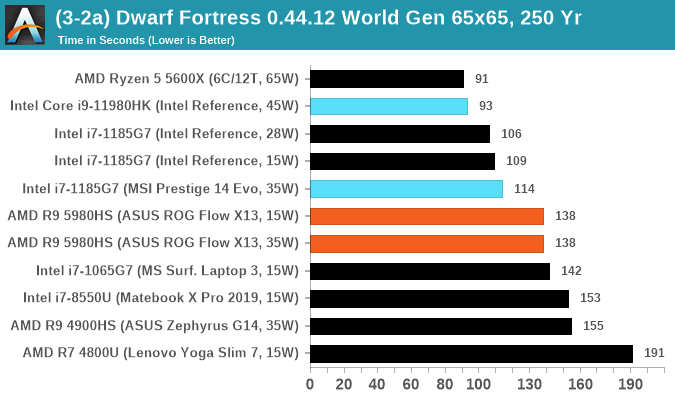
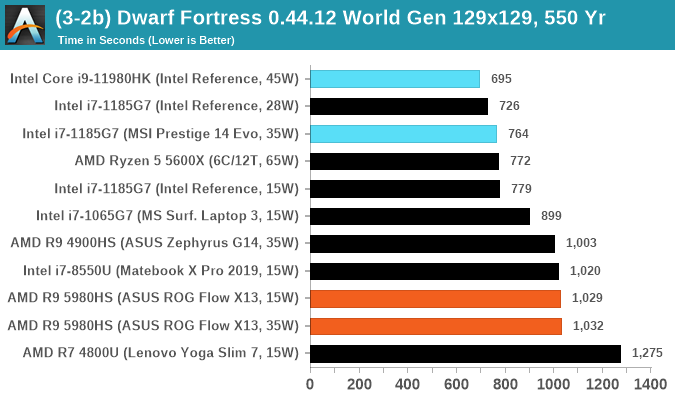
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.

CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.

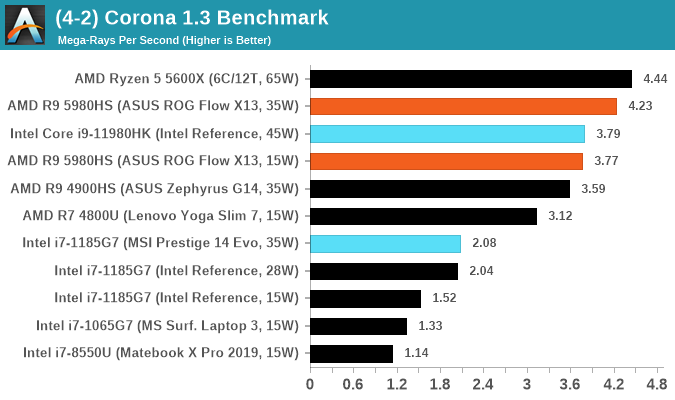
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).

The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
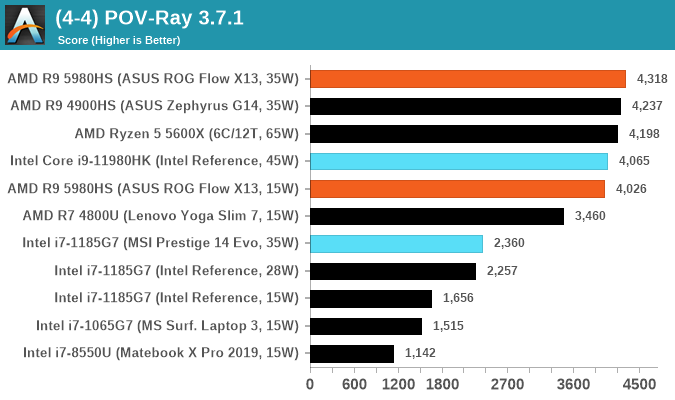
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.

The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
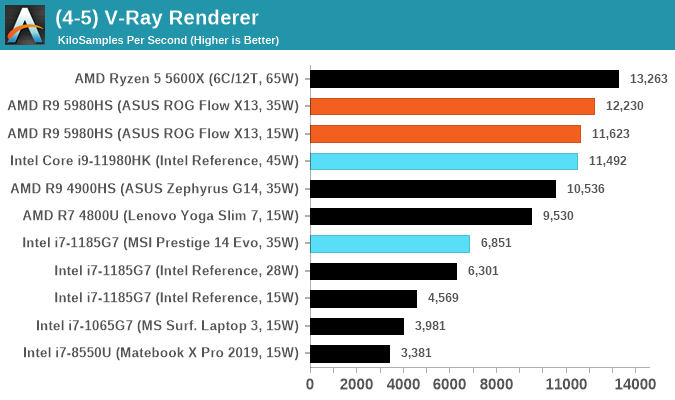
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
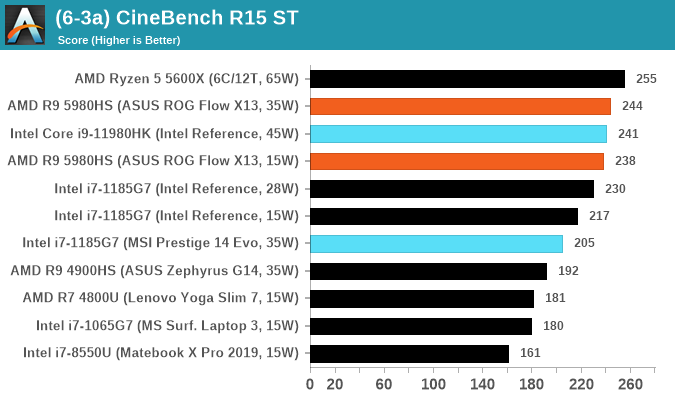
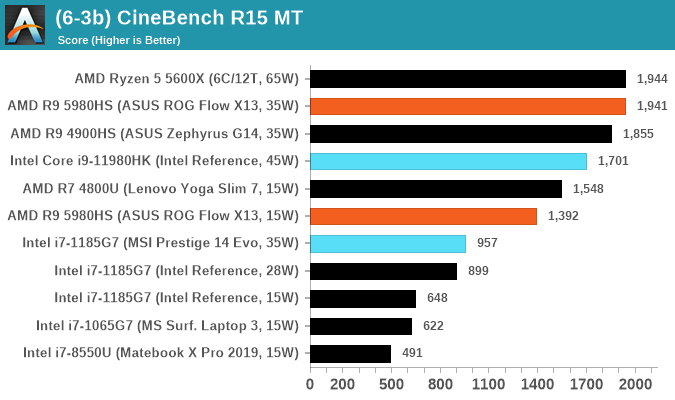
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
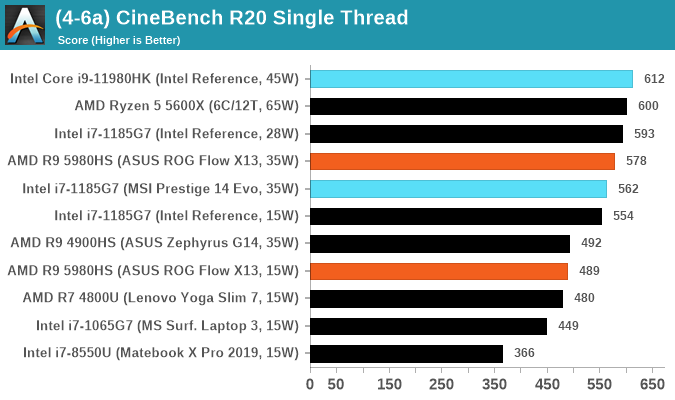
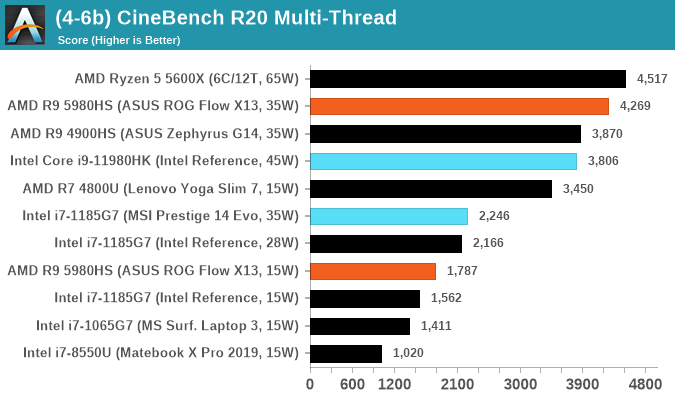
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
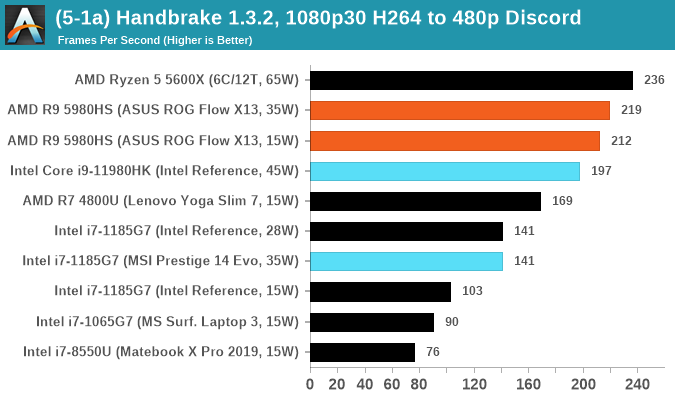
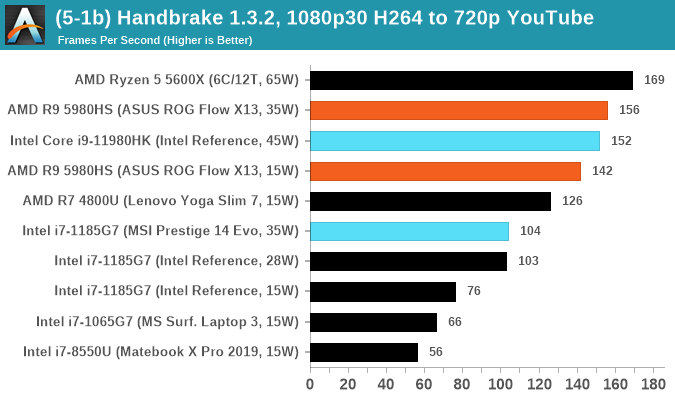
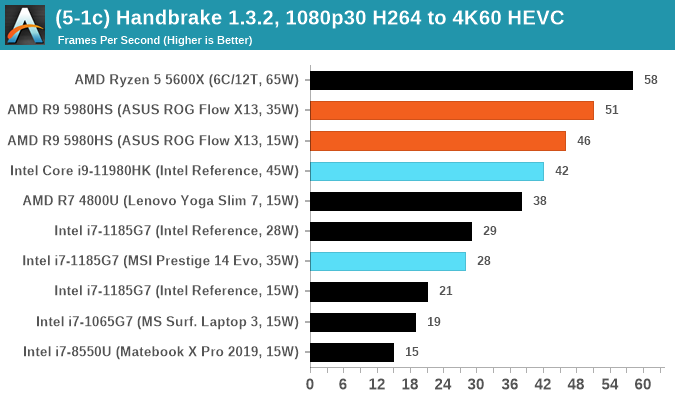
Threads wins, although the +30W difference to the desktop processor with two fewer cores can't be overhauled. Almost though.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
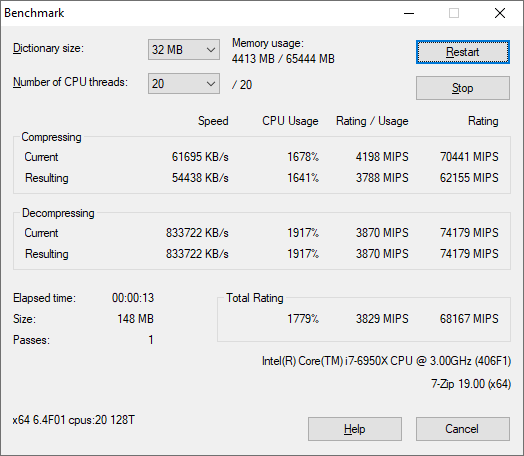
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
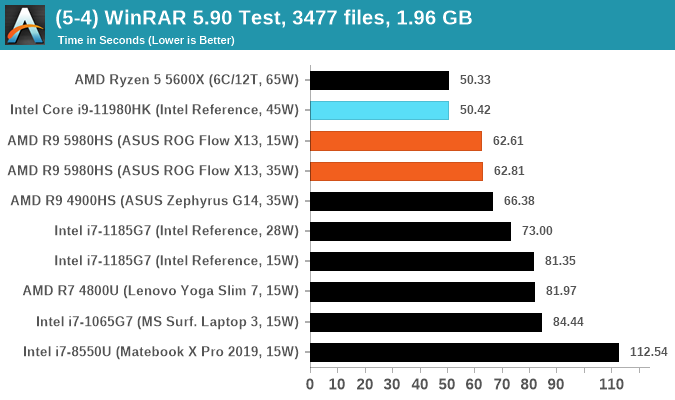
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
CPU Tests: Legacy and Web
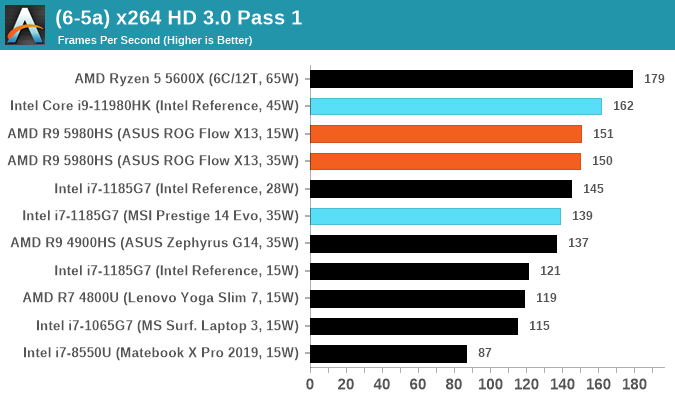
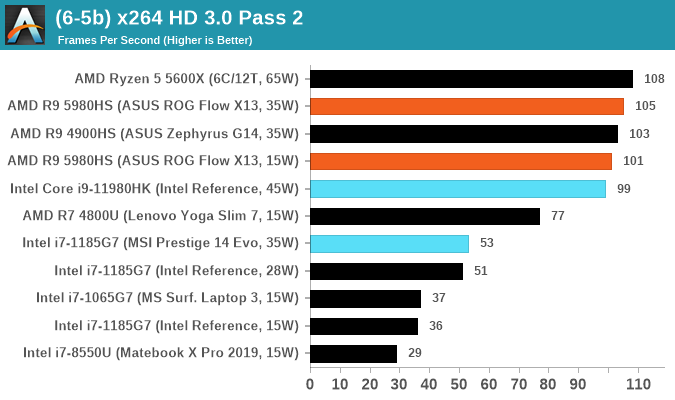
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
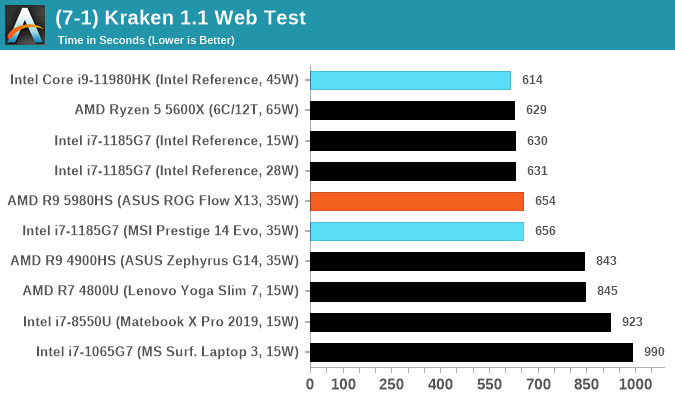
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.

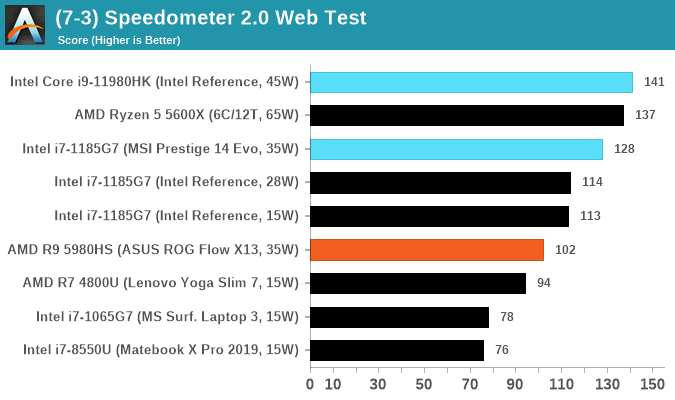
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
We repeat over the benchmark for a dozen loops, taking the average of the last five.
Legacy Tests
CPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
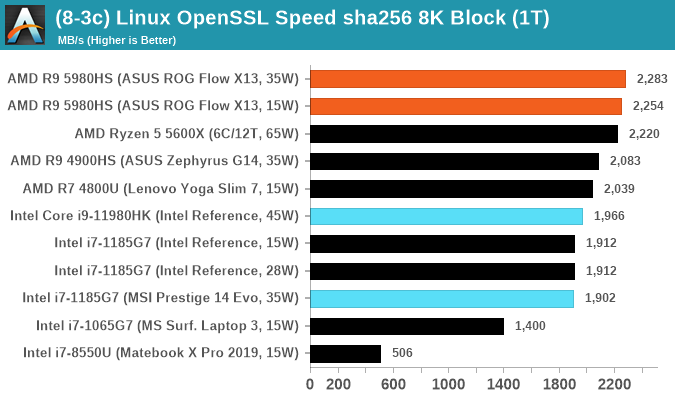
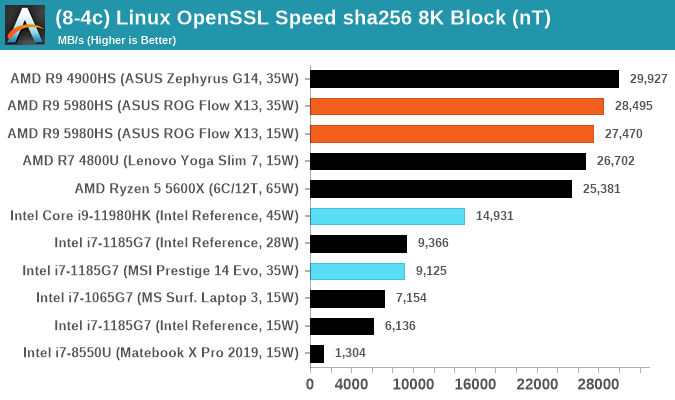
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
Unfortunately we are not going to include the Intel GB5 results in this review, although you can find them inside our benchmark database. The reason behind this is down to AVX512 acceleration of GB5's AES test - this causes a substantial performance difference in single threaded workloads that thus sub-test completely skews any of Intel's results to the point of literal absurdity. AES is not that important of a real-world workload, so the fact that it obscures the rest of GB5's subtests makes overall score comparisons to Intel CPUs with AVX512 installed irrelevant to draw any conclusions. This is also important for future comparisons of Intel CPUs, such as Rocket Lake, which will have AVX512 installed. Users should ask to see the sub-test scores, or a version of GB5 where the AES test is removed.
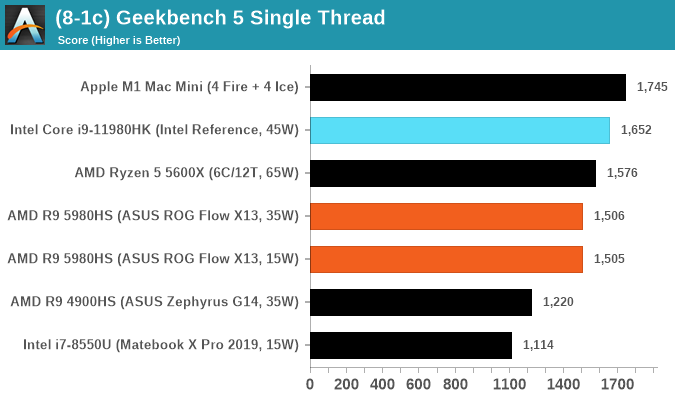
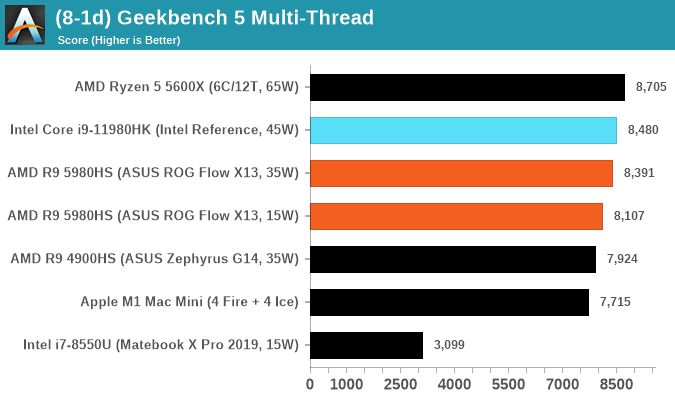
To clarify the point on AES. The Core i9-10900K scores 1878 in the AES test, while 1185G7 scores 4149. While we're not necessarily against the use of accelerators especially given that the future is going to be based on how many and how efficient these accelerators work (we can argue whether AVX-512 is efficient compared to dedicated silicon), the issue stems from a combi-test like GeekBench in which it condenses several different (around 20) tests into a single number from which conclusions are meant to be drawn. If one test gets accelerated enough to skew the end result, then rather than being a representation of a set of tests, that one single test becomes the conclusion at the behest of the others, and it's at that point the test should be removed and put on its own. GeekBench 4 had memory tests that were removed for Geekbench 5 for similar reasons, and should there be a sixth GeekBench iteraction, our recommendation is that the cryptography is removed for similar reasons. There are 100s of cryptography algorithms to optimize for, but in the event where a popular tests focuses on a single algorithm, that then becomes an optimization target and becomes meaningless when the broader ecosystem overwhelmingly uses other cryptography algorithms.
Conclusion: Powerful, but Power Hungry
After last week’s reveal of Tiger Lake-H, today’s results put things into context for Intel’s new high-end enthusiast mobile platform. The new design follows roughly 8 months after our initial coverage of the lower power “regular” Tiger Lake design and SKUs. The question is whether the new Tiger Lake-H can differentiate itself beyond just the notion that it’s a doubled-up core count variant of the lower power models.
I’ll have to reiterate that our review today isn’t nearly as in-depth as usual – due to circumstances we’ve essentially only had 2 days’ worth of testing of Intel’s reference Tiger Lake-H laptop, however in this time I think we can come to some crucial conclusions as to how the design performs and where it positions itself against the competition.
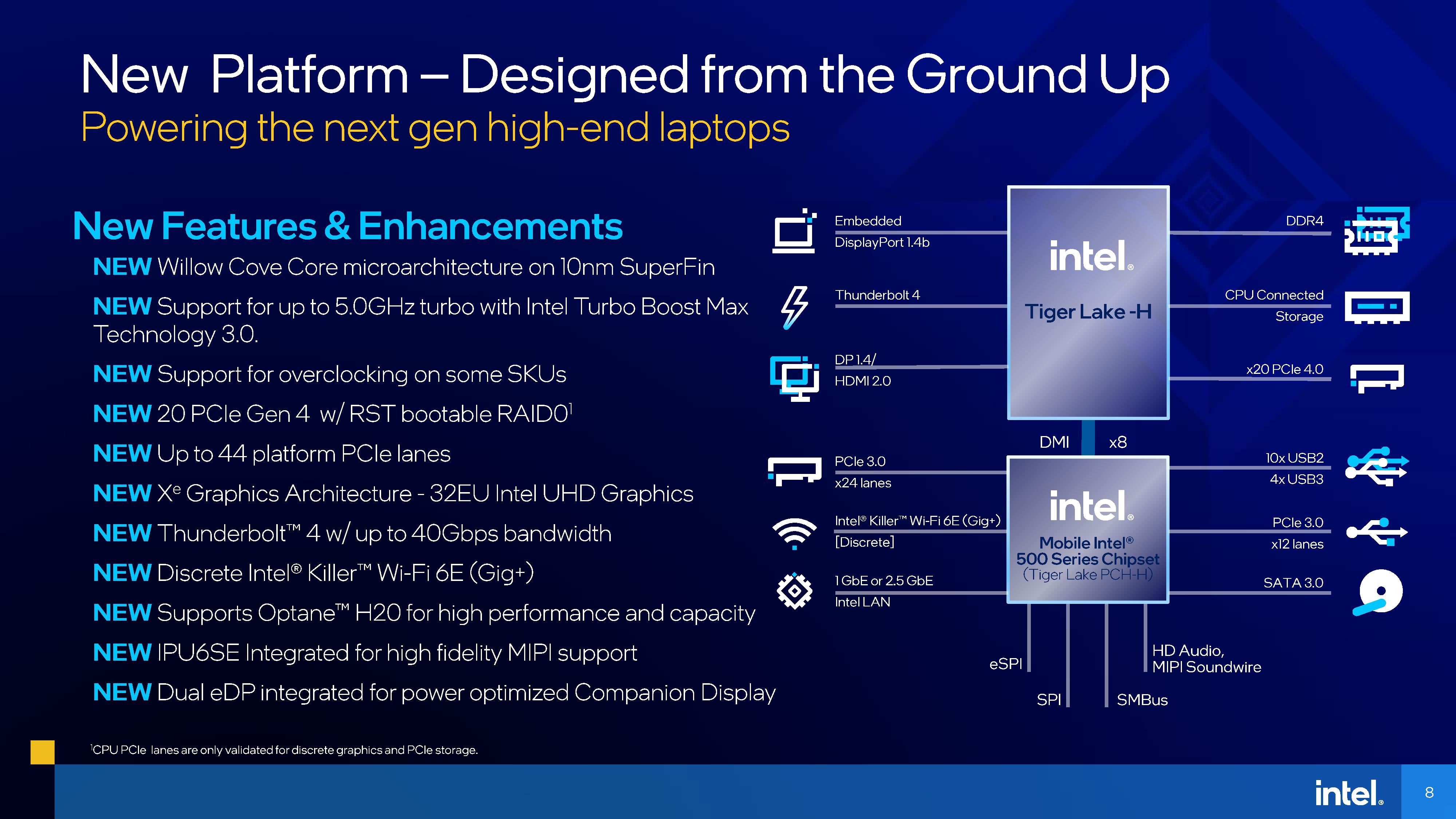
From a feature perspective, the new Tiger Lake-H platform seemingly delivers, offering up the necessary I/O and platform features to enable it to compete in the super high-end enthusiast and desktop-replacement laptop market.
Obvious requirements for this segment are also unquestioned performance metrics, and it’s here where things become rather complicated for the new 8-core Willow Cove design.
The area where the new TGL-H and particularly today’s tested Core i9-11980HK performs extremely well and is undoubtedly the leader among mobile x86 CPUs, is in its single-threaded performance. The new Willow Cove CPU cores alongside with the extremely high 5GHz boost frequencies achieved by the chip means that it manages to differentiate itself to even AMD’s more recent Cezanne Zen3 based Ryzen Mobile chips. While the performance lead isn’t large, it’s extremely solid at a 7-10% advantage throughout a very large number of workloads throughout our test suite.
Where things are quite as straightforward, is the multi-threaded performance, as this is where we have to mention TDPs, power limits, and just the result of the Intel reference platform laptop we’ve tested today.
The system, as delivered by Intel, came with a default maximum 65W cTDP/PL1 setting, which is the i9 11980HK’s maximum advertised power setting. Unfortunately for the SKU, the reference laptop’s thermal design was not able to keep up with the power output of the chip under this setting, and we had to revert the system to Intel’s advertised default 45W PL1 setting for the chip. The 65W mode was just not sustainable, with noticeable thermal tripping down to 35W as well as peak temperatures of up to 96°C. In our multi-threaded SPEC tests, we saw the 65W mode only perform 9% better than the 45W mode even though in theory it’s supposed to have a 44% larger thermal envelope.
At 45W, the multi-threaded performance of the chip is well sustainable and reasonable for this kind of device form-factor and cooling solution, but here it needs to be put into context, particularly against the nearest competition, which is AMD’s Ryzen 9 5980HS. In our benchmarks, both the Core i9-11980HK and the Ryzen 9 5980HS battle it out, sometimes with the Intel chip coming ahead, sometimes with the AMD chip leading the results. The issue with this comparison though is that we’re comparing a 45W chip vs a 35W chip, and more often in compute heavy workloads such as rendering or encoding, the AMD chip comes ahead even though it has a lower TDP.
Intel’s new 10nm SuperFin process had promised to finally outperform the mature 14nm node – while we couldn’t get to a definitive conclusion based on the initial 4-core Tiger Lake designs due to the smaller core numbers, here in 8-core vs 8-core scenario at their latest microarchitecture implementations, we can still see that Intel is lagging behind in terms of efficiency versus AMD’s 7nm CPUs.
This leads us to the conclusion and question for whom the new Tiger Lake-H designs are meant for. The market in recent years has generally attempted to switch away from bulkier desktop-replacement laptops, but it’s precisely this product segment which seems to be what Intel is targeting with TGL-H. A thicker device with more robust cooling capabilities would certainly unleash the new 8-core design’s performance, but unfortunately, exactly where this performance would end up is something we unfortunately weren’t able to answer in today’s piece.
The rest of the market generally is pivoting towards high-performance compact designs within that crucial <20mm thickness. While Tiger Lake-H here certainly delivers large generational performance improvements to previous SKUs in the H-series, such as Comet Lake-H, it doesn’t seem to be sufficient to quite catch up to the AMD alternatives which while maybe not as performant in every workload, do win it out on an efficiency basis.
As Intel noted in its launch event, Tiger Lake-H is said to already have 80+ enthusiast designs in the works, likely to come out in the next few months to rest of the year. The final verdict on TGL-H will be in final commercial products, which we expect to see in the next month or two.






