Original Link: https://www.anandtech.com/show/16921/intel-sapphire-rapids-nextgen-xeon-scalable-gets-a-tiling-upgrade
Intel Xeon Sapphire Rapids: How To Go Monolithic with Tiles
by Dr. Ian Cutress on August 31, 2021 10:00 AM EST
One of the critical deficits Intel has to its competition in its server platform is core count – other companies are enabling more cores by one of two routes: smaller cores, or individual chiplets connected together. At its Architecture Day 2021, Intel has disclosed features about its next-gen Xeon Scalable platform, one of which is the move to a tiled architecture. Intel is set to combine four tiles/chiplets through its fast embedded bridges, leading to better CPU scalability at higher core counts. As part of the disclosure, Intel also expanded on its new Advanced Matrix Extension (AMX) technology, CXL 1.1 support, DDR5, PCIe 5.0, and an Accelerator Interfacing Architecture that may lead to custom Xeon CPUs in the future.
What is Sapphire Rapids?
Built on an Intel 7 process, Sapphire Rapids (SPR) will be Intel’s next-generation Xeon Scalable server processor for its Eagle Stream platform. Using its latest Golden Cove processor cores which we detailed last week, Sapphire Rapids will bring together a number of key technologies for Intel: Acceleration Engines, native half-precision FP16 support, DDR5, 300-Series Optane DC Persistent Memory, PCIe 5.0, CXL 1.1, a wider and faster UPI, its newest bridging technology (EMIB), new QoS and telemetry, HBM, and workload specialized acceleration.
Set to launch in 2022, Sapphire Rapids will be Intel’s first modern CPU product to take advantage of a multi-die architecture that aims to minimize latency and maximize bandwidth due to its Embedded Multi-Die Interconnect Bridge technology. This allows for more high-performance cores (Intel hasn’t said how many just quite yet), with the focus on ‘metrics that matter for its customer base, such as node performance and data center performance’. Intel is calling SPR the ‘Biggest Leap in DC Capabilities in a Decade’.

The headline benefits are easy to rattle off. PCIe 5.0 is an upgrade over the previous generation Ice Lake PCIe 4.0, and we move from six 64-bit memory controllers of DDR4 to eight 64-bit memory controllers of DDR5. But the bigger improvements are in the cores, the accelerators, and the packaging.
Golden Cove: A High-Performance Core with AMX and AIA
By using the same core design on its enterprise platform Sapphire Rapids and consumer platform Alder Lake, there are some of the same synergies we saw back in the early 2000s when Intel did the same thing. We covered Golden Cove in detail in our Alder Lake architecture deep dive, however here’s a quick recap:

The new core, according to Intel, will over a +19% IPC gain in single-thread workloads compared to Cypress Cove, which was Intel’s backport of Ice Lake. This comes down to some big core changes, including:
- 16B → 32B length decode
- 4-wide → 6-wide decode
- 5K → 12K branch targets
- 2.25K → 4K μop cache
- 5 → 6 wide allocation
- 10 → 12 execution ports
- 352 → 512-entry reorder buffer
The goal of any core is to process more things faster, and the newest generation tries to do it better than before. A lot of Intel’s changes make sense, and those wanting the deeper details are encouraged to read our deep dive.
There are some major differences between the consumer version of this core in Alder Lake and the server version in Sapphire Rapids. The most obvious one is that the consumer version does not have AVX-512, whereas SPR will have it enabled. SPR also has a 2 MB private L2 cache per core, whereas the consumer model has 1.25 MB. Beyond this, we’re talking about Advanced Matrix Extensions (AMX) and a new Accelerator Interface Architecture (AIA).
So far in Intel’s CPU cores we have scalar operation (normal) and vector operation (AVX, AVX2, AVX-512). The next stage up from that is a dedicated matrix solver, or something akin to a tensor core in a GPU. This is what AMX does, by adding a new expandable register file with dedicated AMX instructions in the form of TMUL instructions.

AMX uses eight 1024-bit registers for basic data operators, and through memory references, the TMUL instructions will operate on tiles of data using those tile registers. The TMUL is supported through a dedicated Engine Coprocessor built into the core (of which each core has one), and the basis behind AMX is that TMUL is only one such co-processor. Intel has designed AMX to be wider-ranging than simply this – in the event that Intel goes deeper with its silicon multi-die strategy, at some point we could see custom accelerators being enabled through AMX.
Intel confirmed that we shouldn’t see any frequency dips worse than AVX – there are new fine-grained power controllers per core for when vector and matrix instructions are invoked.

This feeds quite nicely into discussing AIA, the new accelerator interface. Typically when using add-in accelerator cards, commands must navigate between kernel and user space, set up memory, and direct any virtualization between multiple hosts. The way Intel is describing its new Acceleration Engine interface is akin to talking to a PCIe device as if it were simply an accelerator on board to the CPU, even though it’s attached through PCIe.

Initially, Intel will have two capable AIA bits of hardware.
Intel Quick Assist Technology (QAT) is one we’ve seen before, as it showcased inside special variants of Skylake Xeon’s chipset (that required a PCIe 3.0 x16 link) as well as an add-in PCIe card – this version will support up to 400 Gb/s symmetric cryptography, or up to 160 Gb/s compression plus 160 Gb/s decompression simultaneously, double the previous version.
The other is Intel’s Data Streaming Accelerator (DSA). Intel has had documentation about DSA on the web since 2019, stating that it is a high-performance data copy and transformation accelerator for streaming data from storage and memory or to other parts of the system through a DMA remapping hardware unit/IOMMU. DSA has been a request from specific hyperscaler customers, who are looking to deploy it within their own internal cloud infrastructure, and Intel is keen to point out that some customers will use DSA, some will use Intel’s new Infrastructure Processing Unit, while some will use both, depending on what level of integration or abstraction they are interested in. Intel told us that DSA is an upgrade over the Crystal Beach DMA engine which was present on the Purley (SKL+CLX) platforms.

On top of all this, Sapphire Rapids also supports AVX512_FP16 instructions for half-precision, mostly for AI workloads as part of its DLBoost strategy (Intel was quite quiet on DLBoost during the event). These FP16 commands can also be used as part of AMX, alongside INT8 and BF16 support. Intel now also supports CLDEMOTE for cache-line management.
A Side Word about CXL
Throughout the presentations of Sapphire Rapids, Intel has been keen to highlight it will support CXL 1.1 at launch. CXL is a connectivity standard designed to handle much more than what PCIe does – aside from simply acting as a data transfer from host to device, CXL has three branches to support, known as IO, Cache, and Memory. As defined in the CXL 1.0 and 1.1 standards, these three form the basis of a new way to connect a host with a device.
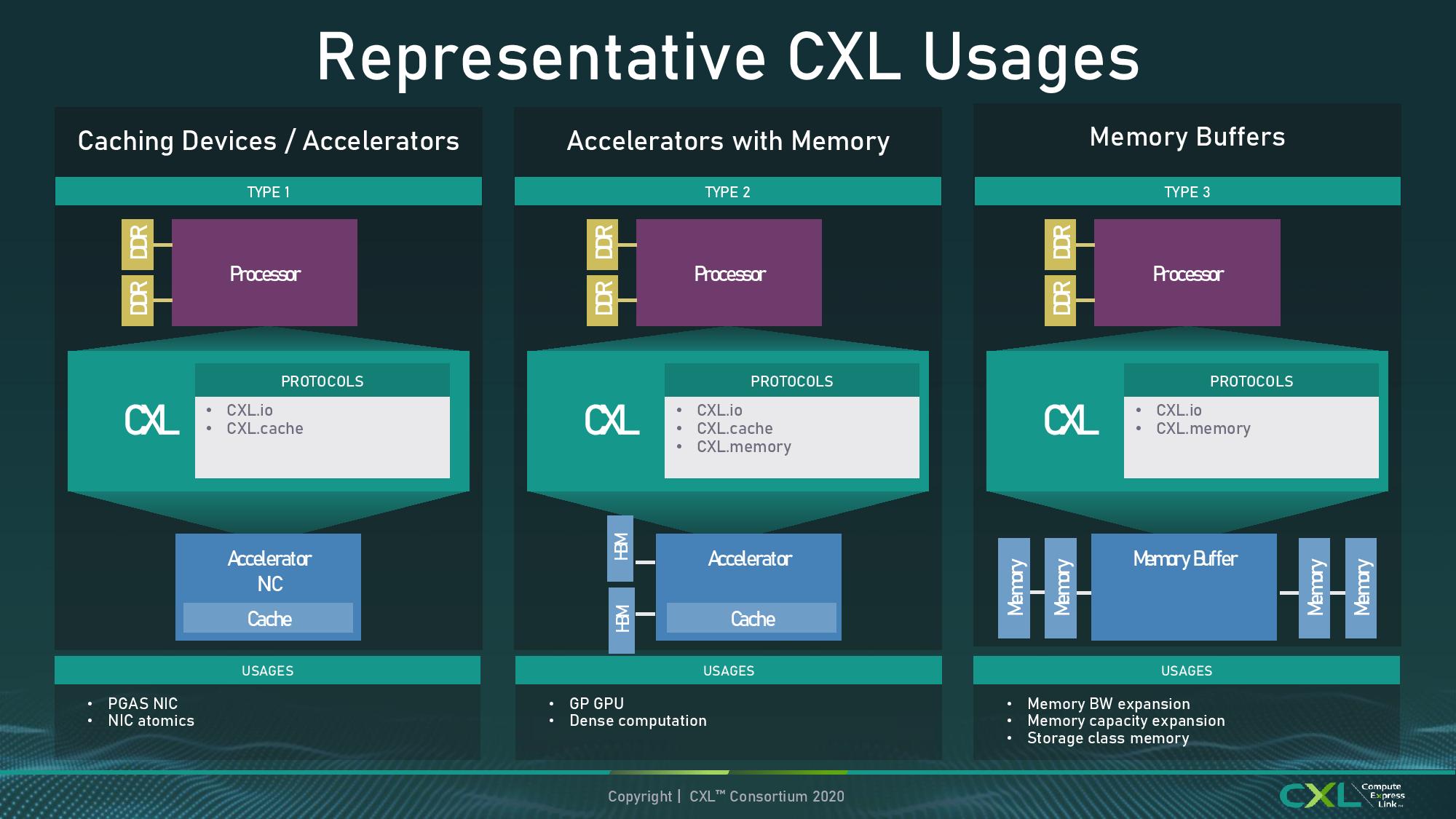
Naturally it was our expectation that all CXL 1.1 devices would support all three of these standards. It wasn’t until Hot Chips, several days later, that we learned Sapphire Rapids is only supporting part of the CXL standard, specifically CXL.io and CXL.cache, but CXL.memory would not be part of SPR. We're not sure to what extent this means SPR isn't CXL 1.1 compliant, or what it means for CXL 1.1 devices - without CXL.mem, as per the diagram above, all Intel loses is Type-2 support. Perhaps this is more of an indication that the market around CXL is better served by CXL 2.0, which will no doubt come in a later product.
In the next page, we look at Intel's new tiled architecture for Sapphire Rapids.
The March of More Silicon: Connectivity Matters
To date, all of Intel’s leading-edge Xeon Scalable processors have been monolithic, i.e. one piece of silicon. Having a single piece of silicon has its advantages, namely a fast in-silicon interconnect between cores but also a singular power interface to manage. However, as we move to smaller and smaller process nodes, having one large piece of silicon has downsides: they are hard to manufacture in volume without defects, which increases cost if you want the high-core count models, but also it ends up being limiting.

The alternative to a large monolithic design is to cut it up into smaller bits of silicon and connect them together. The main advantages here is better silicon yield, but also configurability by having different silicon for different functions as needed. With a multi-die design, you can ultimately end up with more silicon than a monolithic design can provide – the reticle (manufacturing) limit for a single silicon die is ~700-800 mm2, and with a multi-die processor several smaller silicon dies can be put together, easily pushing over 1000mm2. Intel has stated that each of its silicon tiles are ~400 mm2, creating a total around ~1600mm2. But the major downside to multi-die designs is connectivity and power.
The simplest way to package two chips in a substrate together is through intra-substrate connections, or what essentially amounts to PCB traces. This is a high-yielding process, however it has the two drawbacks listed above: connectivity and power. It costs more energy to send a bit over a PCB connection than it does through silicon, but also the bandwidth is much lower because the signals cannot be as densely packed. As a result, without careful planning, a multi-die connected product will have to be aware of how far data is at any one time, an issue few monolithic products have.
The way around this is with a faster interconnect. Rather than putting that connectivity through the substrate, through the package, what if it was through silicon anyway? By placing these connected dies on a piece of silicon, such as an interposer, the connectivity traces have better signal integrity, and better power. Using an interposer, this is commonly referred to as 2.5D packaging. It costs a bit more than standard packaging technology (there’s also scope for active interposers with logic), but we also have another limitation in that the interposer has to be bigger than all the silicon put together. But overall, this is a better option, especially if you want your multi-die product to act as if it were monolithic.

Intel decided that the best way to beat the downsides of interposers but still get the benefits of an effective monolithic silicon design was instead was to create super small interposers that lived inside the substrate. By pre-embedding them in the right location, with the right packaging tools two chips could be placed on this small Embedded Multi-Die Interconnect Bridge (EMIB), and voilà, a system that works as close to a monolithic design as is physically possible.
Intel has worked on the EMIB technology for over a decade. The development has had three major milestones from our perspective: (1) being able to embed the bridge into a package with a high yield, (2) being able to place big silicon die on the bridge at high yield, and (3) being able to put two high-powered die next to each other on a bridge. It is that third part that I think Intel has struggled with the most – by having two high-powered die next to each other, especially if the die have different coefficients of thermal expansion and different thermal properties, there is the potential of weakening the substrate around the bridge or the connections to the bridge itself. Almost all of Intel’s products that used EMIB so far have been around connecting a CPU/GPU to high-bandwidth memory, which is an order of magnitude lower power than what it’s being connected to. Because of that, I wasn’t convinced putting two high-powered tiles together possible, at least until Intel announced a multi-die FPGA connected by EMIB using two high-powered FPGA tiles in late 2019. From that point on, it was only a moment in time before Intel enabled the technology on its CPU product stack. We’re finally getting that with Sapphire Rapids.
10x EMIB on Sapphire Rapids
Sapphire Rapids is going to be using four tiles connected with 10 EMIB connections using a 55-micron connection pitch. Normally you might think that a 2x2 array of tiles would need equal EMIBs per tile-to-tile connection, so in this case with 2 EMIBs per connection, that would be eight – why is Intel quoting 10 here? That comes down to the way Sapphire Rapids is designed.
Because Intel wants SPR to look monolithic to every operating system, Intel has essentially cut its inter-core mesh horizontally and vertically. That way each connection through the EMIB is seen purely as the next step on the mesh. But Intel’s monolithic designs are not symmetric in either of those dimensions – usually features like the PCIe or QPI are on the edges, and not in the same place in every corner. Intel has told us that in Sapphire Rapids, this is similarly the case, and one dimension is using 3 EMIBs per connection while the other dimension is using 2 EMIBs per connection.
By avoiding strict rotational symmetry in its design, and without a central IO hub, Intel is leaning heavily to acting as a monolithic die – leaning so heavily it’s almost falling over to do so. As long as the EMIB connections are consistent between tiles, software shouldn’t have to worry, although until we get further details here, it’s hard to speculate exactly why without going through the motions of trying to figure out Intel’s mesh designs and how the extra parts all connect together. SPR sounds like a monolithic design cut up, rather than a ground-up multi-die design, if that makes sense.
Intel announced earlier this year that it will make an HBM version of Sapphire Rapids, using four HBM tiles. These will also be connected by EMIB, one per tile.
Tiles Tiles Tiles
Intel did give an insight into what exactly each of the separate tiles will have inside it, however this was extremely high level:

Each tile has:
- cores, cache, and mesh
- A memory controller with 2x64-bit DDR5 channels
- UPI links
- Accelerator links
- PCIe links
In this situation, and throughout the presentation, it looks like all four tiles are equal, with the rotational symmetry I mentioned above. To make silicon that does this, in the way presented, isn’t as easy as mirroring the design and printing that onto a silicon wafer. The crystal plane of the wafer limits how designs can be built, and so any mirroring has to be redesigned completely. As a result, Intel confirmed that it has to use two different sets of masks to build Sapphire Rapids, one each for the two dies it has to make. It can then rotate each of these two dies to build the 2x2 tile grid as shown.
It’s worth comparing this to AMD’s first-generation EPYC, which also used a 2x2 chiplet method, albeit with connectivity through the package. AMD escaped the need for having multiple silicon designs by having it rotationally symmetric – AMD built four die-to-die interfaces on the silicon, but only used three for each rotation. It’s a cheaper solution (and one that was right for AMD’s financial situation at the time) at the cost of die area, but also enables a level of simplicity. AMD’s central IO die method in newer EPYCs moves away from this issue entirely. From my perspective, it’s something Intel is going to have to move towards if they want to scale beyond SPR but also for a different reason.
As it stands, each of the tiles holds 128-bits of DDR5 memory interfaces, for a total of 512-bits across all four tiles. Physically, this means we will see eight 64-bit memory controllers* for either eight or sixteen memory modules per socket in a system. That’s perfectly fine for versions of Sapphire Rapids with all four compute tiles.
However, we know that the Sapphire Rapids processor offering is going to have to scale down to fewer cores. In the past, Intel would create three different silicon monolithic variations to cater for these markets and optimize silicon output, but all the processors would have the same memory controller count.
This means that if SPR is going to offer versions with fewer cores, it is going to either create dummy tiles without any cores on them, but still keep the PCIe/DDR5 as required, or quite simply those lower core counts are going to have fewer memory controllers. That’s going to be a pain for system manufactures who want to build catch-all systems, because they’re going to have to build for both extremes.
The other alternative is that Intel has monolithic versions of SPR with all 8 memory channels for lower core count designs. But at this time, Intel has not disclosed how it is going to cater to those markets.
*technically DDR5 puts two 32-bit channels on a single module, but as yet the industry doesn’t have a term to differentiate between a module with one 64-bit memory channel on it vs. a module with two 32-bit memory channels on it. The word ‘channel’ has often been interchangeable with ‘memory slot’ to date, but this will have to change.
Add In Some HBM, Optane
The other angle to Sapphire Rapids is the versions with HBM on board. Intel announced this back in June, but there haven’t been many details. As part of Architecture Day, Intel stated that that HBM versions of Sapphire Rapids would be made public, and be made socket compatible with standard Sapphire Rapids. The first customer of the HBM versions of SPR is the Argonne National Lab, as part of its Aurora Exascale supercomputer.
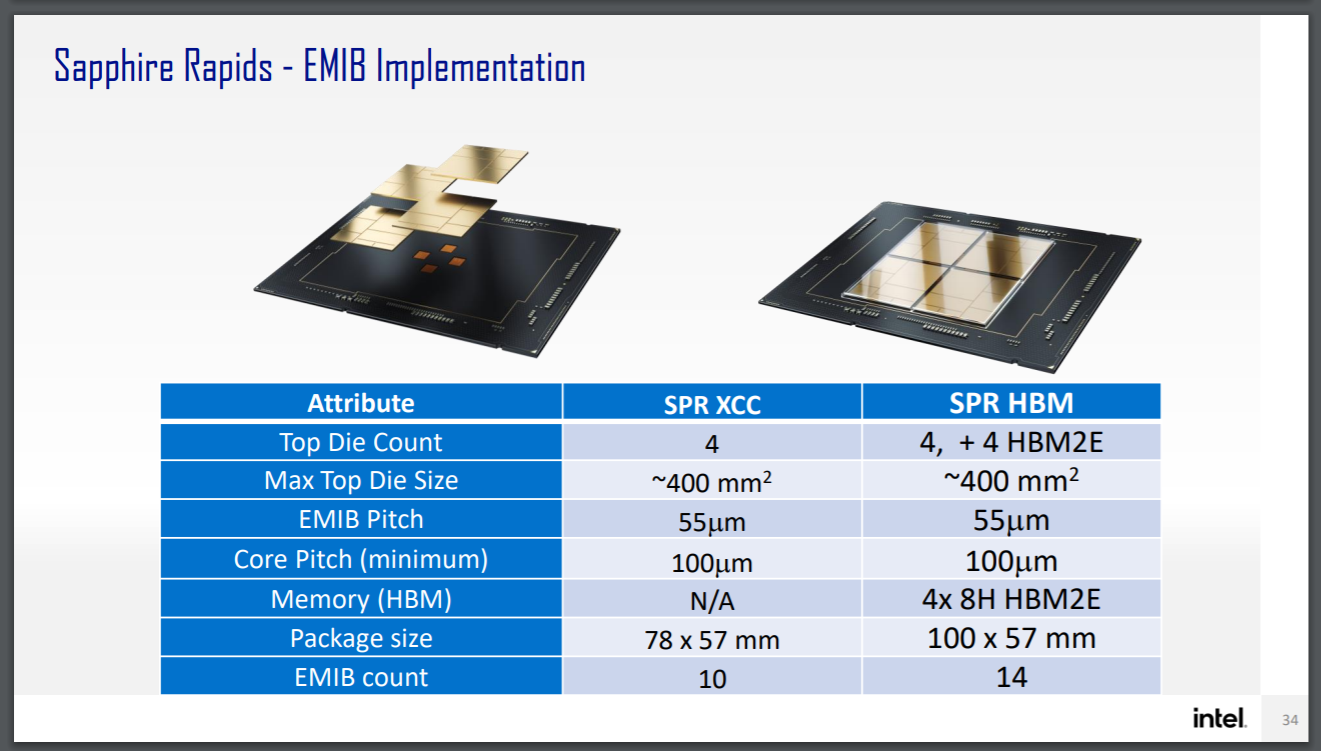
This diagram it showcases four HBM connections, one to each compute tile. Looking at the package, however, I don’t think that there’s realistically enough space unless Intel has commissioned some novel HBM that is long and narrow as it is in the diagram.

Even though Intel said that the HBM variants would be in the same socket, even their own slide from Hot Chips says different.
Here the package size with HBM says 100x57mm, compared to the SPR which is 78x57mm. So unless Intel is planning a reduced version for the 78x57mm socket, it's going to be in a different socket.
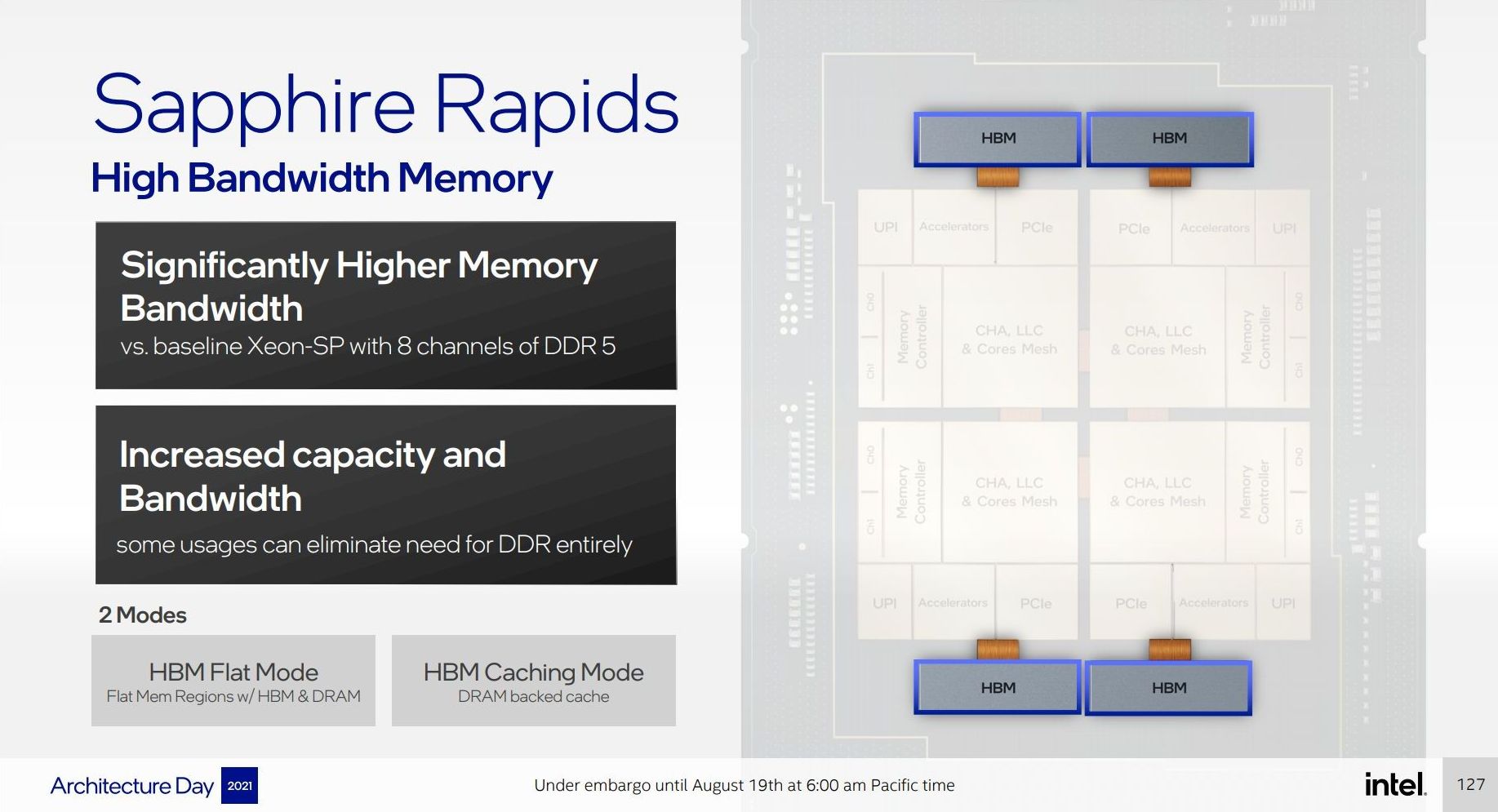
It is important to note that HBM will act in a similar capacity to Optane – either as an HBM flat mode with DRAM that equates the two, or as an HBM caching mode that acts similar to an L4 cache before hitting main memory. Optane on top of this can also be in a flat mode, a caching mode, or as a separate storage volume.
HBM will add power consumption to the package, which means we’re unlikely to see the best CPU frequencies paired with HBM if it is up against the socket limit. Intel has not announced how many HBM stacks or what capacities will be used in SPR, however it has said that they will be underneath the heatspreader. If Intel are going for a non-standard HBM size, then it’s anyone’s guess what the capacity is. But we do know that it will be connected to the tiles via EMIB.
A side note on Optane DC Persistent Memory – Sapphire Rapids will support a new 300 series Optane design. We asked Intel if this was the 200-series but using a DDR5 controller, and were told that no, this is actually a new design. More details to follow.
UPI Links
Each Sapphire Rapids Processor will have up to four x24 UPI 2.0 links to connect to other processors in a multi-socket design. With SPR, Intel is aiming for up to eight socket platforms, and in order to increase bandwidth has upgraded from three links in ICL to four (CLX had 2x3, technically), and moved to a UPI 2.0 design. Intel would not expand more on what this means, however they will have a new eight-socket UPI topology.
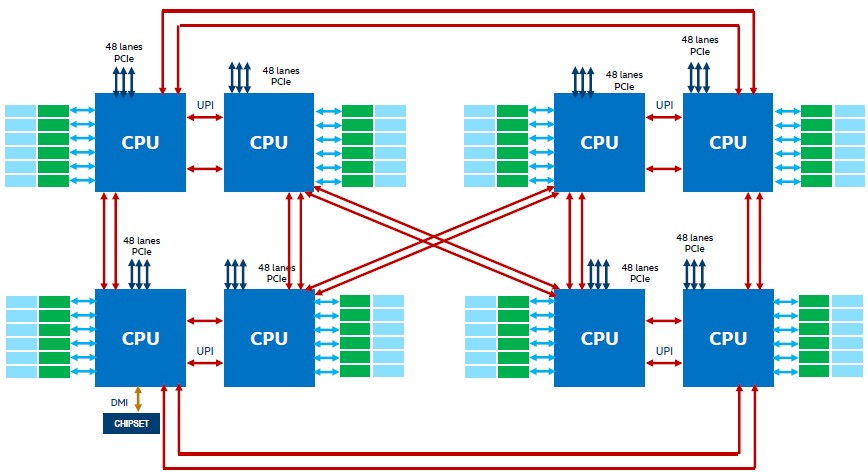
Current Intel Hypercube
Current eight-socket designs use a twisted hypercube topology: two groups of four form a box, and one pair is connected to the same vertex on the other set of four, while the second pair is inverted. Make sense? No, not really. Essentially each CPU is directly connected to three others, and the other four are two hops away. With the new topology, each CPU gets a direct connection to another, which moves the design more towards a fully connected topology, however exactly which CPU that connection should go to, Intel hasn’t stated yet.
Security
Intel has stated that it will be announcing full Security updates for SPR at a later time, however features like MKTME and SGX are key priorities.
Conclusions
For me, the improved cores, upgraded PCIe/DDR, and the ‘appears as a monolith’ approach are the highlights to date. However, there are some very obvious questions still to be answered – core counts, power consumption, how lower core counts would work (even suggestions that the LCC version is actually monolithic), and what the HBM enabled versions will look like. The HBM versions, with the added EMIB, are going to cost a good amount, which isn’t great at a time when AMD’s pricing structure is very competitive.
It is expected that when Sapphire Rapids is released, AMD will still be in the market with Milan (or as some are postulating, 3D V-Cache versions of Milan, but nothing is confirmed) and it won’t be until the end of 2022 when AMD launches Zen 4. If Intel can execute and bring SPR into the market, it will have a small time advantage in which to woo potential customers. Ice Lake is being sold on its specific accelerator advantages, rather than raw core performance, and we will have to wait and see if Sapphire Rapids can bring more to the table.
Intel moving to a tile/chiplet strategy in the enterprise has been expected for a number of years – at least on this side of the fence, ever since AMD made it work and scale beyond standard silicon limits, regardless of whatever horse-based binding agent is used between the silicon, Intel would have to go down this route. It has been delayed, mostly due to manufacturing but also optimizing things like EMIB which also takes time. EMIB as a technology is really impressive, but the more chips and bridges you put together, even if you have a 99% success rate, that cuts into yield. But that's what Intel has been working on, and for the enterprise market, Sapphire Rapids is the first step.






